CLIP文本编码SDXL-ComfyUI节点
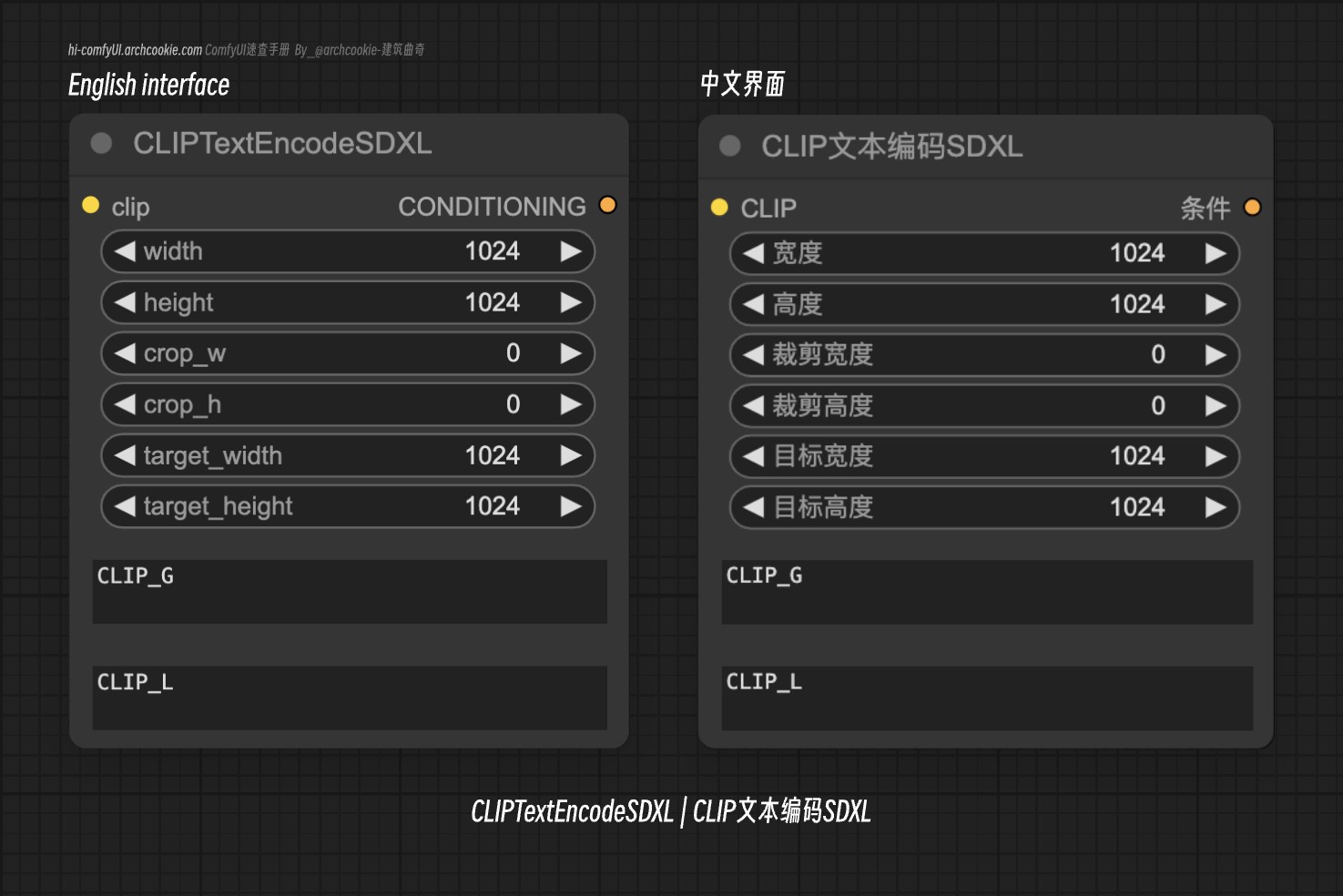
CLIP文本编码SDXL-节点描述
- 类名:CLIPTextEncodeSDXL
- 分类:高级/条件
- 输出节点:False 此节点设计使用特别为SDXL架构定制的CLIP模型对文本输入进行编码。它专注于将文本描述转换为可以有效地用于生成或操作图像的格式,利用CLIP模型理解和处理视觉内容上下文中的文本的能力。
CLIP文本编码SDXL-输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
CLIP | CLIP | 用于编码文本的CLIP模型实例。它在处理文本输入和将其转换为适合图像生成或操作任务的格式中起着至关重要的作用。 |
宽度 | INT | 指定图像的宽度(以像素为单位)。它决定了生成或操作的输出图像的尺寸。 |
高度 | INT | 指定图像的高度(以像素为单位)。它决定了生成或操作的输出图像的尺寸。 |
裁剪宽度 | INT | 定义裁剪区域的宽度(以像素为单位)。此参数用于在处理之前将图像裁剪到特定的宽度。 |
裁剪高度 | INT | 定义裁剪区域的高度(以像素为单位)。此参数用于在处理之前将图像裁剪到特定的高度。 |
目标宽度 | INT | 处理后的输出图像的目标宽度。它允许将图像调整到所需的宽度。 |
目标高度 | INT | 处理后的输出图像的目标高度。它允许将图像调整到所需的高度。 |
CLIP_G | STRING | 要编码的全局文本描述。此输入对于生成相应的视觉表示和理解所描述的内容至关重要。 |
CLIP_L | STRING | 要编码的局部文本描述。此输入为全局描述提供额外的细节或上下文,增强了生成或操作的图像的特异性。 |
CLIP文本编码SDXL-输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
条件 | CONDITIONING | 节点的输出,包括编码后的文本以及图像生成或操作任务所需的其他信息。 |
CLIP文本编码SDXL(Refiner)-ComfyUI节点
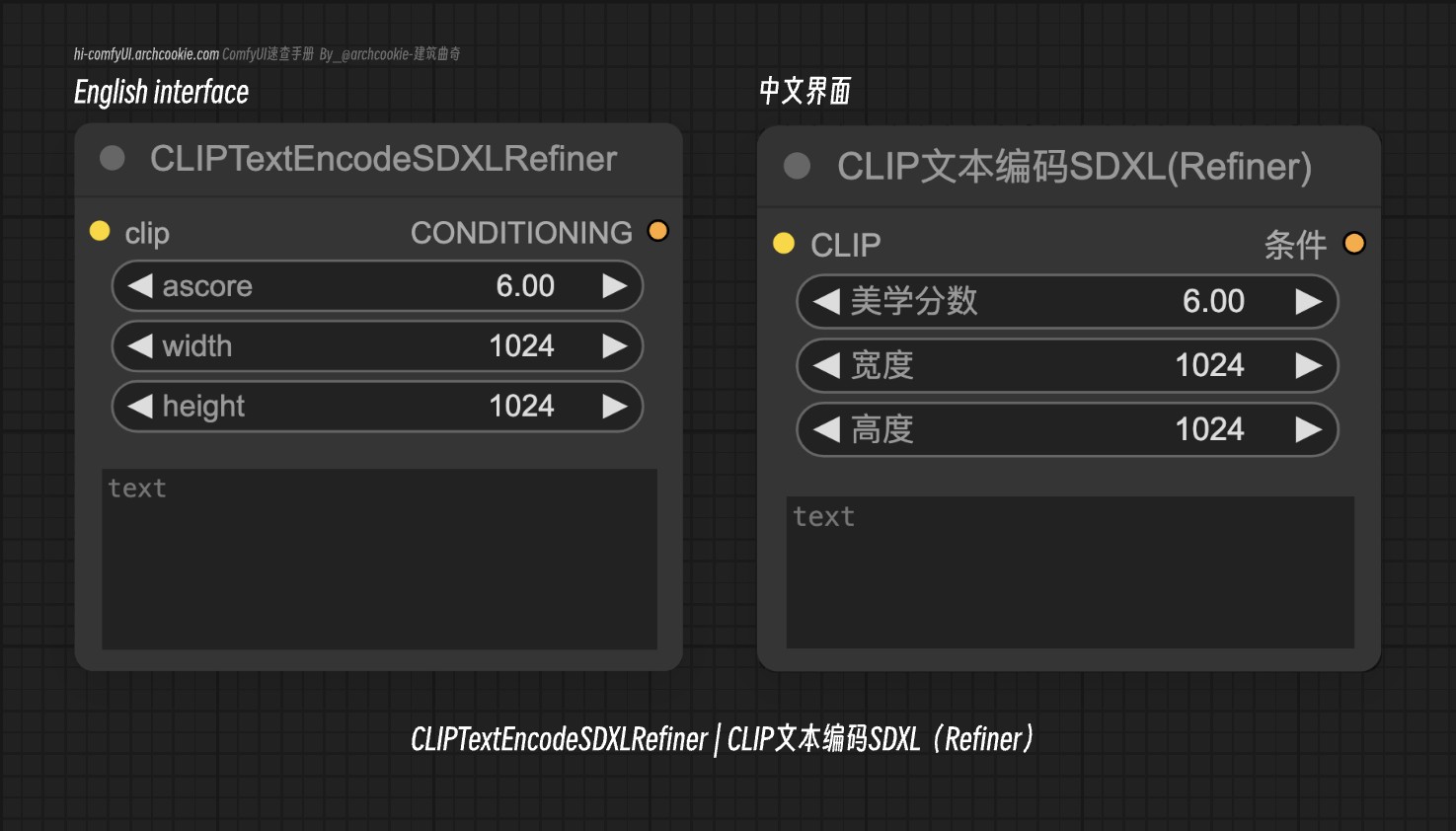
CLIP文本编码SDXL(Refiner)文档
- 节点名称:
CLIPTextEncodeSDXLRefiner - 分类:
高级/条件 - 输出节点:
False此节点专门使用CLIP模型细化文本输入的编码,通过纳入审美得分和维度来增强生成任务的条件,从而提升条件输出。
CLIP文本编码SDXL(Refiner)输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
CLIP | CLIP | 用于文本标记化和编码的CLIP模型实例,对生成条件至关重要。 |
美学分数 | FLOAT | 审美得分参数通过提供审美质量的度量来影响条件输出。 |
宽度 | INT | 指定输出条件的宽度,影响生成内容的尺寸。 |
高度 | INT | 确定输出条件的高度,影响生成内容的尺寸。 |
text | STRING | 要编码的文本输入,作为条件的主要内容描述符。 |
CLIP文本编码SDXL(Refiner)输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
条件 | CONDITIONING | 经过细化的条件输出,加入了审美得分和维度,以增强内容生成。 |
CLIP Text Encode Hunyuan DiT CLIP文本编码混元
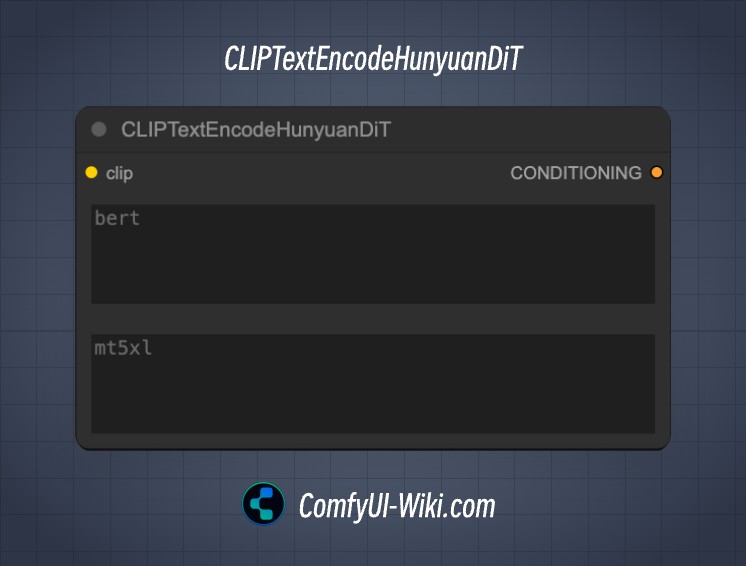
CLIP Text Encode Hunyuan DiT ComfyUI 节点功能概述
CLIPTextEncodeHunyuanDiT 节点的主要功能是:
- 标记化:将输入的文本转换为模型可处理的标记序列。
- 编码:使用 CLIP 模型对标记序列进行编码,生成条件编码。
可以将该节点视为一个“语言翻译器”,它将用户输入的文本(无论是英文还是其他语言)翻译成 AI 模型能够理解的“机器语言”,从而使模型能够根据这些条件生成相应的内容。
类名
- 类名:
CLIPTextEncodeHunyuanDiT - 类别:
advanced/conditioning - 输出节点:
False
CLIP Text Encode Hunyuan DiT 输入类型
| 参数 | Comfy 数据类型 | 描述 |
|---|---|---|
clip | CLIP | 一个 CLIP 模型实例,用于文本的标记化和编码,是生成条件的核心。 |
bert | STRING | 需要编码的文本输入,支持多行和动态提示。 |
mt5xl | STRING | 另一个需要编码的文本输入,支持多行和动态提示(多语言)。 |
bert参数:适用于英文文本输入,建议输入简洁且具有上下文的文本提示,以帮助节点生成更准确和有意义的标记表示。mt5xl参数:适用于多语言文本输入,您可以输入任何语言的文本,帮助模型理解多种语言的任务。
CLIP Text Encode Hunyuan DiT 输出类型
| 参数 | Comfy 数据类型 | 描述 |
|---|---|---|
conditioning | CONDITIONING | 编码后的条件输出,用于生成任务中的进一步处理。 |
方法
-
编码方法:
encode该方法接受
clip、bert和mt5xl作为参数。首先,它对bert进行标记化,然后对mt5xl进行标记化,并将结果存储在tokens字典中。最后,它使用clip.encode_from_tokens_scheduled方法将标记化的 tokens 编码为条件。
使用示例
- 待更新
CLIP Text Encode Hunyuan DiT 节点的相关内容扩展
BERT(Bidirectional Encoder Representations from Transformers)
BERT 是一种基于 Transformer 架构的双向语言表示模型。
它通过对大量文本数据的预训练,学习到丰富的上下文信息,然后在下游任务上进行微调,实现高性能。
主要特点:
-
双向性:BERT 同时考虑文本的左右上下文信息,能够更好地理解词语的含义。
-
预训练与微调:通过预训练任务(如 Masked Language Model 和 Next Sentence Prediction),BERT 可以在多种下游任务上进行快速微调。
应用场景:
-
文本分类
-
命名实体识别
-
问答系统
mT5-XL(Multilingual Text-to-Text Transfer Transformer)
mT5-XL 是 T5 模型的多语言版本,采用编码器-解码器架构,支持多种语言的处理。
它将所有的 NLP 任务统一表示为文本到文本的转换,能够处理包括翻译、摘要、问答等多种任务。
主要特点:
-
多语言支持:mT5-XL 支持多达 101 种语言的处理。
-
统一任务表示:将所有任务转换为文本到文本的形式,简化了任务的处理流程。
应用场景:
-
机器翻译
-
文本摘要
-
问答系统
BERT 和 mT5-XL 相关研究论文
-
BERT: 用于语言理解的深度双向 Transformer 预训练
- 描述: 这篇开创性论文介绍了 BERT,一个基于 transformer 的模型,在广泛的自然语言处理任务中都达到了最先进的效果。
-
mT5: 大规模多语言预训练的文本到文本 Transformer
- 描述: 这篇论文介绍了 mT5,T5 的多语言变体,它在一个覆盖 101 种语言的新 Common Crawl 数据集上进行训练。
-
mLongT5: 一个用于处理更长序列的多语言高效文本到文本 Transformer
- 描述: 这项工作开发了 mLongT5,一个专门设计用于高效处理更长输入序列的多语言模型。
-
跨越语言障碍:深入了解 Google 的 mT5 多语言技术
- 描述: 一篇讨论 Google 的 mT5 模型在多语言自然语言处理任务中的能力和应用的文章。
-
- 描述: 一个精选的 BERT 相关研究论文列表,包括调查、下游任务和改进方案。
源码
- ComfyUI 版本: v0.3.10
- 2025-01-07
Conditinoin Set Timstep Range|设置条件时间-ComfyUI节点
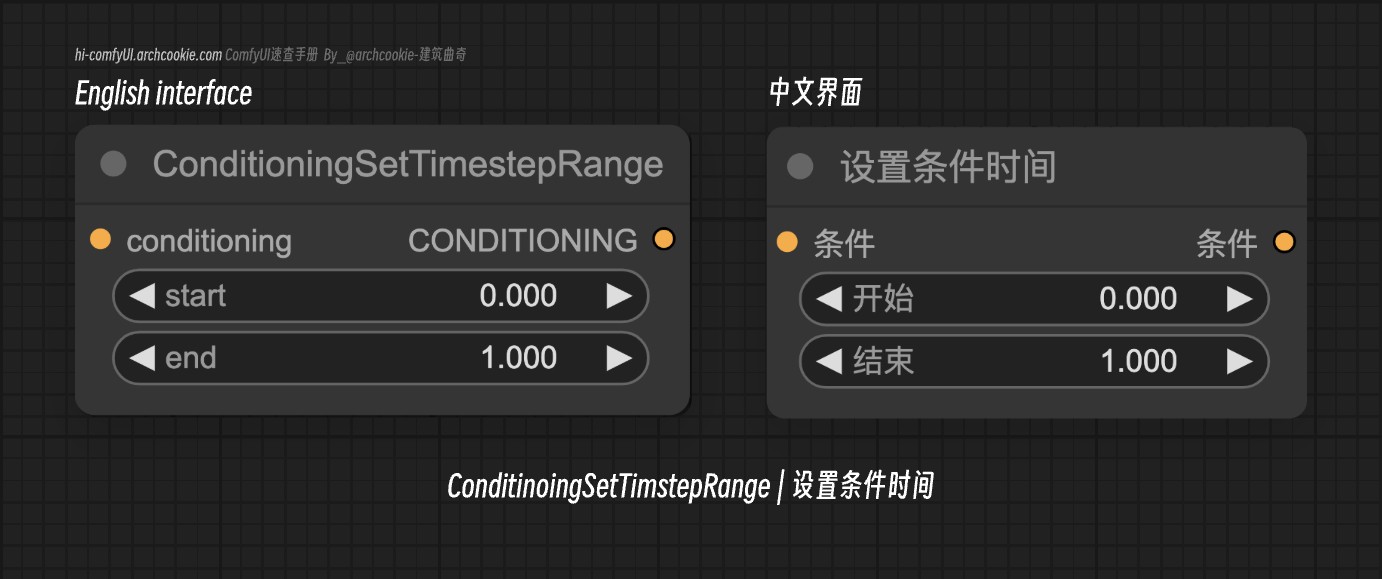
节点介绍
- 节点名称:
ConditioningSetTimestepRange - 分类:
advanced/conditioning - 输出节点:
False
此节点设计用于通过设置特定时间步范围来调整条件的时序方面。它允许对条件过程的起始和结束点进行精确控制,从而实现更有针对性的高效生成。
设置条件时间输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
条件 | CONDITIONING | 条件输入代表生成过程的当前状态,此节点通过设置特定时间步范围来修改它。 |
开始 | FLOAT | start参数指定时间步范围的起始点,作为总生成过程的百分比,允许对条件效果开始的时间进行微调控制。 |
结束 | FLOAT | end参数定义时间步范围的终点作为百分比,使您能够精确控制条件效果的持续时间和结束。 |
设置条件时间输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
条件 | CONDITIONING | 输出是应用了指定时间步范围的修改后条件,已准备好进行进一步的处理或生成。 |
Conditioning Zero Out|条件零化-ComfyUI节点

Documentation
- 节点名称:
ConditioningZeroOut - 分类目录:
advanced/conditioning - 输出节点:
False
此节点设计用于将条件数据结构中的特定元素置零,有效中和它们在后续处理步骤中的影响。它适用于需要直接操作条件内部表示的高级条件操作。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
条件 | CONDITIONING | 要被修改的条件数据结构。如果存在,此节点将每个条件条目内的’pooled_output’元素置零。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
条件 | CONDITIONING | 修改后的条件数据结构,其中适用的’pooled_output’元素已被设置为零。 |
CLIPTextEncodeFlux- ComfyUI节点
这个节点名为 CLIPTextEncodeFlux,它的主要作用是对文本进行编码,并生成用于条件控制的数据。
节点功能说明
文本编码:使用 CLIP 模型对 clip_l 输入的文本进行编码,捕获文本中的关键特征和语义信息。 增强文本理解:利用 T5XXL 大型语言模型对 t5xxl 输入进行处理,可能用于扩展或细化文本描述,提供更丰富的语义信息。 多模态融合:将 CLIP 和 T5XXL 的处理结果结合,创建一个更全面的文本表示。 生成控制:通过 guidance 参数调整文本提示对图像生成的影响程度,允许用户在创意自由度和严格遵循提示之间找到平衡。 条件数据生成:输出经过处理的条件数据,这些数据将在后续的图像生成过程中使用,确保生成的图像与文本描述相匹配。
输入参数表格
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
| clip | CLIP | CLIP 模型对象输入,用于文本编码和处理,通常与 DualCLIPLoader 一起使用 |
| clip_l | STRING | 多行文本输入,输入类似标签 tag 信息的文本,用于 CLIP 模型进行编码 |
| t5xxl | STRING | 多行文本输入,输入自然语言提示词描述,用于 T5XXL 模型进行编码 |
| guidance | FLOAT | 浮点数值,用于指导生成过程,数值越大图像与提示词的匹配度越高但生成的内容可能会缺乏一定创意 |
输出参数表格
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
| CONDITIONING | 条件 | 包含条件数据(cond),用于后续的条件生成任务 |
使用提示
-
虽然 clip_l 和 t5xxl 在使用上一个输入标签一个输入自然语言,但在实际使用中大家可能为了效果会输入同样的文本提示词 你可以在实际使用中输入不同的内容来对比测试效果,比如在 clip_l 中输入类似
Illustration style, film and television style这样的标签,而在 t5xxl 中输入A fantasy scene with a dragon and a unicorn这样自然语言看看如何能得到更好的效果。 -
对于比较简短的提示词和要求,将 guidance 设置为 4 是一个不错的选择,但如果你的提示内容比较长或者想要更富有创意的内容,可以将 guidance 设置为 1.0~1.5 之间可能是个不错的选择
FluxGuidance - ComfyUI 节点功能说明
输入参数
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
| conditioning | CONDITIONING | 输入的条件控制数据,通常来自之前的编码或处理步骤 |
| guidance | FLOAT | 控制文本提示对图像生成的影响程度,可调节范围为 0.0 到 100.0 |
输出参数
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
| CONDITIONING | CONDITIONING | 更新后的条件控制数据,包含新的 guidance 值 |
使用建议
对于比较简短的提示词和要求,将 guidance 设置为 4 是一个不错的选择,但如果你的提示内容比较长或者想要更富有创意的内容,可以将 guidance 设置为 1.0~1.5 之间可能是个不错的选择。
取值越大时,图像与提示词的匹配度越高但生成的内容可能会缺乏一定创意。 取值越小时,图像与提示词的匹配度越低,生成的内容可能更富有创意。
CLIP加载器 -ComfyUI节点
CLIP加载器-文档说明
- 类名:
CLIPLoader - 类别:
高级/加载器 - 输出节点:
否
CLIPLoader 节点旨在加载 CLIP 模型,支持稳定扩散(stable diffusion)和稳定级联(stable cascade)等不同类型的模型。它抽象了加载和配置 CLIP 模型的复杂性,以便在各种应用中使用,并提供了一种简化的方式来访问具有特定配置的这些模型。
CLIP加载器-输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
CLIP名称 | COMBO[STRING] | 指定要加载的 CLIP 模型的名称。此名称用于在预定义的目录结构内定位模型文件。 |
type | COMBO[STRING] | 确定要加载的 CLIP 模型类型,提供 ‘stable_diffusion’ 和 ‘stable_cascade’ 之间的选择。这影响模型的初始化和配置方式。 |
CLIP加载器-输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
CLIP | CLIP | 加载的 CLIP 模型,准备用于下游任务或进一步处理。 |
Load Checkpoint With Config (DEPRECATED)
.jpg)
文档说明
- 类名:
CheckpointLoader - 类别:
高级/加载器 - 输出节点:
否
CheckpointLoader 节点旨在进行高级加载操作,特别是加载模型检查点及其配置。它方便检索初始化和运行生成模型所需的模型组件,包括来自指定目录的配置和检查点。
输入类型
| 参数名称 | 数据类型 | 描述 |
|---|---|---|
config_name | COMBO[STRING] | 指定要使用的配置文件的名称。这对于确定模型的参数和设置至关重要,会影响模型的行为和性能。 |
ckpt_name | COMBO[STRING] | 指示要加载的检查点文件的名称。这直接影响初始化的模型状态,影响其初始权重和偏差。 |
输出类型
| 参数名称 | 数据类型 | 描述 |
|---|---|---|
model | MODEL | 表示从检查点加载的主要模型,准备进行进一步操作或推理。 |
clip | CLIP | 如果可用并被请求,提供从检查点加载的 CLIP 模型组件。 |
vae | VAE | 如果可用并被请求,提供从检查点加载的 VAE 模型组件。 |
Diffuser Loader|扩散加载器-ComfyUI节点

文档说明
- 类名:
DiffusersLoader - 类别:
高级/加载器/已弃用 - 输出节点:
否
DiffusersLoader 节点旨在从 diffusers 库加载模型,特别处理基于提供的模型路径加载 UNet、CLIP 和 VAE 模型。它促进了这些模型与 ComfyUI 框架的集成,使得能够实现文本到图像生成、图像操作等高级功能。
输入类型
| 参数名称 | 数据类型 | 描述 |
|---|---|---|
model_path | COMBO[STRING] | 指定要加载的模型的路径。该路径至关重要,因为它决定了后续操作将使用哪个模型,影响节点的输出和功能。 |
输出类型
| 参数名称 | 数据类型 | 描述 |
|---|---|---|
model | MODEL | 加载的 UNet 模型,是输出元组的一部分。此模型对于 ComfyUI 框架内的图像合成和操作任务至关重要。 |
clip | CLIP | 加载的 CLIP 模型,如果被请求则包含在输出元组中。此模型能够实现高级文本和图像理解及操作功能。 |
vae | VAE | 加载的 VAE 模型,如果被请求则包含在输出元组中。此模型对于涉及潜在空间操作和图像生成的任务至关重要。 |
Dual CLIP Loader|双CLIP加载器-ComfyUI节点
文档说明 - 双 CLIP 加载器 | Dual CLIP Loader
- 类名:
DualCLIPLoader - 类别:
高级/加载器 - 输出节点:
否
DualCLIPLoader 节点旨在同时加载两个 CLIP 模型,便于执行需要整合或比较这两个模型特征的操作。
想象你在厨房里准备一道菜,你有两个不同的调料瓶——一个是盐,一个是胡椒。每种调料瓶都能为菜肴增添不同的风味。现在,你有一个特别的工具,可以同时使用这两个调料瓶来调味。这就像是DualCLIPLoader节点,它可以同时加载两个不同的CLIP模型,让你能够在生成艺术作品时结合不同的风格或功能,从而实现更丰富和灵活的创作。
下载 ComfyUI flux_text_encoders clip 模型
ComfyUI flux_text_encoders 在 hugging face 上
| 模型文件名 | 文件大小 | 备注 | 链接 |
|---|---|---|---|
clip_l.safetensors | 246 MB | 下载 | |
t5xxl_fp8_e4m3fn.safetensors (推荐) | 4.89 GB | 低内存使用(8-12GB) | 下载 |
t5xxl_fp16.safetensors | 9.79 GB | 如果你有高显存和内存(超过32GB内存),则可以获得更好的结果。 | 下载 |
- 下载 clip_l.safetensors
- 根据你的显存和内存情况,下载 t5xxl_fp8_e4m3fn.safetensors 或 t5xxl_fp16.safetensors
- 将下载的模型文件放置在
ComfyUI/models/clip/文件夹中
注意:如果你之前使用过 SD 3 Medium,你可能已经拥有上述两个模型
输入类型 - 双 CLIP 加载器 | Dual CLIP Loader
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip_name1 | COMBO[STRING] | 指定要加载的第一个 CLIP 模型的名称。此参数对于从预定义的可用 CLIP 模型列表中识别和检索正确的模型至关重要。 |
clip_name2 | COMBO[STRING] | 指定要加载的第二个 CLIP 模型的名称。此参数允许加载第二个不同的 CLIP 模型,以便与第一个模型一起进行比较或整合分析。 |
type | 选项 | 从”sdxl”, “sd3”, “flux”中选择一个,用来适应不同模型下的工作流 |
- 加载的顺序不会影响输出效果
输出类型 - 双 CLIP 加载器 | Dual CLIP Loader
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip | CLIP | 输出是一个整合了两个指定 CLIP 模型特征或功能的组合 CLIP 模型。 |
工作流示例 - 双 CLIP 加载器 | Dual CLIP Loader
此工作流文件来自: https://openart.ai/workflows/seal_harmful_40/flux/UGHBjoJgN8tLnhr7FKOP
ComfyUI QuadrupleCLIPLoader 节点
四重 CLIP 加载器 QuadrupleCLIPLoader 是 ComfyUI 的核心节点之一,最先添加在针对 HiDream I1 版本的模型支持上,如果你发现这个节点缺失,试着更新ComfyUI 版本到最新版本以保证节点支持。
它需要 4 个 CLIP 模型,分别对应 clip_name1, clip_name2, clip_name3, clip_name4 这四个参数,并会提供一个 CLIP 模型输出用于后续节点使用。
该节点会检测位于 ComfyUI/models/text_encoders 文件夹下的模型,
同时也会读取你在 extra_model_paths.yaml 文件中配置的额外路径的模型,
有时添加模型后你可能需要 重载 ComfyUI 界面 才能让它读取到对应文件夹下的模型文件
QuadrupleCLIPLoader 节点源代码
代码版本 9ad792f92706e2179c58b2e5348164acafa69288
QuadrupleCLIPLoader 节点示例工作流
请访问下面的教程查看 QuadrupleCLIPLoader 节点使用示例ComfyUI HiDream-I1 文生图工作流实例
UNET Loader | UNET加载器-ComfyUI节点
文档说明 - UNET Loader
- 类名:
UNETLoader - 类别:
高级/加载器 - 输出节点:
否
UNETLoader 节点旨在通过名称加载 U-Net 模型,方便在系统中使用预训练的 U-Net 架构。
这个节点名称已更新为 Load Diffusion Model.
输入类型 - UNET Loader
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
unet_name | COMBO[STRING] | 指定要加载的 U-Net 模型的名称。此名称用于在预定义的目录结构内定位模型,从而实现不同 U-Net 模型的动态加载。 |
weight_dtype | … |
fp8_e4m3fn和fp9_e5m2 表示不同精度和动态范围
输出类型 - UNET Loader
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 返回加载的 U-Net 模型,允许在系统中用于进一步处理或推理。 |
UNET Loader Guide | Load Diffusion Model Workflow Example
- 安装 UNET 模型
- 下载工作流文件
- 在 ComfyUI 中导入工作流
- 选择 UNET 模型并运行工作流
下载 FLux.1 UNET 模型
FLUX.1-schnell on hugging face
| 文件名称 | 文件尺寸 | 下载链接 | 备注 |
|---|---|---|---|
flux1-schnell.safetensors | 23.8GB | Download | 低显存用户 |
flux1-dev.safetensors | 23.8GB | Download | 高显存用户 |
- 下载
flux1-schnell.safetensors - 将对应的文件存放至
ComfyUI/models/unet/folder
Model Sampling Continuous EDM | 模型连续采样算法EDM-ComfyUI节点
文档说明
- 类名:
ModelSamplingContinuousEDM - 类别:
高级/模型 - 输出节点:
否
该节点旨在通过集成连续 EDM(基于能量的扩散模型)采样技术来增强模型的采样能力。它允许动态调整模型采样过程中的噪声水平,提供对生成质量和多样性的更精细控制。
输入类型
必填
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 需要增强连续 EDM 采样能力的模型。它作为应用高级采样技术的基石。 |
sampling | COMBO[STRING] | 指定要应用的采样类型,可以是 ‘eps’ 表示欧拉采样,或 ‘v_prediction’ 表示速度预测,这将影响采样过程中模型的行为。 |
sigma_max | FLOAT | 噪声水平的最大 sigma 值,允许在采样过程中控制噪声注入的上限。 |
sigma_min | FLOAT | 噪声水平的最小 sigma 值,设置噪声注入的下限,从而影响模型的采样精度。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 增强后的模型,集成了连续 EDM 采样能力,准备用于生成任务。 |
Model Sampling Discrete|模型离散采样算法-ComfyUI节点
文档说明
- 类名:
ModelSamplingDiscrete - 类别:
高级/模型 - 输出节点:
否
该节点旨在通过应用离散采样策略来修改模型的采样行为。它允许选择不同的采样方法,如 epsilon、v_prediction、lcm 或 x0,并可选地根据零样本噪声比率(zsnr)设置调整模型的噪声降低策略。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 将应用离散采样策略的模型。此参数定义了将进行修改的基础模型。 |
sampling | COMBO[STRING] | 指定要应用于模型的离散采样方法。选择的方法影响模型如何生成样本,提供了不同的采样策略。 |
zsnr | BOOLEAN | 一个布尔标志,启用时根据零样本噪声比率调整模型的噪声减少策略。这可以影响生成样本的质量和特性。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 修改后的模型,应用了离散采样策略。现在该模型可以使用指定的方法和调整来生成样本。 |
Rescale CFG|缩放CFG-ComfyUI节点

文档说明
- 类名:
RescaleCFG - 类别:
高级/模型 - 输出节点:
否
RescaleCFG 节点旨在根据指定的乘数调整模型输出的条件和非条件比例,目的是实现更加平衡和可控的生成过程。它通过重新调整模型的输出来修改条件和非条件组件的影响,从而可能增强模型的性能或输出质量。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 表示要调整的生成模型。节点对模型的输出应用重新缩放函数,直接影响生成过程。 |
multiplier | FLOAT | 控制应用于模型输出的重新缩放程度。它决定了原始和重新缩放组件之间的平衡,影响最终输出的特性。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 修改后的模型,调整了条件和非条件比例。预期该模型由于应用的重新缩放,将产生具有潜在增强特性的输出。 |
Checkpoint Save|保存模型-ComfyUI节点
文档说明
- 类名:
CheckpointSave - 类别:
高级/模型合并 - 输出节点:
是
CheckpointSave 节点设计用于将各种模型组件的状态,包括模型、CLIP 和 VAE,保存到检查点文件中。此功能对于保存模型的训练进度或配置以备后续使用或共享至关重要。
输入类型
必填
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 表示要保存状态的主要模型。捕获模型的当前状态以供将来恢复或分析至关重要。 |
clip | CLIP | 与主要模型相关联的 CLIP 模型的参数,允许其状态与主模型一起保存。 |
vae | VAE | 变分自编码器(VAE)模型的参数,使其状态可以与主模型和 CLIP 一起保存以供将来使用或分析。 |
filename_prefix | STRING | 指定保存检查点的文件名前缀,提供一种组织和识别保存的检查点的方法。 |
输出类型
这个节点将会输出一个 checkpoint 文件, 对应的输出文件路径为 output/checkpoints/ 目录
Checkpoint Save 工作流示例
关于这个节点的工作流示例,可以参考:Model Merging 工作流示例 将下面的图像加载到 ComfyUI 中,可以查看完整的工作流,
- 先启用工作流中
CheckpointSave节点,在两个Load Checkpoint加载你需要融合的模型 - 进行一次图片生成
- 找到
output/checkpoints/目录下生成的文件 - 你可以将生成后的文件作为一个新的 checkpoints 安装到
models\checkpoints\文件夹下,然后再使用文生图工作流来查看效果
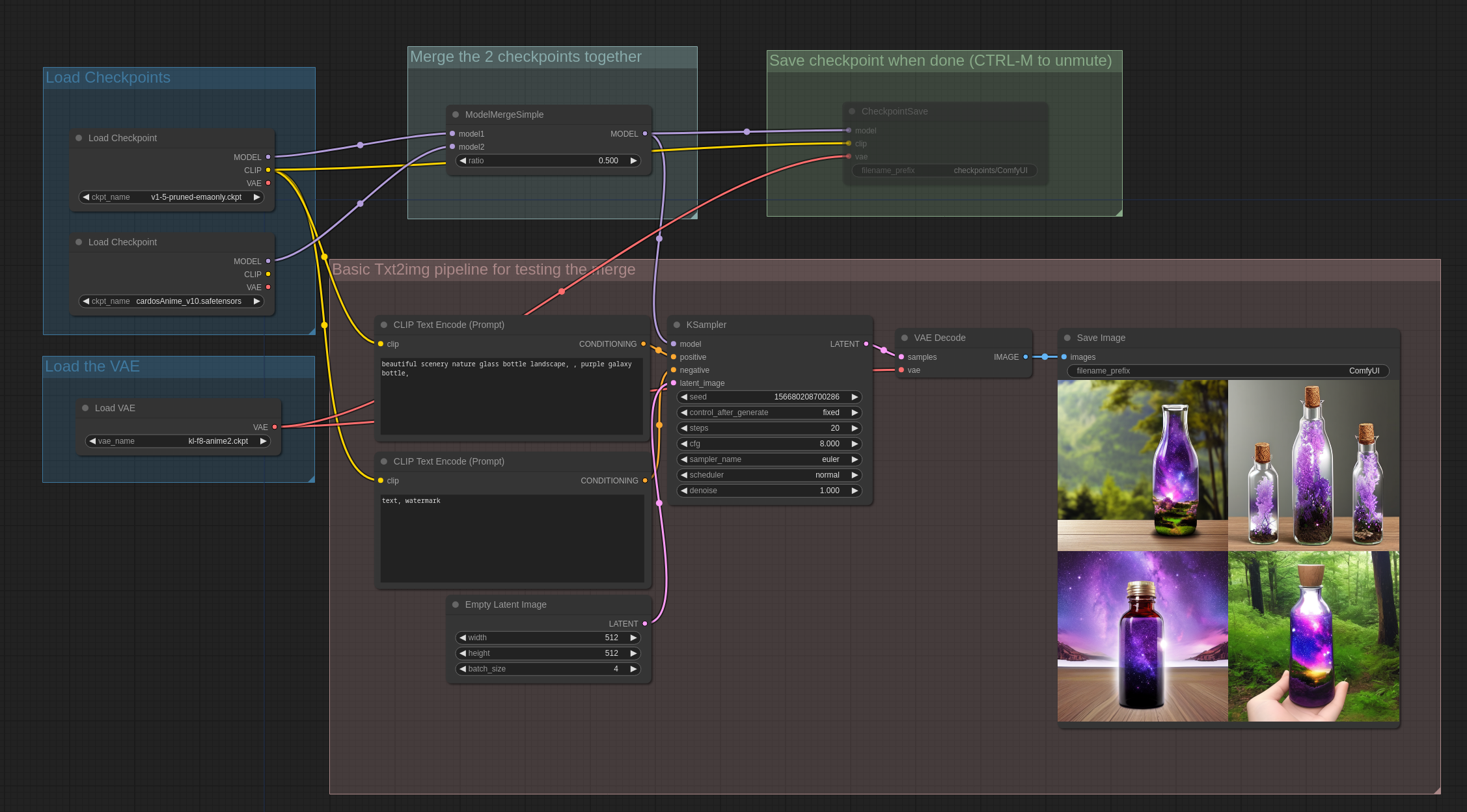
CLIPMerge Simple|融合CLIP-ComfyUI节点
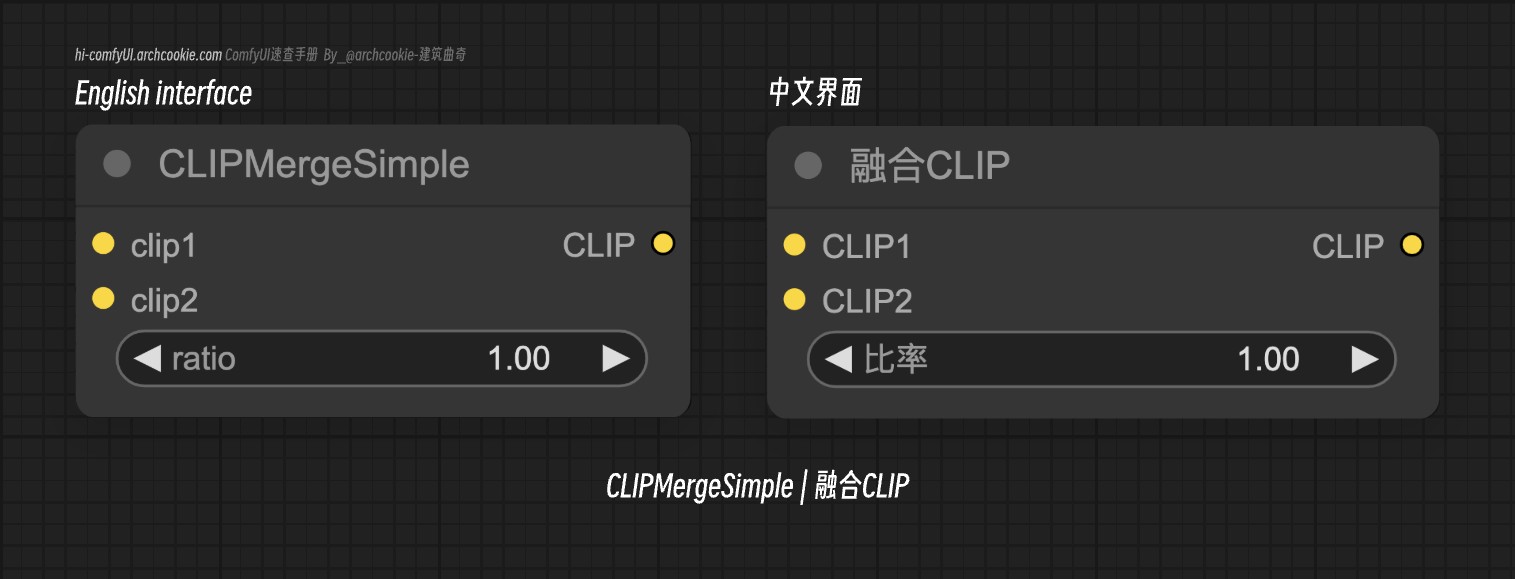
文档说明
- 类名:
CLIPMergeSimple - 分类:
高级/模型合并 - 输出节点:
False
此节点专门用于根据指定比例合并两个CLIP模型,有效地混合它们的特性。它有选择性地将一个模型的补丁应用到另一个模型上,排除像位置ID和对数尺度这样的特定组件,以创建一个结合了两个源模型特征的混合模型。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip1 | CLIP | 要合并的第一个CLIP模型。它作为合并过程的基础模型。 |
clip2 | CLIP | 要合并的第二个CLIP模型。根据指定的比例,除位置ID和对数尺度外,其关键补丁将应用于第一个模型。 |
ratio | FLOAT | 确定从第二个模型融合到第一个模型中的特性比例。比例为1.0意味着完全采用第二个模型的特性,而0.0则仅保留第一个模型的特性。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip | CLIP | 结果合并的CLIP模型,根据指定的比例整合了两个输入模型的特性。 |
CLIP Save | 保存CLIP-ComfyUI节点
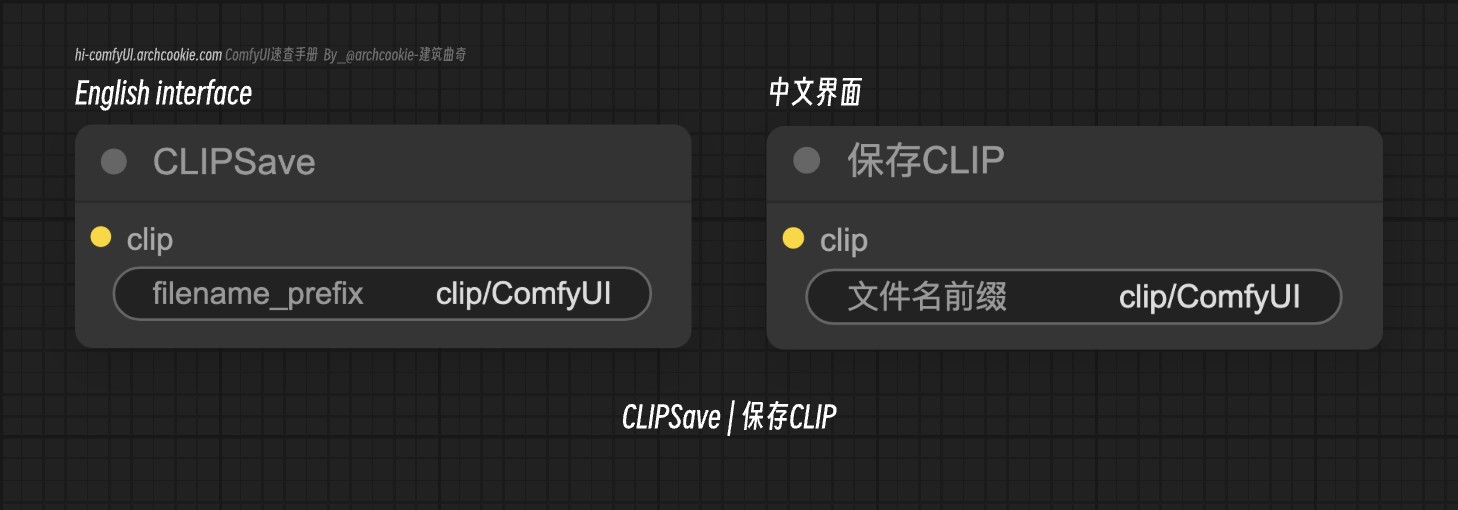
文档说明
- 类名:
CLIPSave - 分类:
高级/模型融合 - 是否为输出节点:是
CLIPSave 节点旨在保存 CLIP 模型及其附加信息,如提示和额外的PNG元数据。它集成了将模型状态序列化和存储的功能,便于模型配置及其相关创造性提示的保存和共享。
输入类型
| 参数名称 | 数据类型 | 作用描述 |
|---|---|---|
clip | CLIP | 需要保存的 CLIP 模型。此参数至关重要,因为它代表了将要序列化和存储状态的模型。 |
filename_prefix | STRING | 用于保存模型及其附加信息的文件名的前缀。此参数允许有序存储并便于检索保存的模型。 |
输出类型
该节点没有定义输出类型。
Model Merge Add|融合模型(相加)-ComfyUI节点

文档说明
- 类名:
ModelMergeAdd - 分类:
高级/模型合并 - 输出节点:
否
ModelMergeAdd 节点旨在通过添加一个模型的关键补丁到另一个模型来合并两个模型。这个过程涉及克隆第一个模型,然后应用第二个模型的补丁,从而允许结合两个模型的特征或行为。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model1 | MODEL | 这是要被克隆并添加第二个模型补丁的第一个模型。它作为合并过程的基础模型。 |
model2 | MODEL | 这是提取关键补丁并添加到第一个模型的第二个模型。它为合并后的模型贡献了额外的特征或行为。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 通过将第二个模型的关键补丁添加到第一个模型来合并两个模型的结果。这个合并后的模型结合了两个模型的特征或行为。 |
Model Merge Blocks|融合模型(分层)-ComfyUI节点
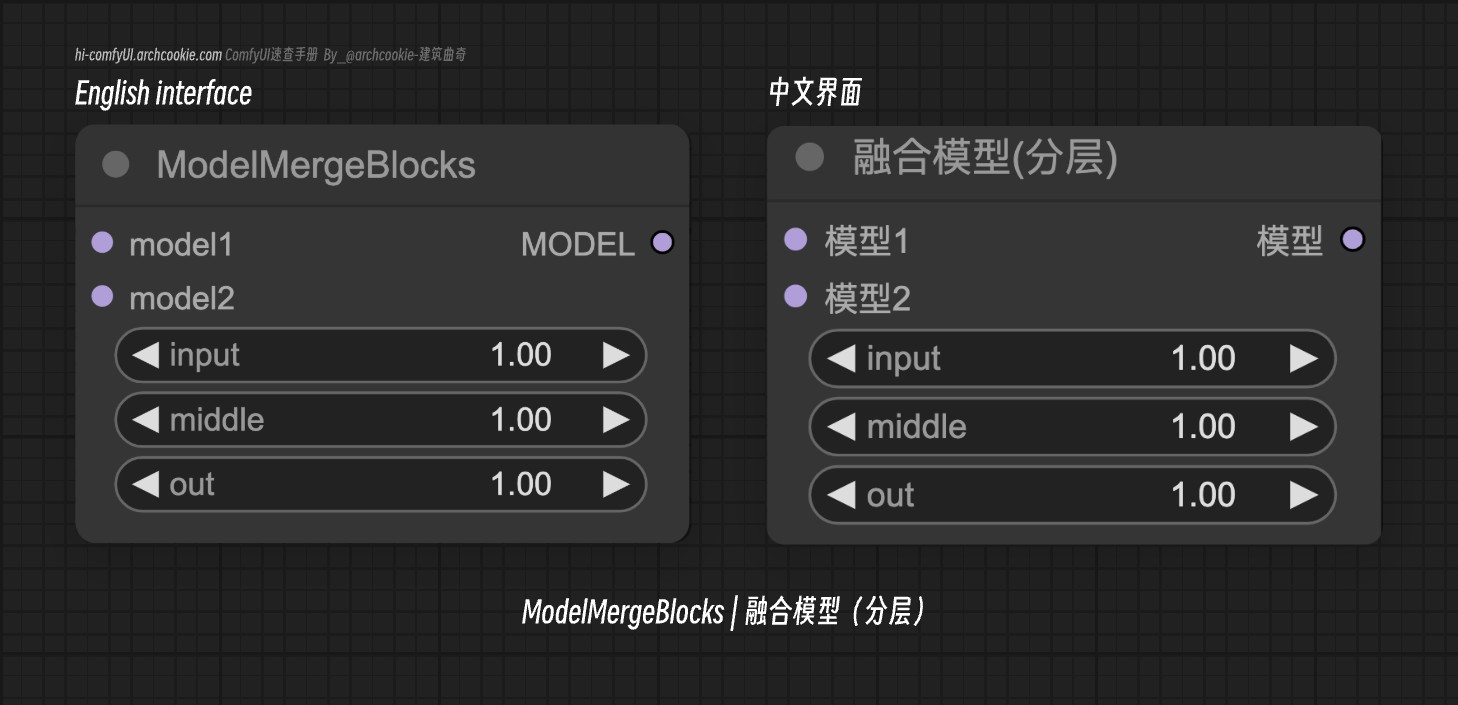
文档说明
- 类名:
ModelMergeBlocks - 分类:
高级/模型融合 - 输出节点:
否
融合模型(分层)节点旨在进行高级的模型融合操作,它允许将两个模型通过可定制的混合比例进行整合,以实现不同模型部分的融合。该节点通过基于指定参数选择性地合并两个源模型的组件,从而方便创建混合模型。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model1 | MODEL | 要合并的第一个模型。它作为基础模型,在其上应用第二个模型的补丁。 |
model2 | MODEL | 提取补丁并将其应用于第一个模型的第二个模型,基于指定的混合比例。 |
input | FLOAT | 指定模型输入层的混合比例。它决定了第二个模型输入层融合到第一个模型中的程度。 |
middle | FLOAT | 定义模型中间层的混合比例。此参数控制模型中间层的整合程度。 |
out | FLOAT | 确定模型输出层的混合比例。它通过调整第二个模型输出层的贡献来影响最终输出。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 结果融合的模型,它是两个输入模型的混合体,根据指定的混合比例应用补丁。 |
Model Merge Simple|融合模型-ComfyUI节点
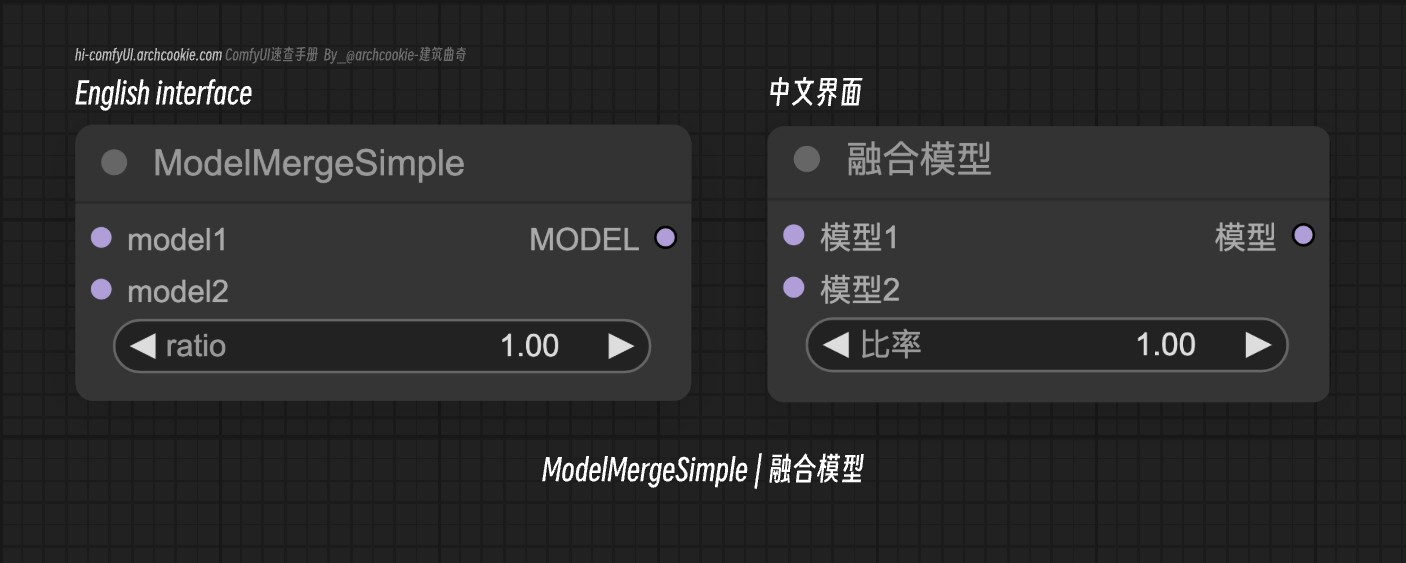
文档说明
- 类名:
ModelMergeSimple - 分类:
高级/模型融合 - 输出节点:
否
这个节点的作用主要是将两个合并成一个模型作为后续的绘图模型输出,当你想使用两个模型的时候,你想要融合他们的特征作为后续的输出时,这个节点就非常有用。
其中 ratio 参数的作用是决定融合的比例,当这个值为 1 时,则输出的模型为 100% 的model1,当这个值为 0 时,则输出的模型为100% 的 model2
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model1 | MODEL | 要合并的第一个模型。它作为基础模型,在其上应用第二个模型的补丁。 |
model2 | MODEL | 应用其补丁到第一个模型的第二个模型,受指定比例的影响。 |
ratio | FLOAT | 当这个值为 1 时,则输出的模型为 100% 的model1,当这个值为 0 时,则输出的模型为100% 的 model2 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 结果融合的模型,根据指定比例整合了两个输入模型的元素。 |
Model Merge Simple 工作流示例
关于这个节点的工作流示例,可以参考:Model Merging 工作流示例
将下面的图像加载到 ComfyUI 中,可以查看完整的工作流, 你可以调整 ratio 的值来查看不同的融合效果对比
Model Merge Subtract|融合模型(相减)-ComfyUI节点
文档说明
- 类名:
ModelMergeSubtract - 分类:
高级/模型融合 - 输出节点:
否
这个节点设计用于高级模型融合操作,特别是根据指定的乘数从一个模型中减去另一个模型的参数。它允许通过调整一个模型参数对另一个模型的影响来定制模型行为,从而方便创建新的混合模型。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model1 | MODEL | 作为基础模型,其参数将被减去。 |
model2 | MODEL | 其参数将从基础模型中减去的模型。 |
multiplier | FLOAT | 一个浮点值,用于缩放对基础模型参数的减法效果。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
model | MODEL | 在减去一个模型的参数并乘以乘数后的得到的模型。 |
VAE Save|保存VAE-ComfyUI节点

文档说明
- 类名:
VAESave - 分类:
高级/模型合并 - 输出节点:
是
VAESave 节点旨在将变分自编码器(VAE)模型及其元数据(包括提示和附加的PNG信息)保存到指定的输出目录中。它封装了将模型状态和相关信息序列化到文件的功能,便于保存和共享训练好的模型。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
vae | VAE | 要保存的VAE模型。此参数至关重要,因为它代表了要序列化并存储状态的模型。 |
filename_prefix | STRING | 用于保存模型及其元数据的文件名前缀。这允许有序存储和轻松检索模型。 |
输出类型
该节点没有输出类型。