ComfyUI 核心节点完整梳理
一、模型加载类
这类节点负责加载各种AI模型,是所有工作流的起点。
1. Load Checkpoint(加载大模型)节点
在 ComfyUI 中,Load Checkpoint 节点是一个非常重要的核心节点。其功能是加载 checkpoint 大模型,常用的大模型有 sd1.0、sd1.5、sd2.0、sd3.0、sdXL 等。

输入:
ckpt_name -> 自行选择在模型网站下载好的大模型(在用 WebUI 时下载了大模型的可以共享路径文件,节省磁盘空间)
输出:
MODEL -> 该模型用于对潜空间图片进行去噪
CLIP -> 该模型用于对 Prompt 进行编码
VAE -> 该模型用于对潜在空间的图像进行编码和解码
注意: StableDiffusion 大模型(checkpoint)内置有 CLIP 和 VAE 模型。另加载大型模型时,可能会耗费较长时间或占用大量内存,确保系统资源充足,避免因资源不足而导致的加载失败。
2. Load Checkpoint with config(带配置加载大模型)节点
该节点是一个高级的节点,用于加载 checkpoint 大模型并同时应用 config 文件中指定的设置。

输入:
Config_name -> 指定要加载的检查点文件的路径
Ckpt_name -> 自行选择在模型网站下载好的大模型
输出:
MODEL -> 该模型用于对潜空间图片进行去噪
CLIP -> 该模型用于对 Prompt 进行编码
VAE -> 该模型用于对潜在空间的图像进行编码和解码
注意: 确保 checkpoint 文件和 config 文件与当前使用的 ComfyUI 版本兼容。
3. Load LoRA(加载LoRA模型)节点
该节点用于加载LoRA(Low-Rank Adaptation)模型,这是一种轻量级的微调模型,可以在不改变基础大模型的情况下,为生成内容添加特定风格、人物或物体特征。
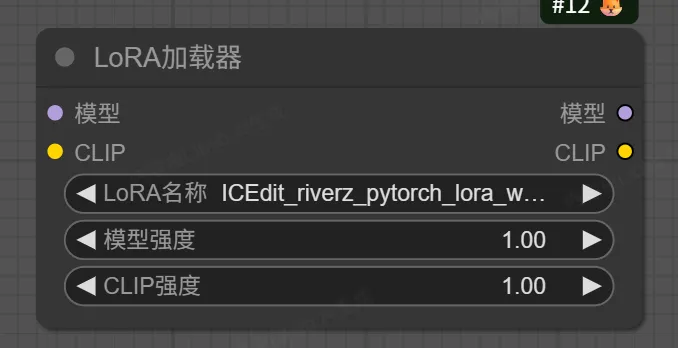
输入:
model -> 接收基础大模型
clip -> 接收CLIP模型
lora_name -> 选择要加载的LoRA模型文件
输出:
MODEL -> 应用了LoRA权重后的模型
CLIP -> 应用了LoRA权重后的CLIP模型
参数:
strength_model -> LoRA对模型的影响强度(0-1)
strength_clip -> LoRA对CLIP的影响强度(0-1)
注意: 可以串联多个Load LoRA节点来同时应用多个LoRA模型,不同LoRA的强度可以独立调整。
4. UNET Loader(单独加载UNET)节点
该节点用于单独加载UNet模型,UNet是Stable Diffusion的核心组件,负责在潜空间中进行图像去噪。
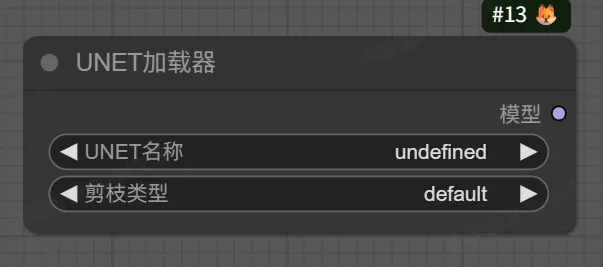
输入:
unet_name -> 选择要加载的UNet模型文件
参数:weight_dtype(控制模型权重的加载数据类型,直接影响显存占用和生成速度)
- fp32:32位浮点,精度最高但显存消耗大、速度慢
- fp16:16位半精度,最常用的平衡选项
- bf16:16位Brain浮点,适用于支持该格式的新硬件
- fp8_e4m3fn:8位浮点,特定于Flux等模型,显存占用极低,速度最快
输出:
MODEL -> 单独的UNet模型
注意: 大多数情况下使用Load Checkpoint节点即可同时加载UNet、CLIP和VAE。单独加载UNet主要用于高级工作流,如模型合并或混合使用不同组件。
5. Load ControlNet Model(加载ControlNet模型)节点
该节点用于加载ControlNet模型,ControlNet可以通过额外的条件信息(如边缘、深度、姿态等)精确控制图像生成的结构和布局。
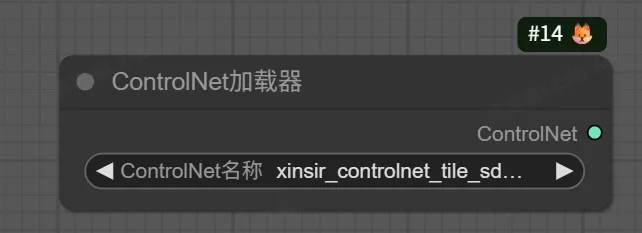
输入:
control_net_name -> 选择要加载的ControlNet模型文件
输出:
CONTROL_NET -> 加载好的ControlNet模型
常用ControlNet类型:
- Canny:基于边缘检测控制
- Depth:基于深度图控制
- OpenPose:基于人体姿态控制
- LineArt:基于线稿控制
- Segmentation:基于语义分割控制
二、文本处理类
这类节点负责处理文本提示词,将自然语言转换为模型可以理解的条件信息。
6. CLIP Set Last Layer(设置CLIP输出层)节点
对 CLIP 进行微调并调整最后一层(Set Last Layer)。该节点用来设置选择 CLIP 模型在第几层的输出数据,提高模型在目标任务上的表现。

输入:
clip -> 接收用于对 prompt 进行编码的 CLIP 模型
输出:
CLIP -> 具有新设置的输出层的 CLIP 模型。
参数:
stop_at_clip_layer -> 设置 CLIP 模型在倒数第几层进行数据输出
注意: 在 ComfyUI 中,通常使用负数来设定。-1 代表最后一层(默认值,通常用于写实模型),-2 代表倒数第二层(跳过最后一层,通常二次元/动漫类模型如 NAI 系模型需要设置为 -2,以获得更好的效果)。CLIP 模型对 prompt 进行编码的过程中,可以理解为对原始文本进行层层编码,该参数就是选择我们需要的一层编码信息,去引导模型扩散。
7. CLIP Text Encode (Prompt)(文本编码)节点
该节点用来将自然语言文本转换为模型可以理解的条件信息。

输入:
clip -> 接收用于对 prompt 进行编码的 CLIP 模型
输出:
CONDITIONING -> 将文本信息通过 CLIP 模型编码,形成引导模型扩散的条件信息
参数:
文本输入框 -> 输入需要模型生成的文本信息
注意: 节点本身不区分正负向。在实际工作流中,你需要复制并创建两个该节点,分别输入正向提示词和反向提示词,然后将它们的输出分别连接到 KSampler 采样器的 positive(正向条件)和 negative(反向条件)接口。当前 prompt 仅支持英文输入,可通过安装插件实现中文实时翻译。
三、采样生成类
这类节点是图像生成的核心,负责在潜空间中进行噪声去除和图像生成。
8. KSampler(采样器)节点
该节点专门用于逐步减少潜在空间图像中的噪声,改善图像质量和清晰度。

输入:
model -> 接收来自大模型的数据流
positive -> 接收经过 clip 编码后的正向提示词的条件信息(CONDITIONING)
negative -> 接收经过 clip 编码后的反向提示词的条件信息(CONDITIONING)
latent_image -> 接收潜空间图像信息
输出:
LATENT -> 经过 KSampler 采样器进行去噪后的潜空间图像
参数:
seed -> 在去除图像噪声过程中使用的随机数种子。种子数有限,影响噪声生成的结果
control_after_generate -> 指定种子生成后的控制方式
fixed 代表固定种子,保持不变
increment 代表每次增加 1
decrement 代表每次减少 1
randomize 代表随机选择种子
steps -> 对潜在空间图像进行去噪的步数。步数越多,去除噪声的效果可能越显著
cfg -> 提示词引导系数,表示提示词对最终结果的影响程度。过高的值可能会产生不良影响。
sampler_name -> 选择的采样器名称,不同的采样器类型可以影响生成图像的效果,大家可以根据需求进行选择和实验
scheduler -> 选择的调度器名称,影响生成过程中的采样和控制策略,推荐配置可提供更好的结果
denoise -> 去噪或重绘的幅度,数值越大,图像变化和影响越显著。在高清修复等任务中,通常使用较小的值以保持图像细节和质量
9. Empty Latent image(空白潜空间图像)节点
该节点用来控制纯噪声的潜空间图像及比例。

输出:
LATENT -> 输出指定形状和数量的潜空间图像
参数:
width -> 要生成潜空间图像的宽度
height -> 要生成潜空间图像的高度
batch_size -> 需要生成多少张潜空间图像
注意: 不同架构的模型有其对应的最佳基础分辨率(由模型训练时的数据集尺寸决定):
- SD 1.5 及衍生模型:最佳尺寸通常为 512*512 或 512*768
- SD 2.1 模型:最佳尺寸通常为 768*768
- SDXL 及 SD 3.0 模型:最佳尺寸通常为 1024*1024
偏离最佳分辨率太多可能会导致生成画面出现多头、多手或结构崩坏。
四、VAE编解码类
这类节点负责在像素空间和潜空间之间进行图像转换。
10. VAE Encode(VAE编码)节点
该节点用于将像素级图像编码为潜空间表示,是图生图流程的关键节点。
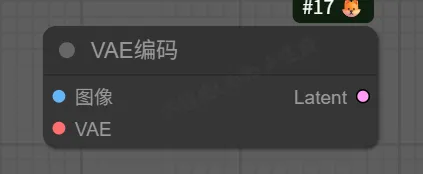
输入:
pixels -> 接收像素级图像
vae -> 接收VAE模型
输出:
LATENT -> 编码后的潜空间图像
注意: 与VAE Decode节点相反,VAE Encode将图像从像素空间转换到潜空间,以便后续进行去噪处理。
11. VAE Encode(for inpainting)(修复专用VAE编码)节点
该节点可以有效地对指定 VAE 模型对图像进行编码解码,从而为后续提供高质量的输入数据。

输入:
pixels -> 接收输入的图像信息
vae -> 接收输入的 vae 模型,使用该模型进行图片编码
mask -> 接收蒙版信息,用来确定扩散的区域
参数:
grow_mask_by -> 控制蒙版的羽化区域,和 Pad Image for Outpainting 节点的 feathering 参数相似
输出:
LATENT -> 编码后的潜空间图像信息
12. VAE Decode(VAE解码)节点
该节点用来将潜空间图像解码到像素级的图像。

输入:
samples -> 接收经过 KSampler 采样器处理后的潜在空间图像, 用于后续的处理或展示
vae -> 接收用于解码潜在空间图像的 VAE 模型, 大部分情况下,模型的检查点(checkpoint)会包含 VAE,当然也可以单独加载一个 VAE 模型
输出:
IMAGE -> 输出经过 VAE 解码后可直接查看的图像
13. VAE Decode(Tiled)(分块VAE解码)节点
该节点用于对变分自编码器(VAE)进行解码操作,以将潜在空间(latent space)中的表示转换回图像。

输入:
Samples -> 接收 KSampler 采样器处理后的潜空间图像
vae -> 接收对潜空间图像解码使用的 vae 模型
输出:
IMAGE -> 输出经过 vae 解码后可直接查看的图像
参数:
tile_size -> 用来设定”块”的大小,进行多块处理
Tips: 这个节点特别适合处理高分辨率图像,因为将图像分成小块进行处理,然后在处理完所有块后将它们组合成完整图像,可以避免内存溢出,并且提高处理效率。
五、ControlNet类
这类节点用于实现精确的图像结构控制,是ComfyUI最强大的功能之一。
14. Apply ControlNet(应用ControlNet)节点
该节点用于将 ControlNet 模型应用到生成过程中,将控制条件与提示词条件结合,是实现精确图像结构控制的核心节点。
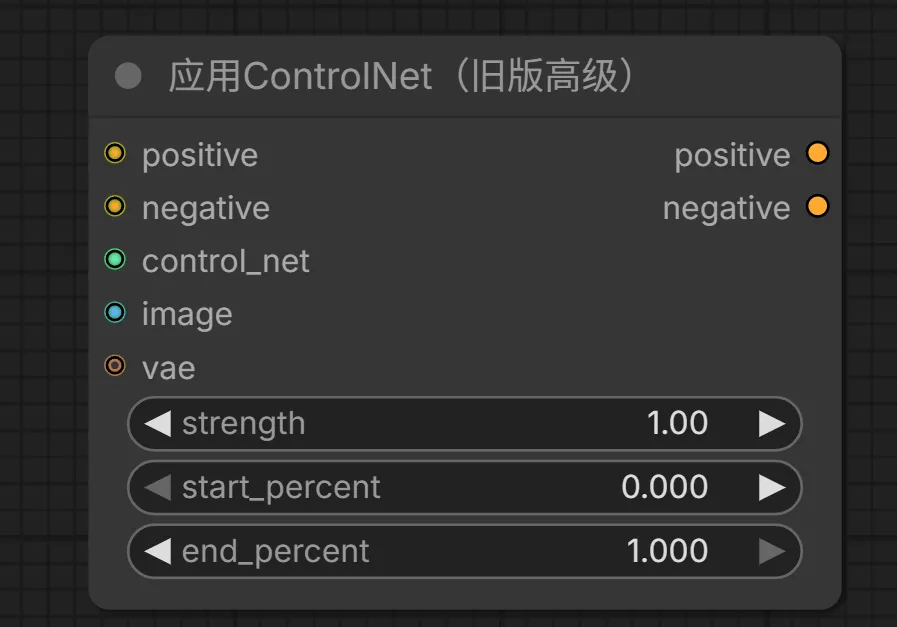
输入:
positive -> 接收来自 CLIP Text Encode 的正向提示词条件
negative -> 接收来自 CLIP Text Encode 的反向提示词条件
control_net -> 接收来自 Load ControlNet Model 的 ControlNet 模型
image -> 接收用于控制的参考图像(如边缘图、深度图等经预处理器处理过的图像)
输出:
CONDITIONING -> 融合了 ControlNet 控制信息的正向条件信息
CONDITIONING -> 融合了 ControlNet 控制信息的反向条件信息
参数:
strength -> ControlNet 的控制强度(0.0-1.0)
start_percent -> ControlNet 开始生效的步数百分比(0.0-1.0)
end_percent -> ControlNet 结束生效的步数百分比(0.0-1.0)
注意: 可以串联多个 Apply ControlNet 节点来同时使用多个 ControlNet 模型,实现多条件控制。旧版本中只有 strength 参数的基础节点现在已被重命名为 "Apply ControlNet (OLD)"。
15. Canny Edge Detection(Canny边缘检测)节点
该节点用于检测图像的边缘,生成边缘图,作为Canny ControlNet的输入。
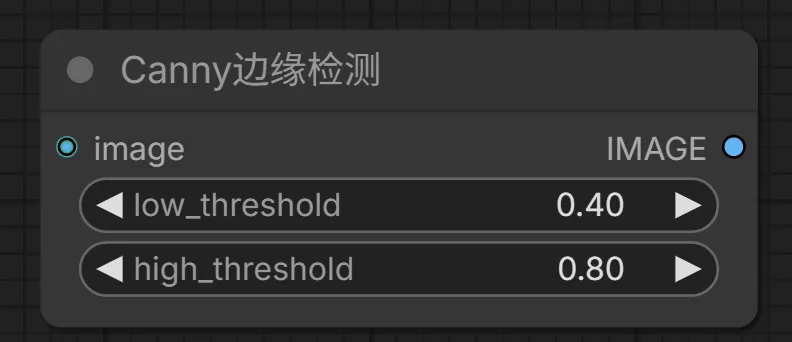
输入:
image -> 接收原始图像
输出:
IMAGE -> 生成的边缘图
参数:
low_threshold -> 边缘检测的低阈值
high_threshold -> 边缘检测的高阈值
六、图像处理类
这类节点用于对图像进行各种预处理和后处理操作。
16. Load Image(加载图像)节点
该节点的主要功能是从你的计算机或其他存储设备中加载图像文件,并将其引入到 ComfyUI 的工作流程中。

输入:
upload -> 点击该按钮,去选择想要加载的图像
输出:
IMAGE -> 加载的图像可以作为输入提供给其他节点,以进行进一步的图像处理或操作
MASK -> 如果图像中带有 Alpha 通道信息,则会通过该节点进行输出
右键点击节点,会有一个功能栏,许多的功能可以在搭建工作流时会有不错的效果:
- 图像编辑: 加载图像进行剪裁、调整颜色、添加滤镜等操作。
- 图像分析: 使用加载的图像进行特征提取、模式识别等分析任务。
- 图像生成: 在生成新图像时,将现有图像作为参考或素材进行处理。
17. Save Image(保存图像)节点
该节点用来保存 image 图像。

输入:
images -> 保存图像
Tips: 一般保存的图像会在你的 ComfyUI 文件夹中(eg:安装盘:\Comfyui\ComfyUI\output)。
18. Preview image(图像预览)节点
该节点用来预览 image 图像。

如果觉得图像是想要的效果,也可以右键节点选择“Save Image”进行图像保存,或者也可以建立一个“Save Image”节点,直接保存,保存地址同上。
19. Invert Image(图像反色)节点
该节点用于反转图像的颜色。具体来说,它将图像中的每个像素的颜色值转换为其补色。

输入:
image -> 加载想要处理的图片
输出:
IMAGE -> 输出反转图像
反转图像颜色在图像处理和特效制作中有多种应用,包括但不限于以下几种:
- 视觉效果:反转图像颜色可以产生独特的视觉效果,增加图像的艺术感。
- 增强对比度:在某些情况下,反转图像颜色可以帮助突出某些细节或对比。
- 创建掩膜:反转图像颜色可以用于创建和处理掩膜(masks),以便在进一步的图像处理步骤中使用。
20. Pad Image for Outpainting(扩图填充)节点
该节点的主要目的是预处理输入图像,以便于后续的绘制或者生成任务。

输入:
image -> 接收加载的图像信息
参数:
left -> 设定图像左侧扩展的像素宽度
top -> 设定图像顶部扩展的像素宽度
right -> 设定图像右侧扩展的像素宽度
bottom -> 设定图像底部扩展的像素宽度
feathering -> 控制边框的柔化程度,使得填充的边缘与原始图像更自然地过渡
输出:
IMAGE -> 输出扩展后的图像信息
MASK -> 输出扩展部分对应的蒙版,并且结合 feathering 参数进行柔化处理。
21. Upscale image(图像放大)节点
该节点用于放大图像的尺寸,同时尽可能保持图像的细节和质量。

输入:
image -> 接收需要调整的图像
参数:
upscale_method -> 选择放大图像的算法,“nearest-exact”表示使用最近邻插值算法。
width -> 调整后的图像宽度
height -> 调整后的图像高度
crop -> 设置是否对放大后的图像进行裁剪 “disabled 表示不裁剪,center 表示从中心对图片裁剪”
输出:
IMAGE -> 输出调整之后的图像
注意: 比例需根据自身需求调整,上图的比例设置只为更好的展示节点效果。
七、条件与模型操作类
这类节点用于对条件信息和模型进行各种操作和组合。
22. Conditioning Combine(条件合并)节点
该节点用于合并多个条件信息,常用于同时使用多个提示词或多个ControlNet的场景。
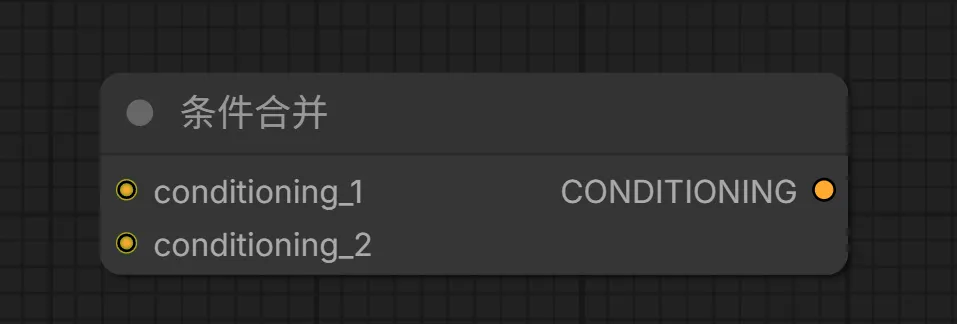
输入:
conditioning_1 -> 第一个条件信息
conditioning_2 -> 第二个条件信息
输出:
CONDITIONING -> 合并后的条件信息
23. Model Merge Simple(简易模型合并)节点
该节点用于合并两个模型,创建具有不同特征的混合大模型(Checkpoint)。
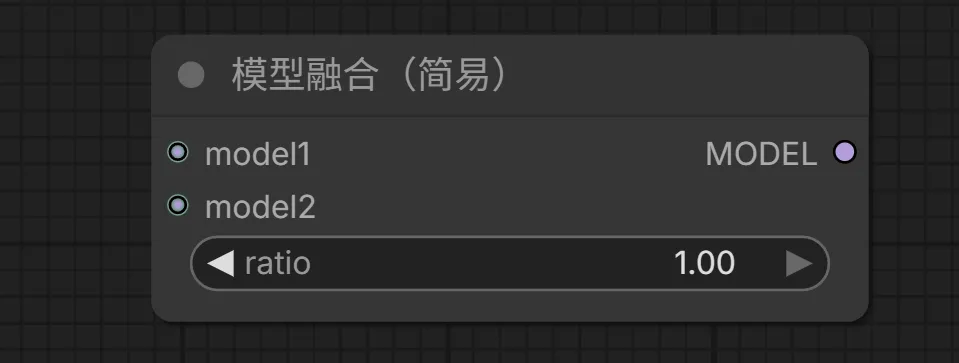
输入:
model1 -> 第一个基础模型
model2 -> 第二个基础模型
输出:
MODEL -> 合并后的新模型
参数:
ratio -> 决定融合的权重比例(0.0-1.0)。如果值为 1.0,则完全使用 model2 的权重;如果值为 0.0,则完全使用 model1 的权重。
注意: 如果需要合并三个及以上的模型,需要创建多个该节点进行串接操作(即前两个模型合并的输出 MODEL 作为下一个节点的 model1 输入)。
24. Latent Upscale(潜空间放大)节点
该节点用于在潜空间中放大图像,相比直接放大像素图像,潜空间放大可以更好地保留细节并减少伪影。
输入:
samples -> 接收潜空间图像
输出:
LATENT -> 放大后的潜空间图像
参数:
upscale_method -> 选择放大算法
scale -> 放大倍数
width -> 目标宽度(与scale二选一)
height -> 目标高度(与scale二选一)
crop -> 是否裁剪图像以匹配目标尺寸
八、完整工作流示例
通过组合以上节点,我们可以搭建出各种实用的AI图像生成工作流。
25. 文生图示例工作流
熟悉以上所有节点之后,你就可以搭建第一个“文生图”工作流了。

这里使用了 sd1.5 的大模型,所以 latent 图像设置 512*512,正向提示词输入 1 girl,反向提示词输入 NSFW 避免出现不能播的内容,采样器 KSampler 使用默认设置,最终出图如下:

26. 图生图示例工作流
熟练使用以上节点,你就可以搭建第一个“图生图”工作流了。

可以看到,在整个图生图工作流中,这里使用了 SDXL 的大模型,上传一张原始底图,经过 VAE Encoder 节点对底图编码,后续通过提示词引导使用 KSampler 采样器进行去噪,最终出图如下:

核心节点分类总结
以上26个节点覆盖了ComfyUI中90%以上的基础和进阶使用场景,掌握它们就可以搭建出绝大多数类型的工作流。按照功能可以分为以下几大类:
- 模型加载类:Load Checkpoint、Load Checkpoint with config、Load LoRA、UNET Loader、Load ControlNet Model
- 文本处理类:CLIP Set Last Layer、CLIP Text Encode (Prompt)
- 采样生成类:KSampler、Empty Latent image
- VAE编解码类:VAE Encode、VAE Encode(for inpainting)、VAE Decode、VAE Decode(Tiled)
- ControlNet类:Apply ControlNet、Canny Edge Detection(及其他预处理节点)
- 图像处理类:Load Image、Save Image、Preview Image、Invert Image、Pad Image for Outpainting、Upscale image
- 条件与模型操作类:Conditioning Combine、Model Merge Simple、Latent Upscale
这些节点可以组合出文生图、图生图、局部重绘、图像扩展、高清修复、多ControlNet控制等各种复杂的AI图像生成工作流。
