图像到图像(Img2Img)示例
以下是一些示例,展示了如何进行图像到图像(img2img)的处理。
你可以在 ComfyUI 中加载这些图像以获得完整的工作流程。
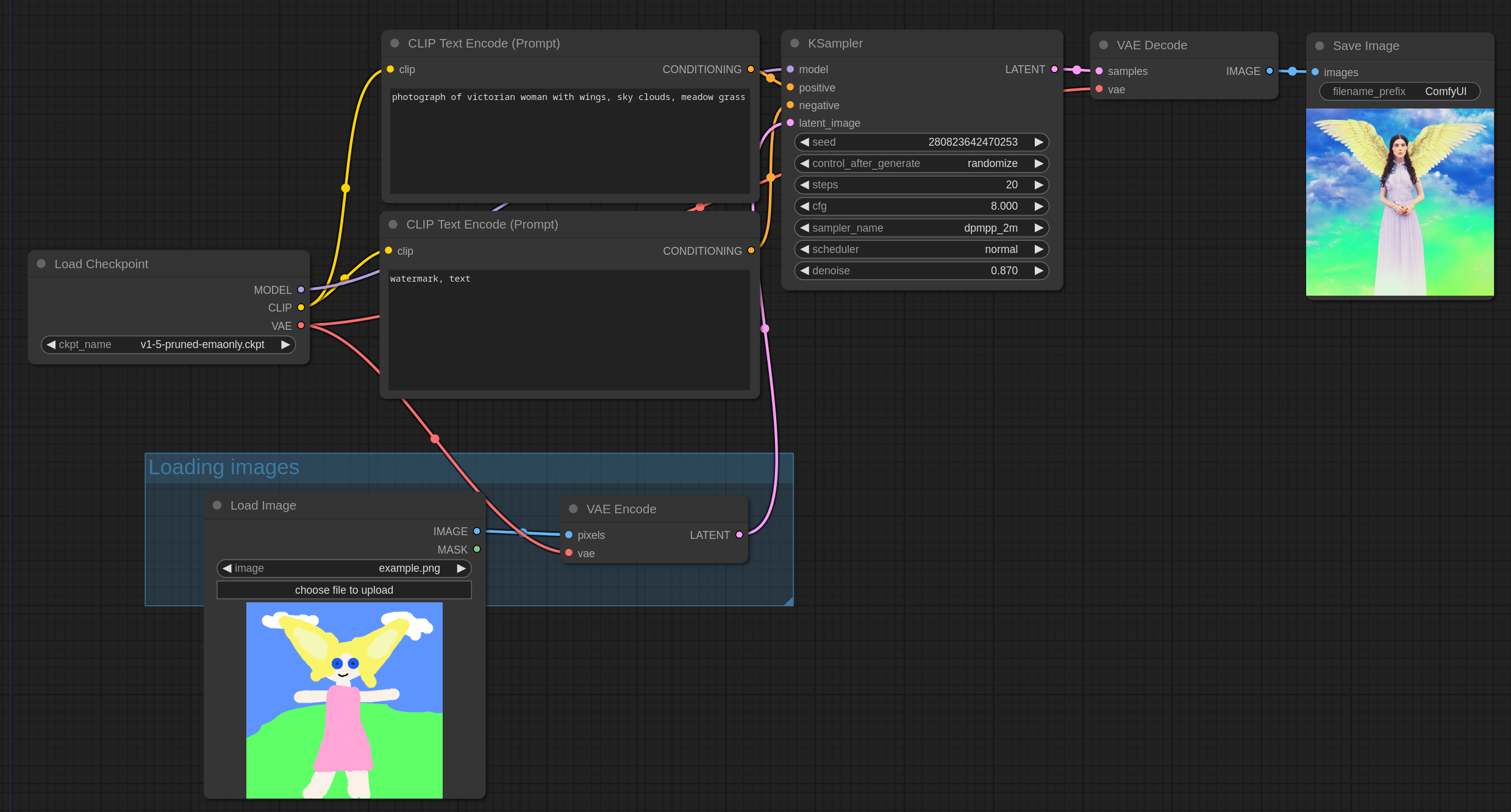
图像到图像(Img2Img)通过加载像这样的示例图像,将其转换为潜在空间的VAE,然后使用低于1.0的去噪对其进行采样。去噪控制添加到图像中的噪声量。去噪越低,添加的噪声就越少,图像变化也越小。
{kind=link}
输入图像应放在输入文件夹中。
一个简单的图像到图像(img2img)工作流程看起来像这样,它与默认的文本到图像(txt2img)工作流程相同,但是去噪设置为0.87,并且传递给采样器的是已加载的图像而不是空图像。
两阶段文本到图像(高分辨率修复)- ComfyUI 工作流示例
以下是一些示例,展示了如何实现“高分辨率修复”功能。
你可以在 ComfyUI 中加载这些图像以获得完整的工作流程。
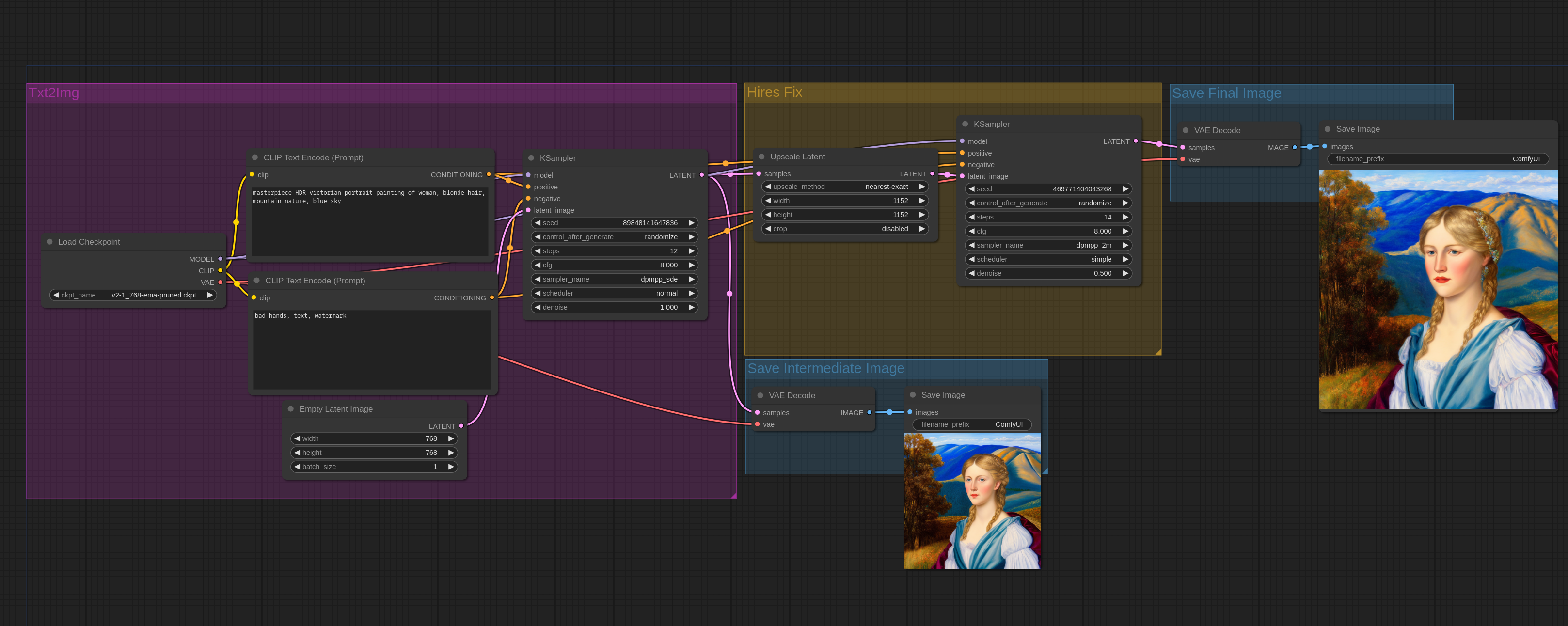
高分辨率修复仅仅是在较低分辨率下创建图像,对其进行放大,然后通过图像到图像的处理。请注意,在ComfyUI中,文本到图像(txt2img)和图像到图像(img2img)是同一个节点。通过将一个空图像传递给采样器节点,并使用最大去噪来实现文本到图像。
以下是在ComfyUI中使用基本潜在放大的简单工作流程:
非潜在放大
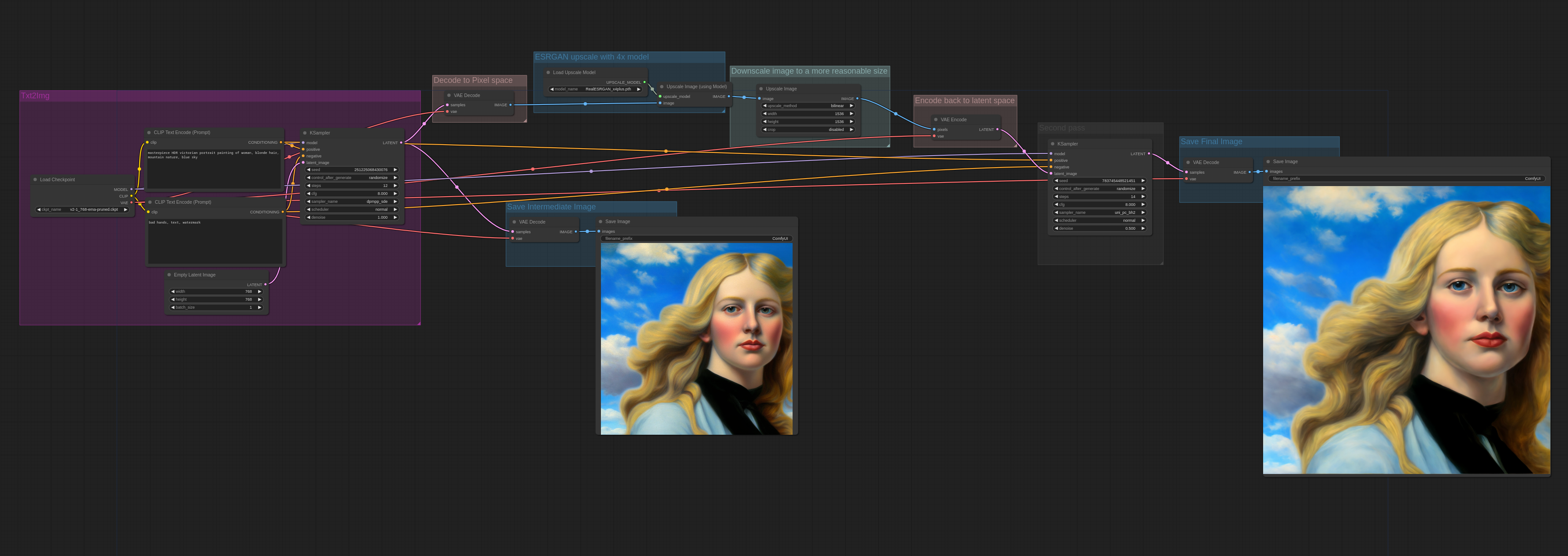
以下是如何使用 esrgan放大器 进行放大步骤的示例。由于ESRGAN在像素空间中操作,因此图像必须在放大后转换为像素空间,然后再转换回潜在空间。
更多示例
这是一个更复杂的两阶段工作流程示例,这张图像首先使用WD1.5 beta 3幻觉模型生成,潜在放大,然后使用cardosAnime_v10进行第二阶段处理:

ComfyUI 局部重绘 Inpaint 工作流
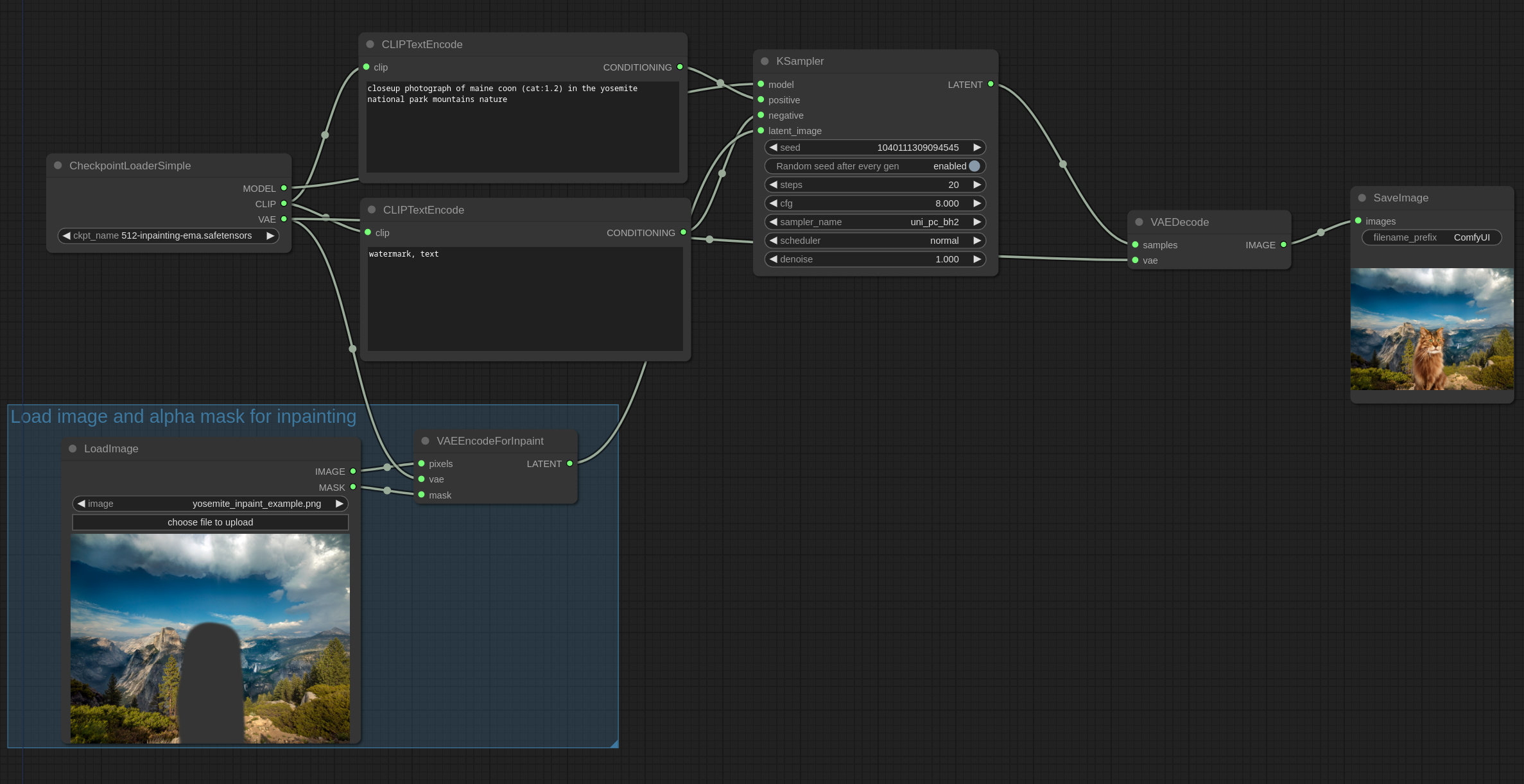
在这个示例中,我们将使用这张图片。下载它并将其放置在您的输入文件夹中。

这张图片的某些部分已经被GIMP擦除成透明,我们将使用alpha通道作为修复的遮罩。如果使用GIMP,请确保保存透明像素的值以获得最佳效果。
ComfyUI还具有一个遮罩编辑器,可以通过右键单击LoadImage节点中的图像并选择“在MaskEditor中打开”来访问。
以下图像可以在 ComfyUI 中加载以获取完整的工作流程。
使用v2修复模型修复一只猫:

使用v2修复模型修复一个女人:

它也适用于非修复模型。以下是使用anythingV3模型的示例:

外延(Outpainting)
您也可以使用类似的工作流程进行外延。外延与内插修复是相同的。有一个“Pad Image for Outpainting”节点可以自动填充图像以进行外延,同时创建正确的遮罩。在这个例子中,这张图片将被外延:

使用v2修复模型和“Pad Image for Outpainting”节点(在ComfyUI中加载它以查看工作流程):

区域组合示例 - ComfyUI工作流
以下是一些示例,展示了如何使用ConditioningSetArea节点。你可以在ComfyUI中加载这些图像以获得完整的工作流程。
使用Anything-V3的区域组合 + 第二阶段使用AbyssOrangeMix2_hard
这张图片包含了4个不同的区域:夜晚、傍晚、白天、早晨

在ComfyUI中,工作流程看起来像这样:
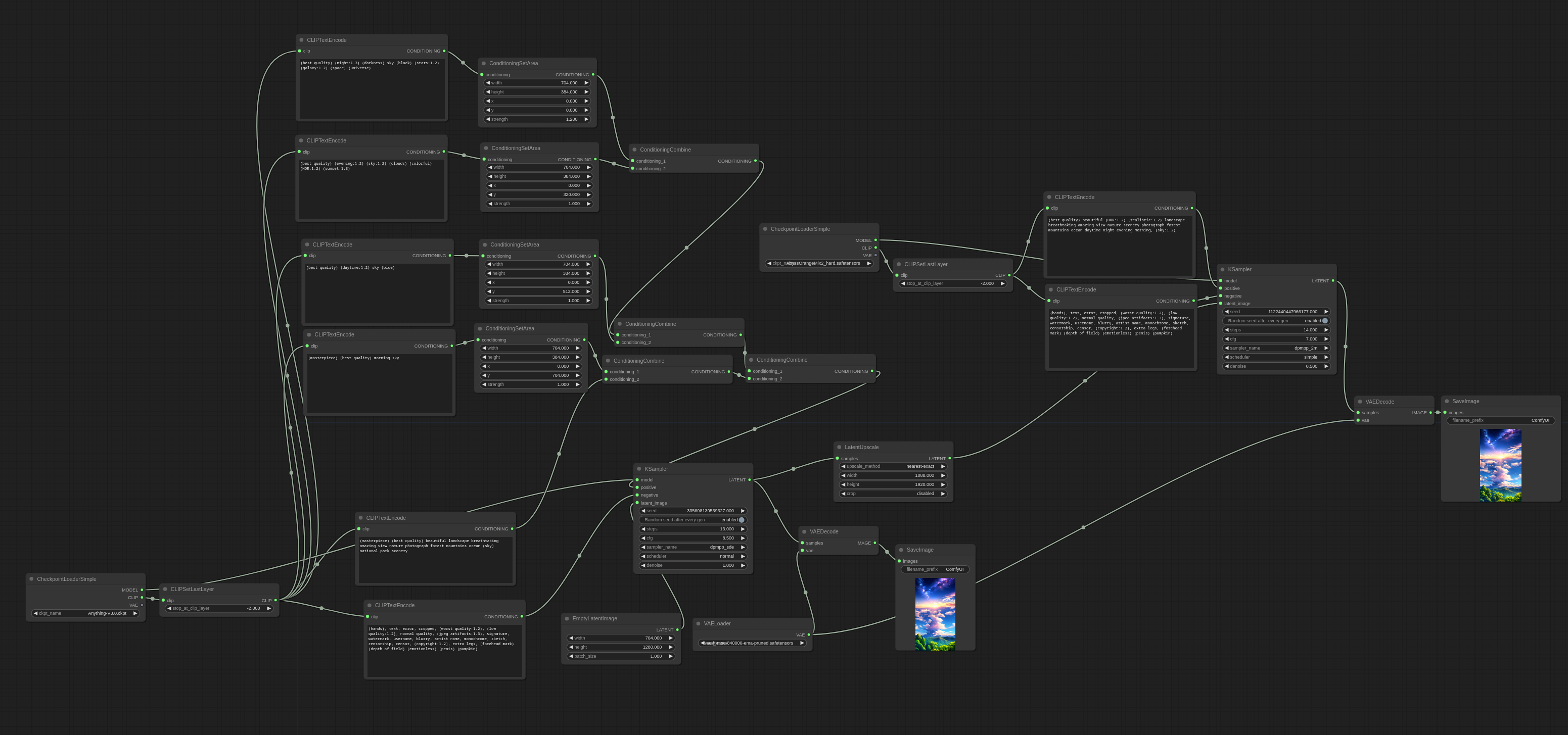
这张图片包含了与前一张相同的区域,但是顺序相反。

通过添加另一个区域提示,将主体添加到图片的底部中心。

使用区域组合提高图像一致性
稳定扩散在生成接近512x512分辨率的正方形图像时,能够创建最一致的图像。但如果我们想要生成一个16:9宽高比的图像怎么办?
让我们生成一个16:9的图像,里面有一个坐着的主体。如果正常生成,成功率会很低,因为四肢会不自然地延伸到图像的其他地方,以及其他一致性问题。
通过使用区域组合,为主体使用一个正方形区域,一致性会更高,并且由于它是与图像的其余部分同时生成的,整体图像的一致性将会非常好。
这个工作流程使用了Anything-V3,它是一个两阶段工作流程,第一阶段在图像左侧使用区域组合来处理主体。第二阶段的原因仅仅是为了提高分辨率,如果你对1280x704的图像满意,你可以跳过第二阶段。

在图像右侧添加一个红发主体,使用区域提示。
第一阶段输出(1280x704):

第二阶段输出(1920x1088):

这张第二阶段输出图像展示了稳定扩散的其中一个行为。第二阶段没有区域提示。你会注意到,主体1的头发是金色带有粉红色的高光,而主体2的头发是粉红色而不是红色,这与第一阶段的输出不同。这是因为稳定扩散试图使整个图像与自身保持一致,其中一个副作用是合并头发颜色。
放大模型示例
以下是如何使用像ESRGAN这样的放大模型的示例。将它们放入models/upscale_models文件夹中,然后使用UpscaleModelLoader节点加载它们,并使用ImageUpscaleWithModel节点使用它们。
示例如下:
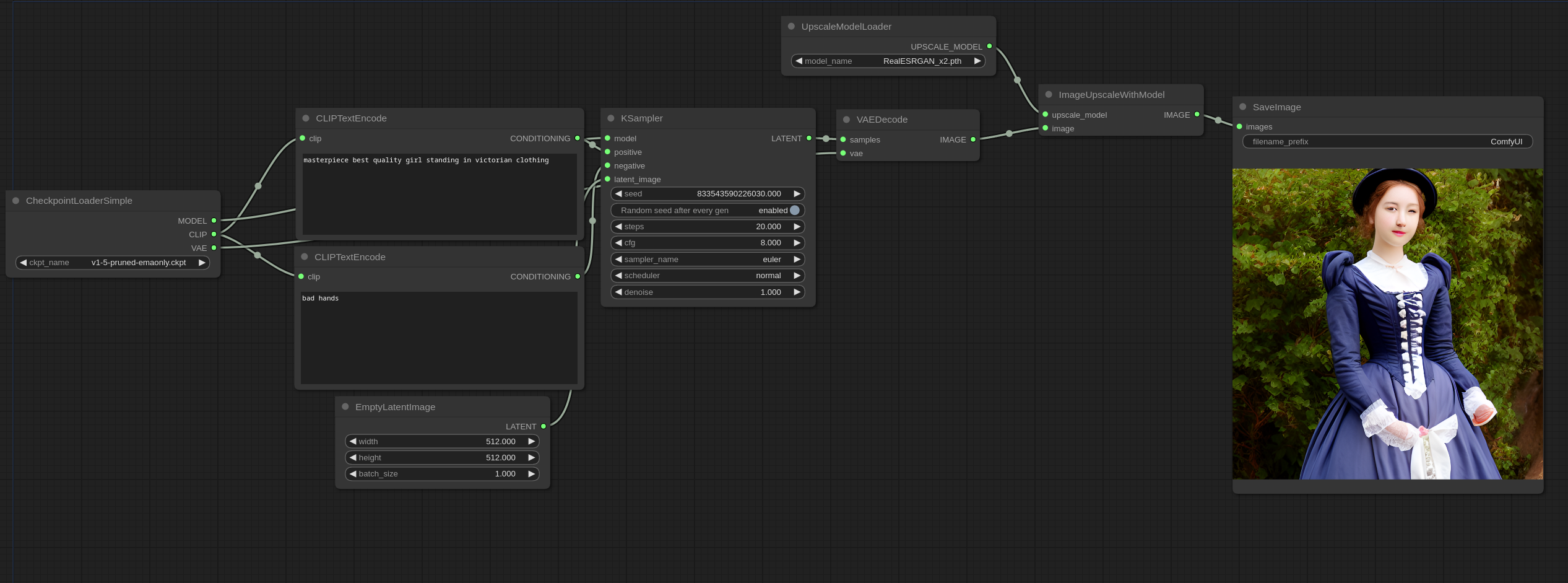
您可以在 ComfyUI 中加载此图像以获取工作流程。
如果您正在寻找要使用的放大模型,您可以在 OpenModelDB 上找到一些。
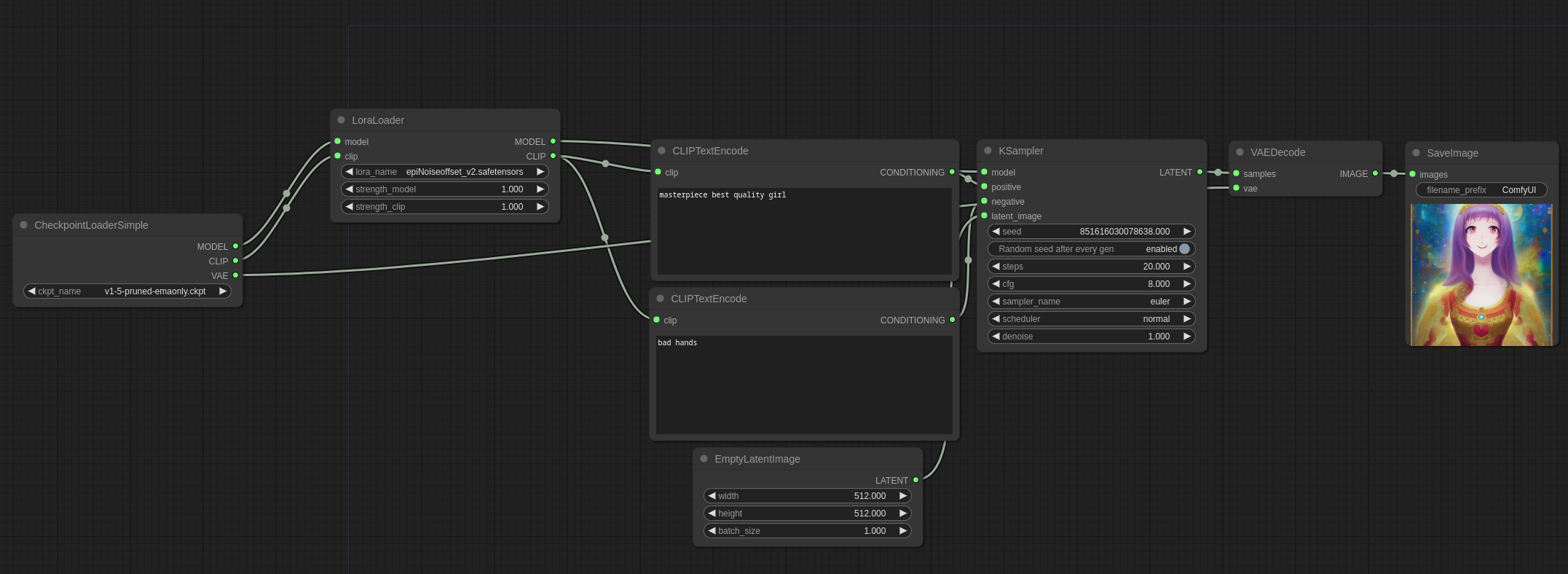
Lora 示例
以下是一些示例,展示了如何使用Loras。所有LoRA变体:Lycoris、loha、lokr、locon等…都是这样使用的。
你可以在 ComfyUI 中加载这些图像以获得完整的工作流程。
Loras是应用于主模型和CLIP模型之上的补丁,因此要使用它们,将它们放入models/loras目录,并像这样使用LoraLoader节点:
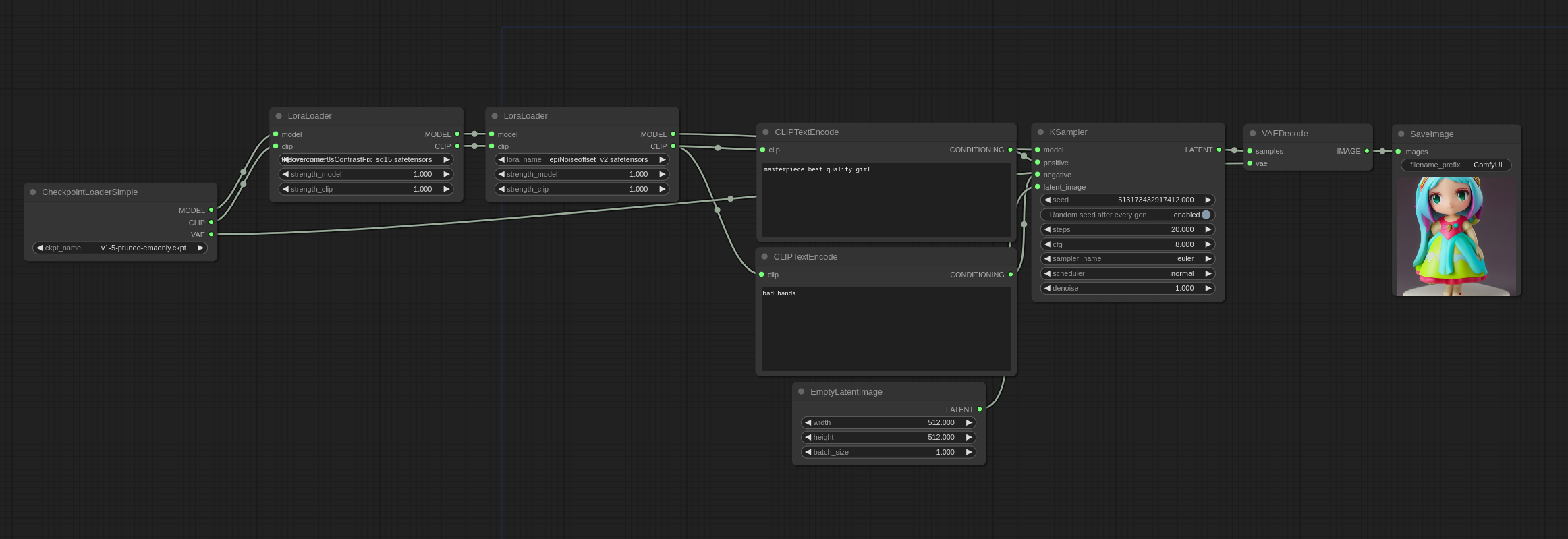
你可以通过像这样链接多个LoraLoader节点来应用多个Loras:
ControlNet和T2I-Adapter - ComfyUI工作流示例
请注意,在这些示例中,原始图像直接传递给 ControlNet/T2I 适配器。
每个 ControlNet/T2I 适配器需要传递给它的图像具有特定格式,例如深度图、Canny 图等,这取决于特定模型,如果您想要好的结果。
ControlNetApply 节点不会为您将常规图像转换为深度图、Canny 图等。您必须单独进行此操作,或使用节点预处理您的图像,您可以在这里找到这些节点。
您可以在此处找到最新的 ControlNet 模型文件:原始版本 或 较小的fp16 safetensors版本
对于SDXL, stability.ai 发布了 Control Loras ,您可以在这里(等级256) 或 这里(等级128)找到。它们的使用方式与常规ControlNet模型文件完全相同(将它们放在同一个目录中)。
ControlNet 模型文件应放在 ComfyUI/models/controlnet 目录中。
scribble(涂鸦) ControlNet
这是一个如何使用 controlnets 的简单示例,此示例使用 scribble controlnet 和 AnythingV3 模型。您可以在ComfyUI中加载此图像以获取完整的工作流程。
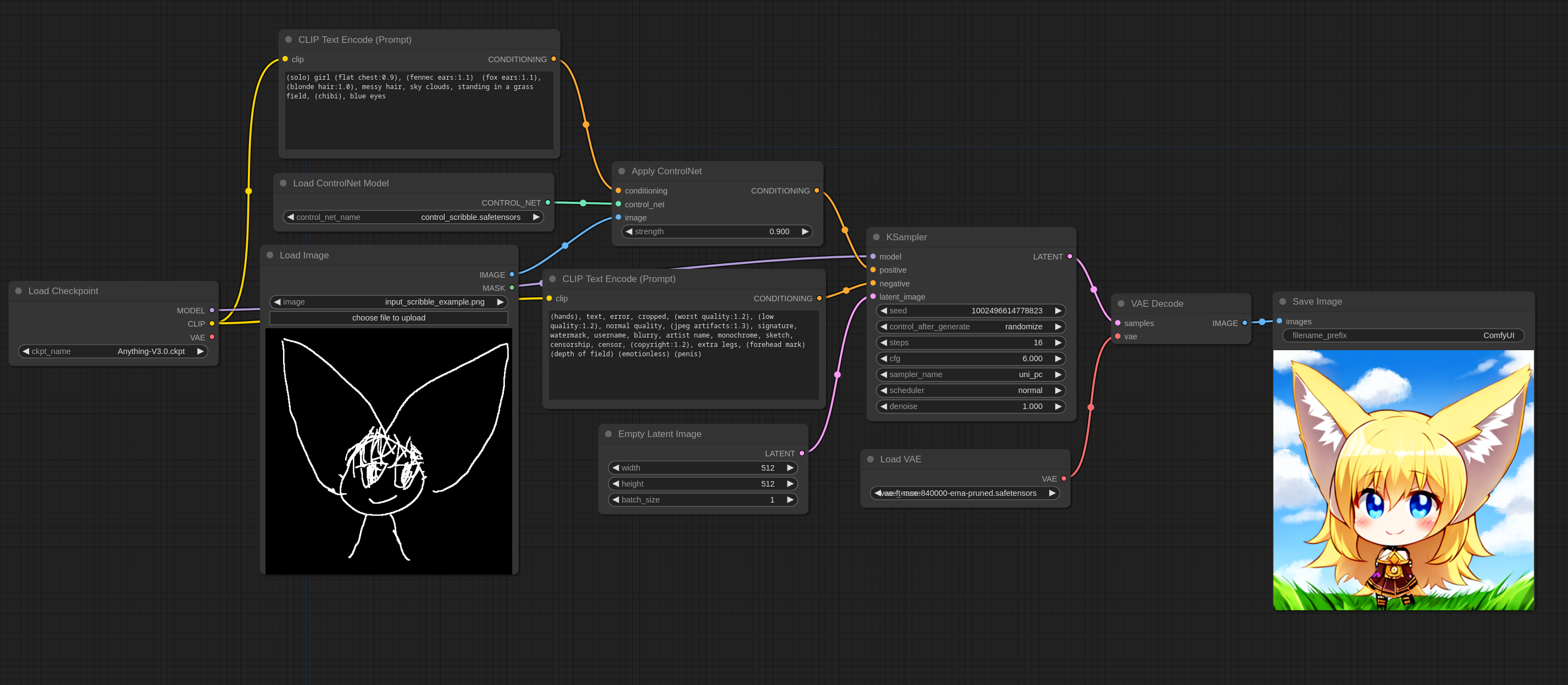
这是我在此工作流程中使用的输入图像:

T2I-Adapter与ControlNets
T2I-Adapters比ControlNets高效得多,因此我强烈推荐它们。ControlNets会显著降低生成速度,而T2I-Adapters对生成速度几乎没有负面影响。
在ControlNets中,ControlNet模型每次迭代运行一次。对于T2I-Adapter,模型总共只运行一次。
T2I-Adapters在ComfyUI中的使用方式与ControlNets相同:使用ControlNetLoader节点。
这是此示例中将使用的输入图像 来源:
{kind=link}

以下是如何使用深度 T2I-Adapter:
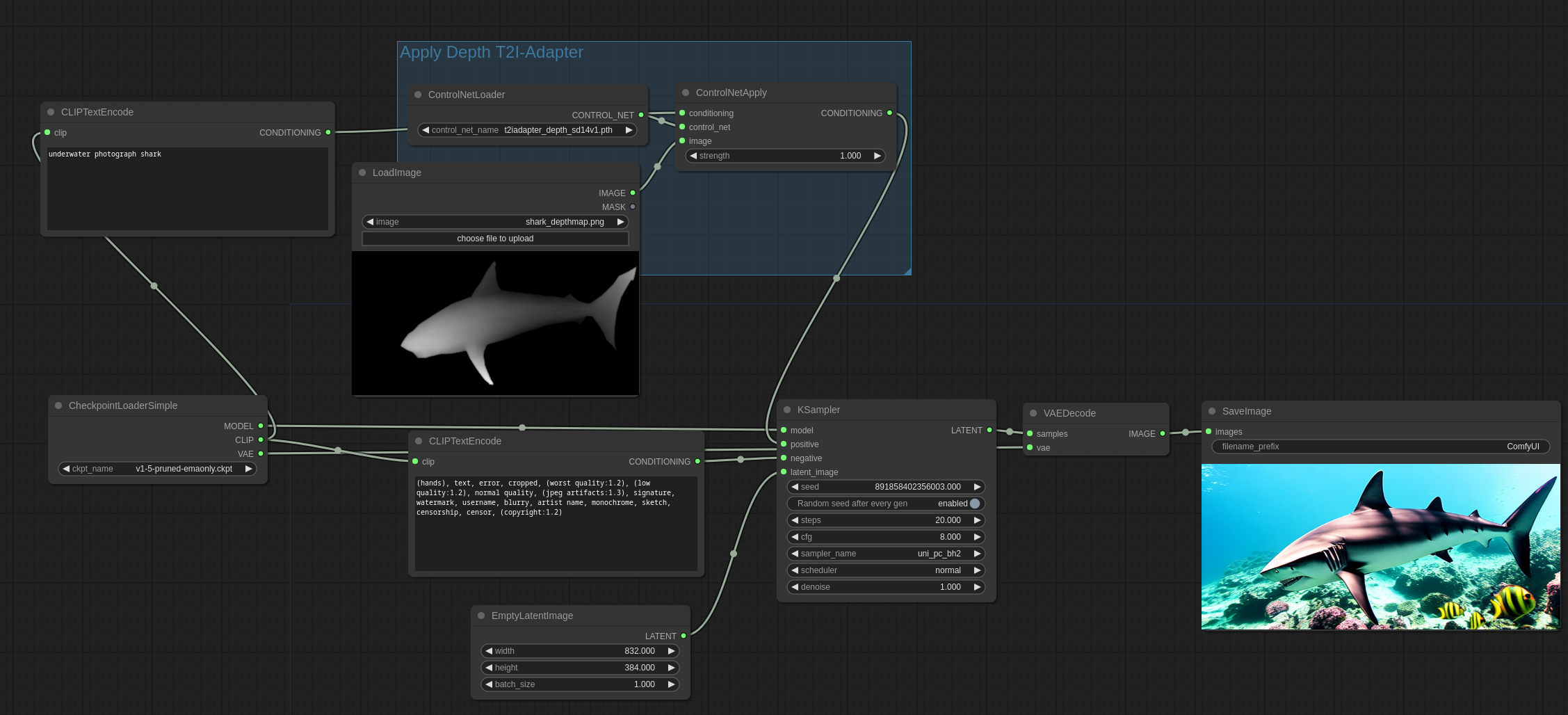
以下是如何使用深度Controlnet。请注意,此示例使用DiffControlNetLoader节点,因为使用的controlnet是diff control net。Diff controlnets需要加载模型的权重才能正确加载。DiffControlNetLoader节点也可以用来加载常规controlnet模型。当加载常规controlnet模型时,它的行为将与ControlNetLoader节点相同。
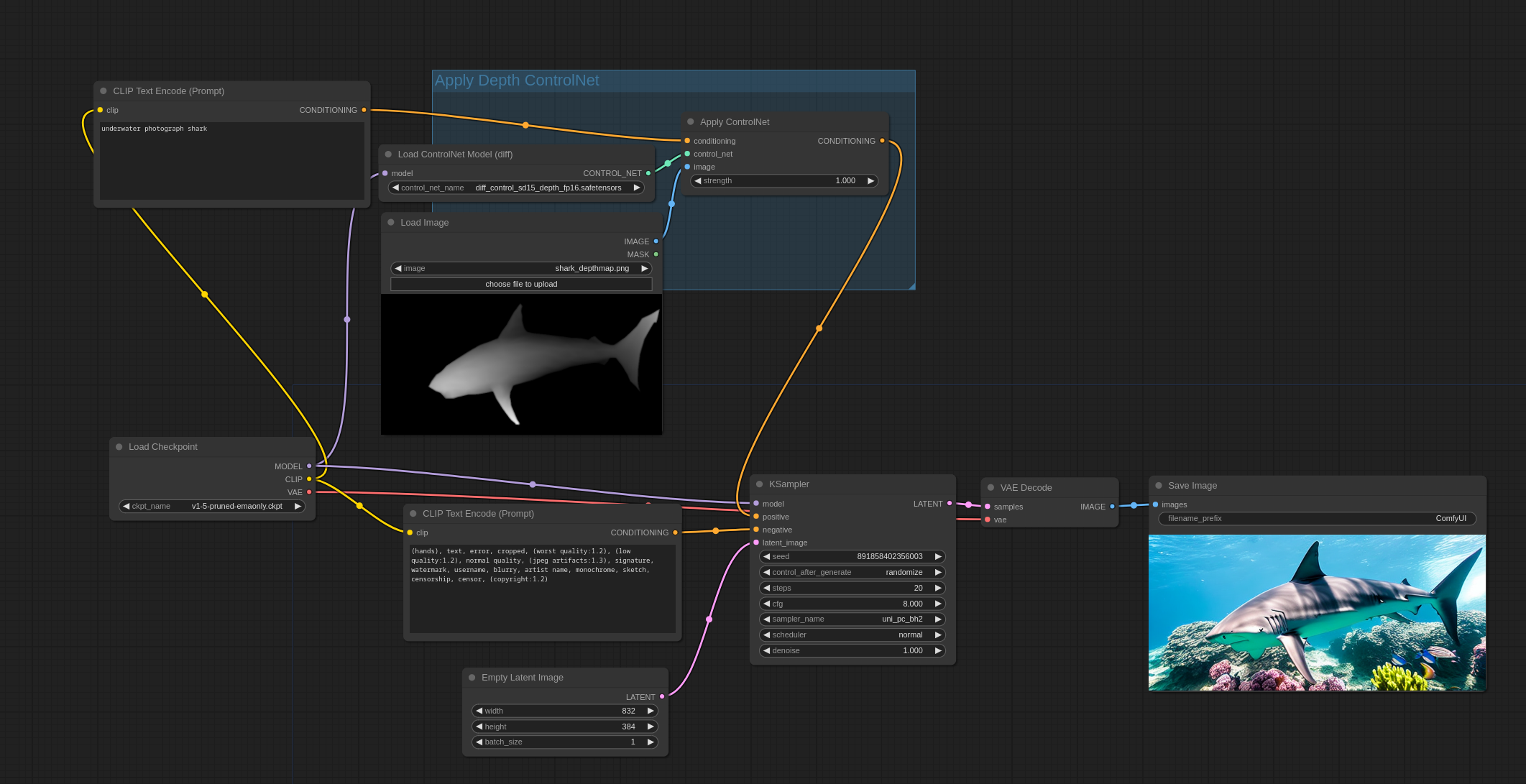
您可以在ComfyUI中加载这些图像以获取完整的工作流程。
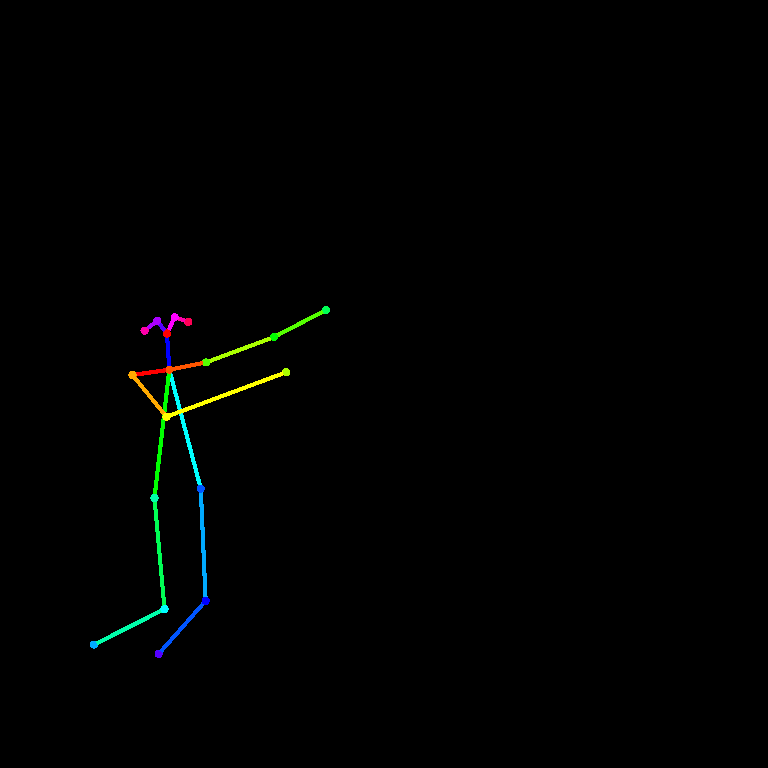
姿势 Pose ControlNet
这是此示例中将使用的输入图像:
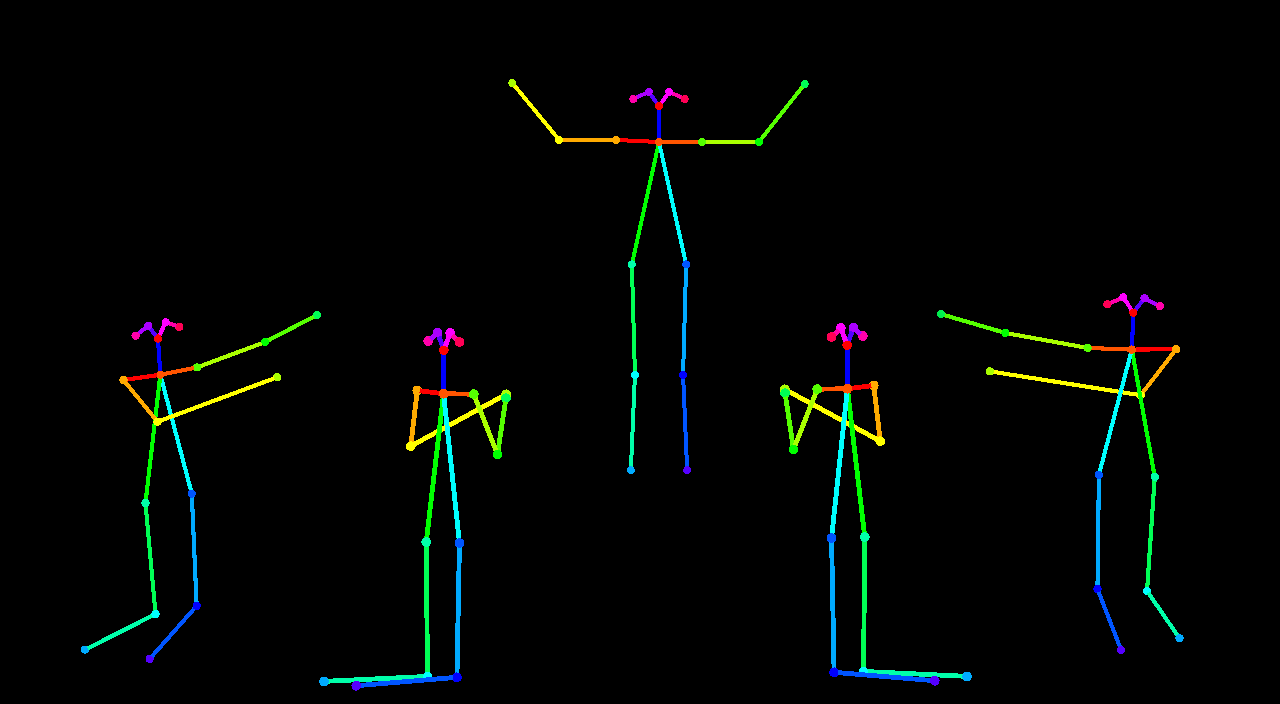
以下是使用AnythingV3进行第一次通过,使用controlnet,然后使用AOM3A3(abyss orange mix 3)进行第二次通过,而不使用controlnet,并使用它们的VAE的示例。

您可以在ComfyUI中加载此图像以获取完整的工作流程。
混合ControlNets
可以像这样应用多个ControlNets和T2I-Adapters,结果很有趣:
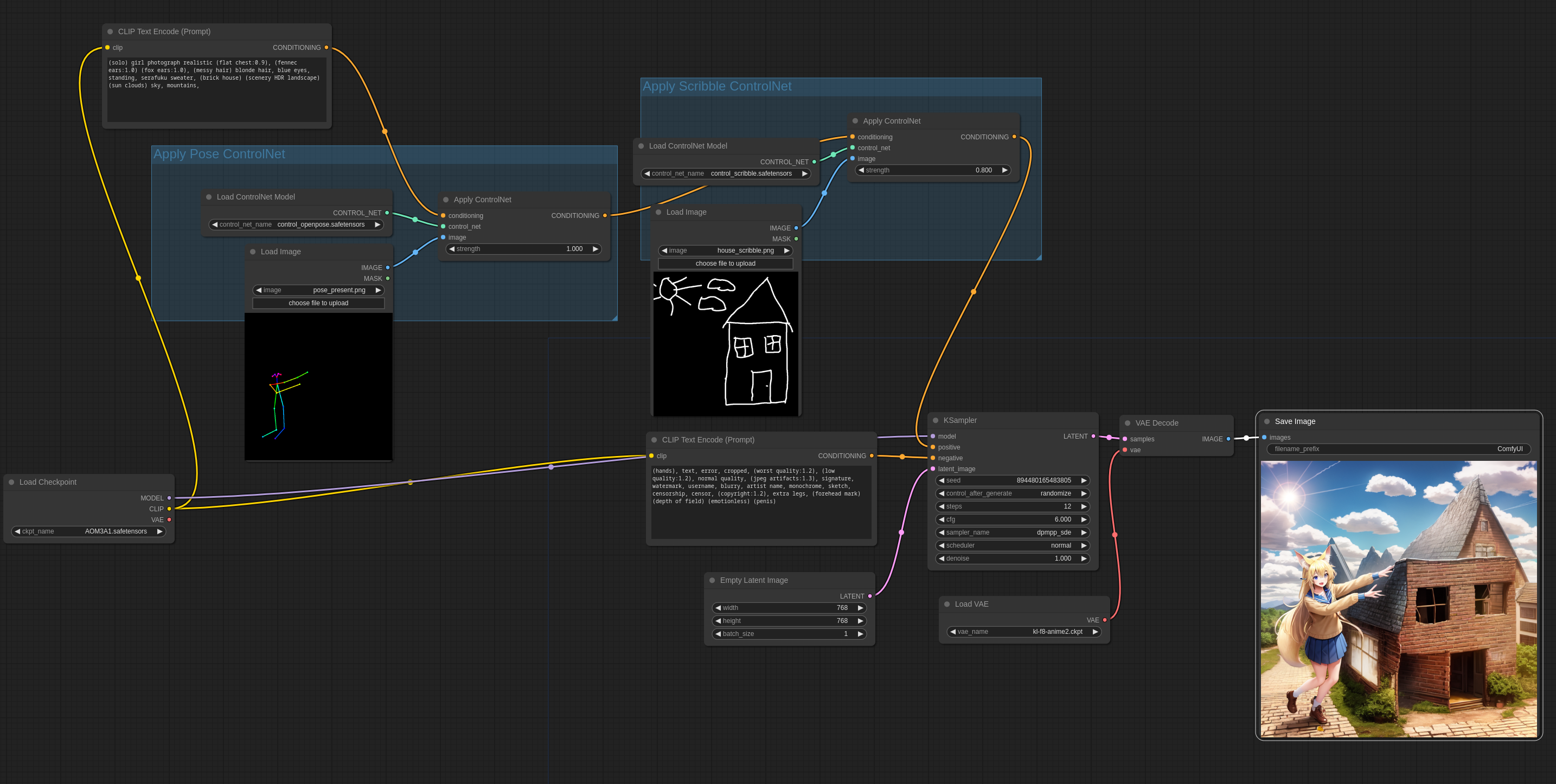
您可以在ComfyUI中加载此图像以获取完整的工作流程。
输入图像:
噪声潜在组合示例
你可以在 ComfyUI 中加载这些图像以获得完整的工作流程。
以下是一些噪声潜在组合的示例。噪声潜在组合是指在图像完全去噪之前,潜在图像仍然带有噪声时就进行组合。由于一般形状如姿势和主体在第一次采样步骤中就去噪了,这让我们可以将具有特定姿势的主体放置在图像的任何位置,同时保持了极大的一致性。
以下是一个示例。这个示例包含了4张组合在一起的图像。1张背景图像和3个主体。 总步骤是16步。潜在图像分别用4个不同的提示采样4步。背景是1920x1088,主体每个是384x768。这4步之后,图像仍然非常嘈杂。然后,主体被组合(粘贴)到背景上,并应用了一些羽化效果。其余的采样步骤则在这张组合后的图像上运行。
这些示例是使用WD1.5 beta 3幻觉模型完成的。

改变主体位置的示例:

你可以看到,从不同的噪声潜在图像组合的主体实际上彼此互动,因为我在提示中加入了“手拉手”。你也会注意到背景的一致性如何,这展示了这种方法的强大。
这种技术有一些局限性,例如它不能控制主体上的细节,比如眼睛颜色,但似乎对于主体位置、姿势和一般颜色的控制效果非常好。
文本反演嵌入示例
以下是如何使用文本反演/嵌入的示例。
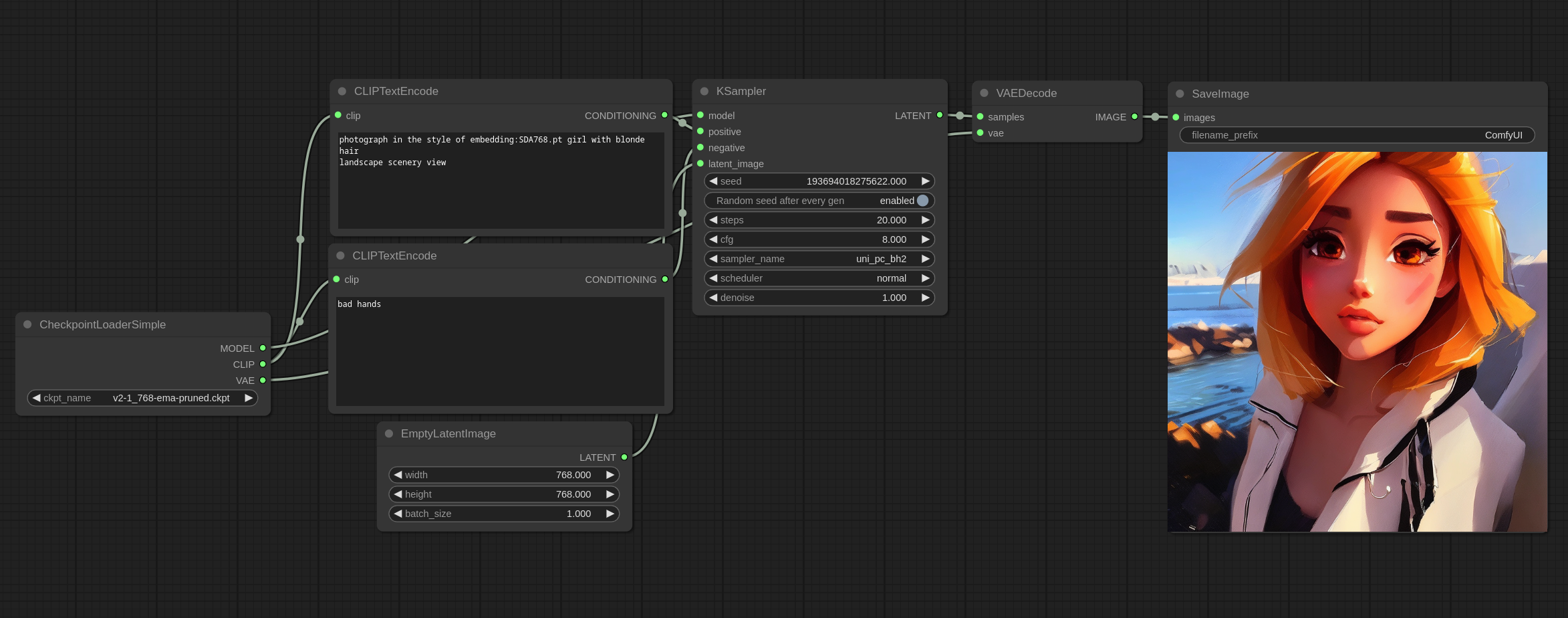
要使用一个嵌入文件,将其放入 models/embeddings 文件夹中,然后在您的提示中像我在上图中使用 SDA768.pt 嵌入那样使用它。
请注意,您可以省略文件名扩展名,因此以下两种方式是等效的:
embedding:SDA768.pt
embedding:SDA768
您还可以像提示中的常规单词一样设置嵌入的强度:
(embedding:SDA768:1.2)
嵌入基本上是自定义单词,因此您在文本提示中放置它们的位置很重要。
例如,如果您有一个猫的嵌入:
red embedding:cat
这可能会给您一个红色的猫。
图像编辑模型示例
编辑模型,也称为InstructPix2Pix模型,是可以使用文本提示编辑图像的模型。
以下是稳定性SDXL编辑模型的工作流程,检查点可以从这里下载。要使用它,请下载cosxl_edit.safetensors文件并将其放入ComfyUI/models/checkpoints文件夹中。

您可以下载上面的图像,然后拖拽或加载到ComfyUI上以获取嵌入在图像中的工作流程。
上述示例中使用的输入图像可以在这里找到。
模型合并示例
这些工作流程背后的理念是,您可以进行涉及多个模型合并的复杂工作流程,测试它们,然后在您对结果满意时通过取消CheckpointSave节点的静音来保存检查点。默认情况下,CheckpointSave节点将检查点保存到output/checkpoints/文件夹中。
您可以在:advanced->model_merging中找到这些节点
这个第一个示例是两个不同检查点之间简单合并的基本示例。
您可以在 ComfyUI 中加载这些图像以获得完整的工作流程。
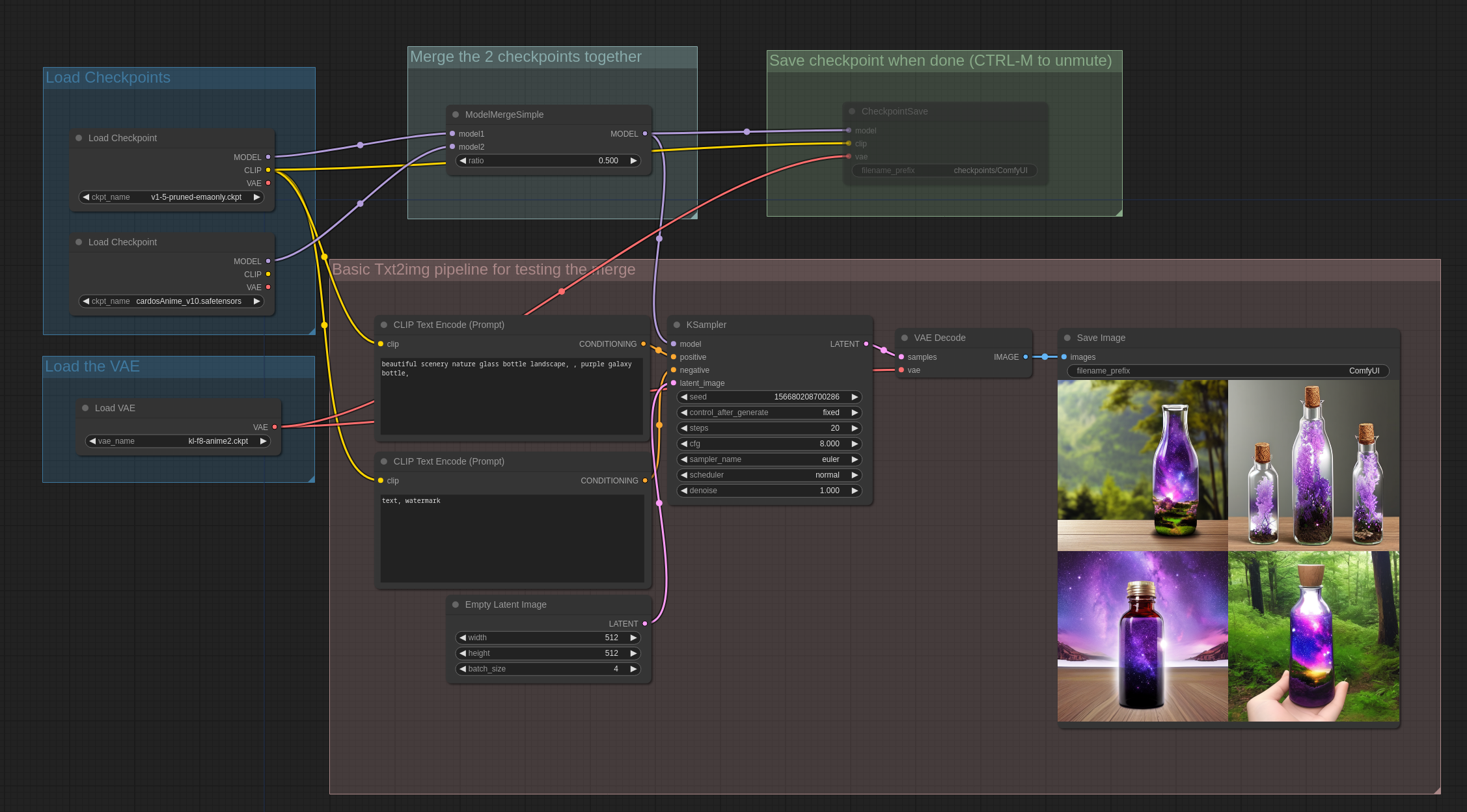
在ComfyUI中,保存的检查点包含用于生成它们的完整工作流程,因此它们可以像图像一样在UI中加载,以获取用于创建它们的完整工作流程。
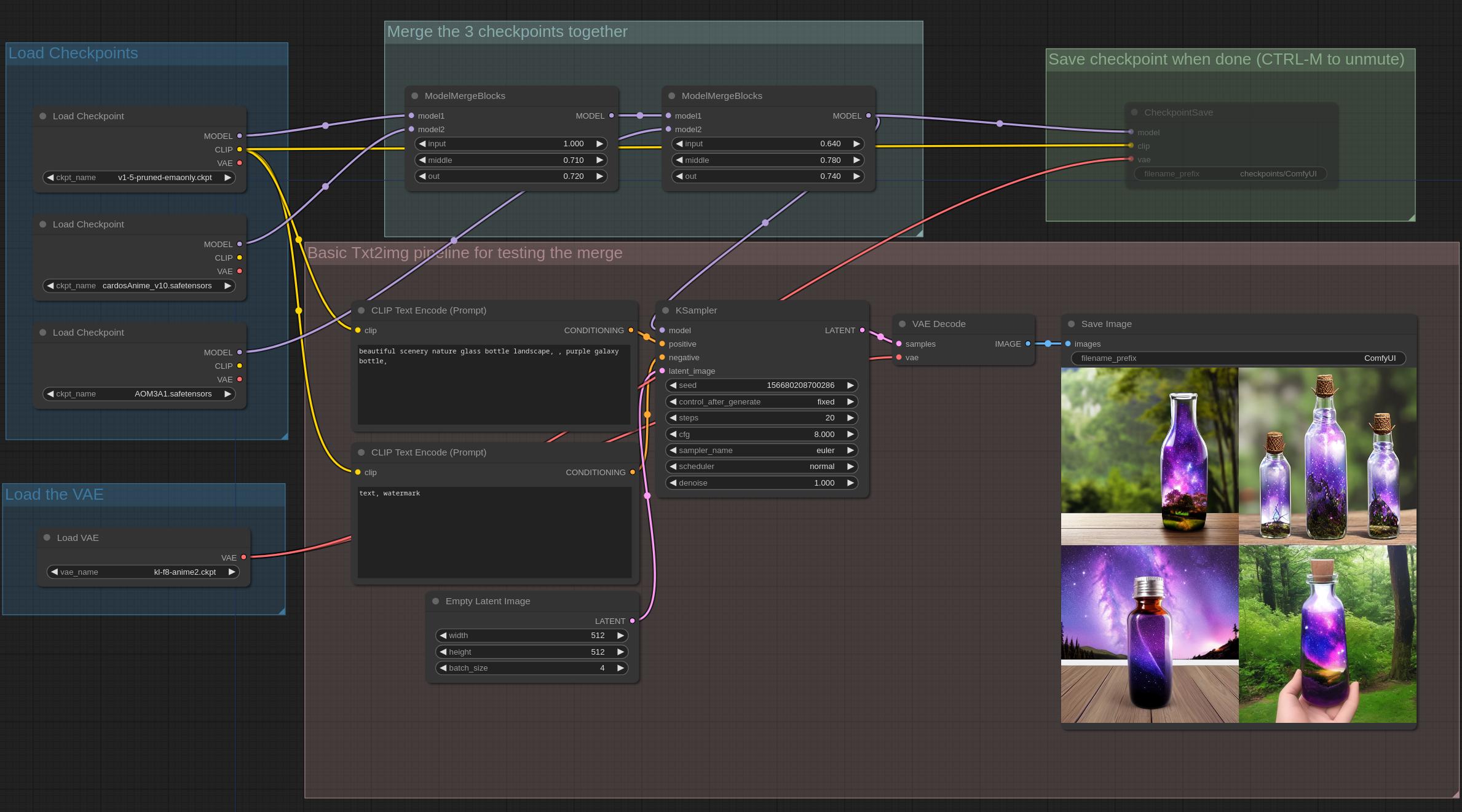
这个示例是使用简单块合并合并3个不同检查点的示例,其中unet的输入、中间和输出块可以有不同的比例:
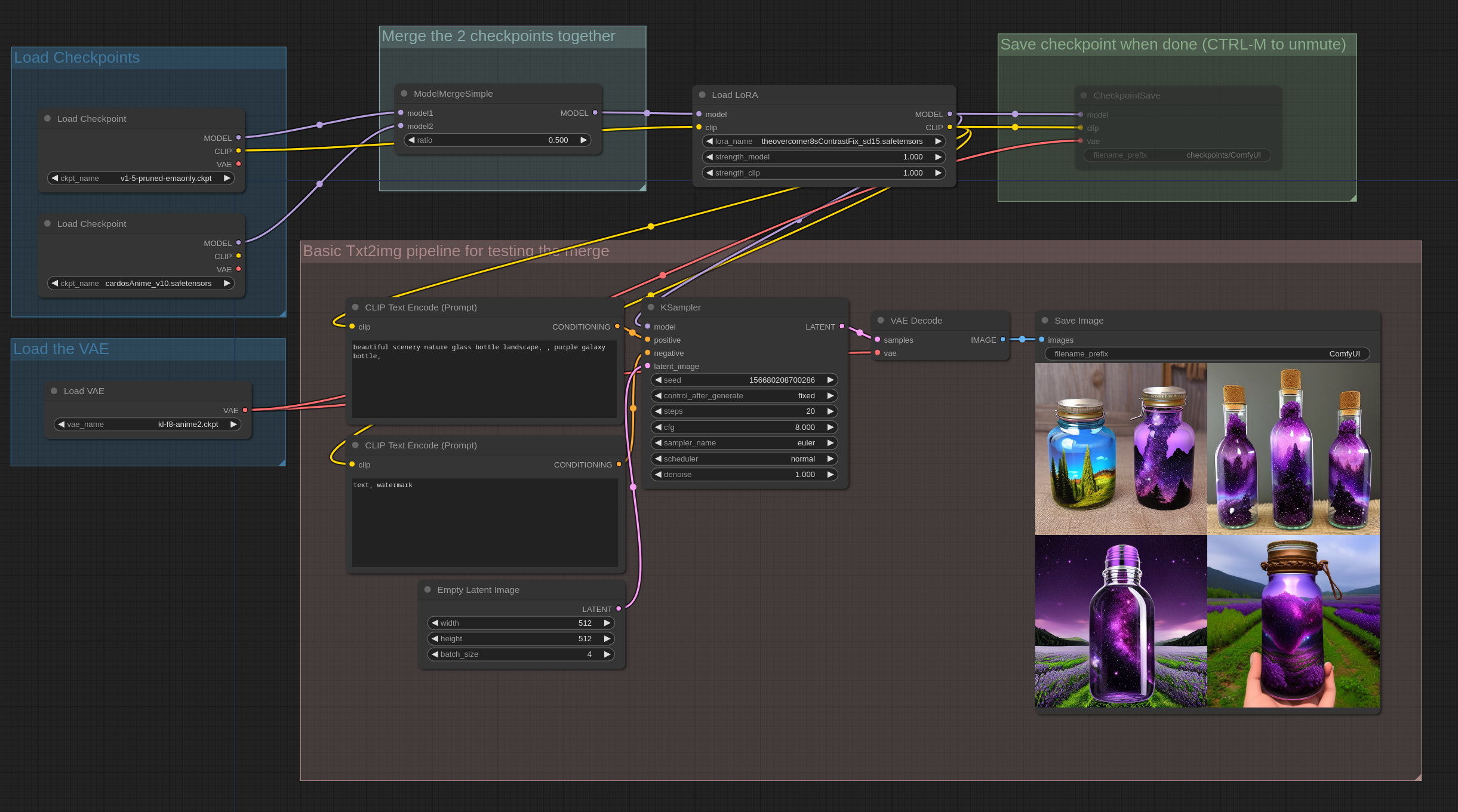
由于Loras是模型权重上的补丁,因此它们也可以合并到模型中:
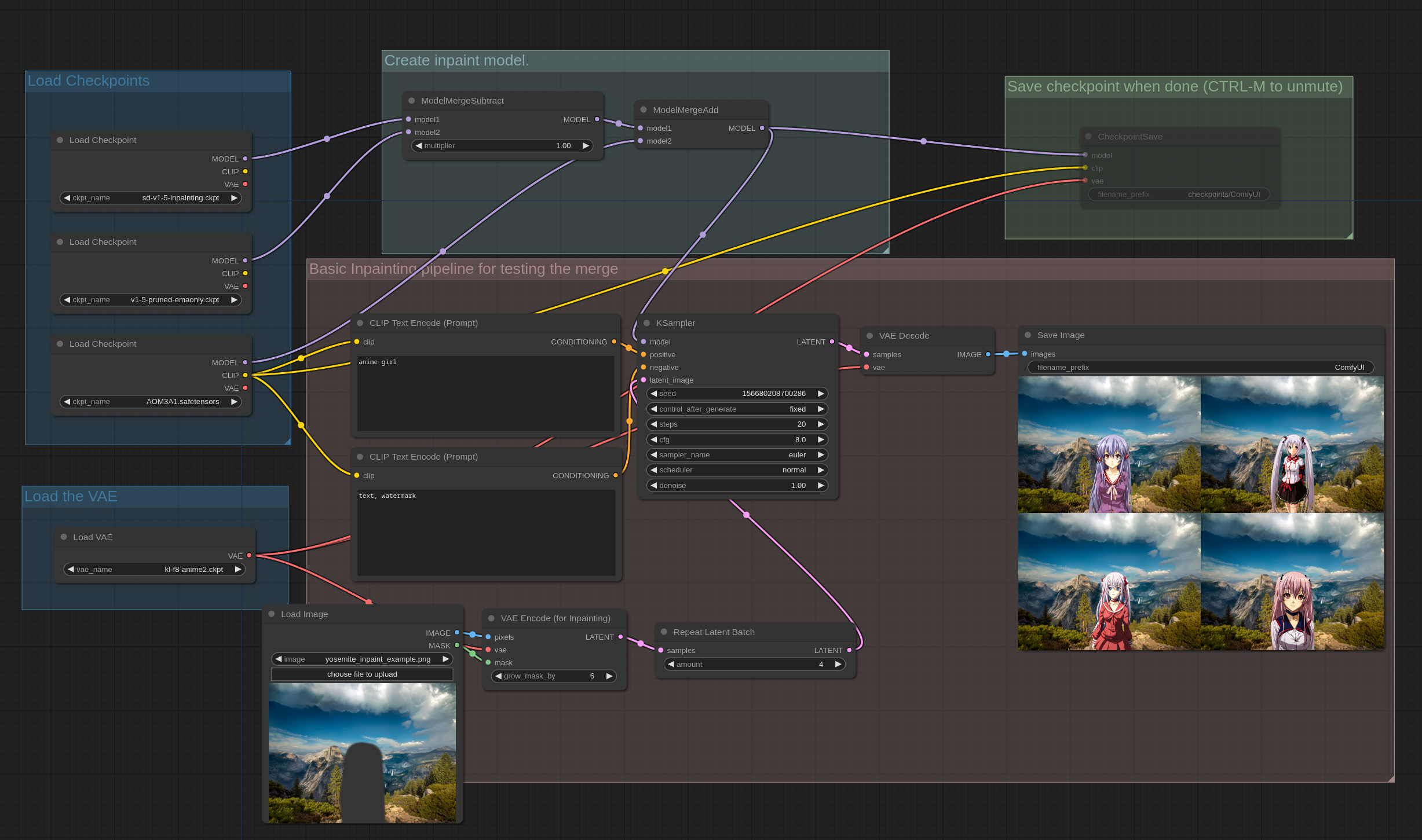
您还可以像在这个示例中一样减去模型权重并添加它们,用于从非修复模型创建修复模型,公式为:(inpaint_model - base_model) * 1.0 + other_model
如果您熟悉其他UI中的”Add Difference”选项,这就是在ComfyUI中执行它的方式。
您应该注意的一个重要事项是,模型会以用于硬件上的推理的精度合并和保存,因此通常是16位浮点。如果您想在32位浮点下进行合并,启动ComfyUI:—force-fp32
高级合并
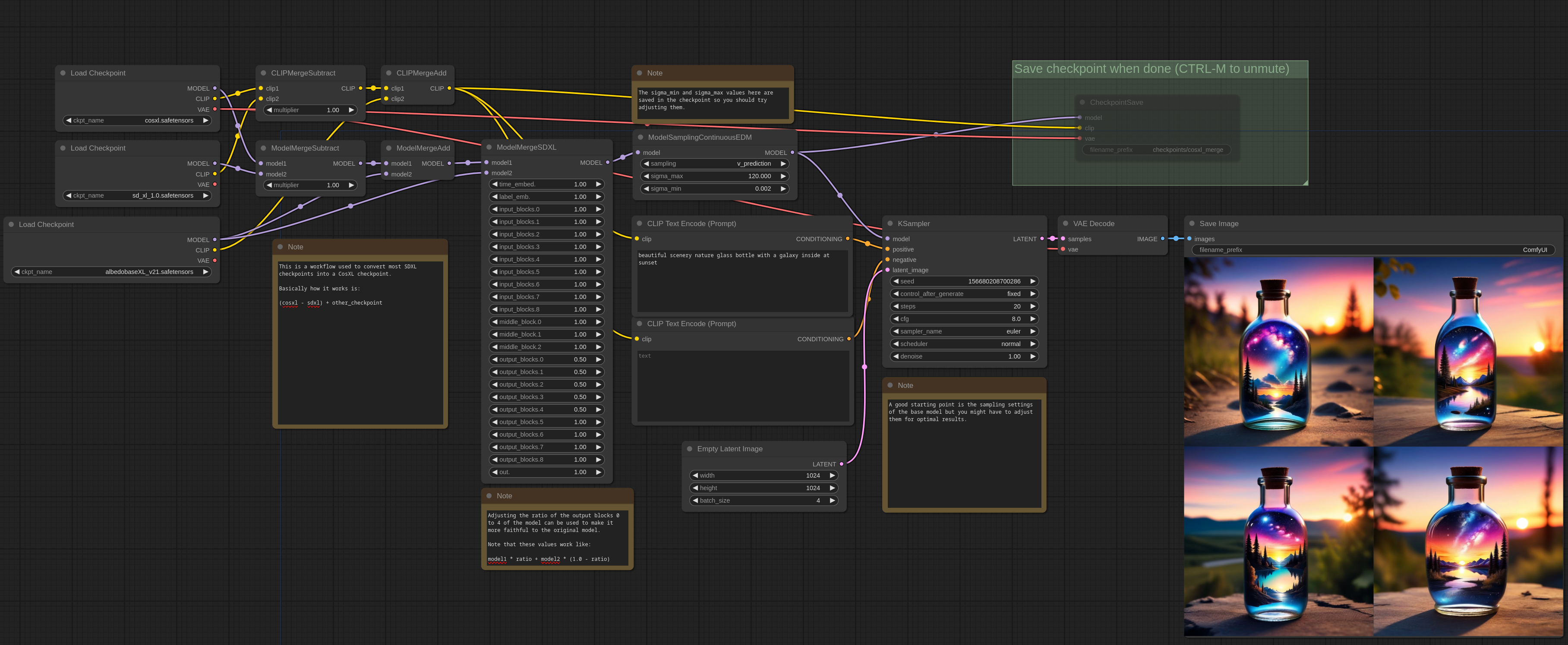
CosXL
以下是如何通过合并从常规SDXL模型创建CosXL模型的示例。要求是 CosXL基础模型,SDXL基础模型 和您想要转换的SDXL模型。在这个示例中,我使用了 albedobase-xl。
SDXL 示例
SDXL基础检查点可以在 ComfyUI 中像任何常规检查点一样使用。唯一重要的是,为了获得最佳性能,分辨率应设置为1024x1024或具有相同像素数量但不同宽高比的其他分辨率。 例如:896x1152或1536x640是好的分辨率。
使用基础和细化器的示例工作流程如下。您可以下载这张图片,然后加载到ComfyUI中或将其拖放到ComfyUI上以获取它。

您还可以像这个工作流程一样为基地和细化器提供不同的提示。

ReVision
ReVision非常类似于 unCLIP,但在更概念化的层面上表现。您可以传递一个或多个图像给它,它将从图像中获取概念,并使用它们作为灵感创建新图像。
首先下载 CLIP-G Vision 并将其放入您的ComfyUI/models/clip_vision/目录中。
这是一个可以拖放到ComfyUI中或加载到ComfyUI中的示例工作流程。在以下示例中,正面文本提示被清零,以便最终输出更紧密地跟随输入图像。
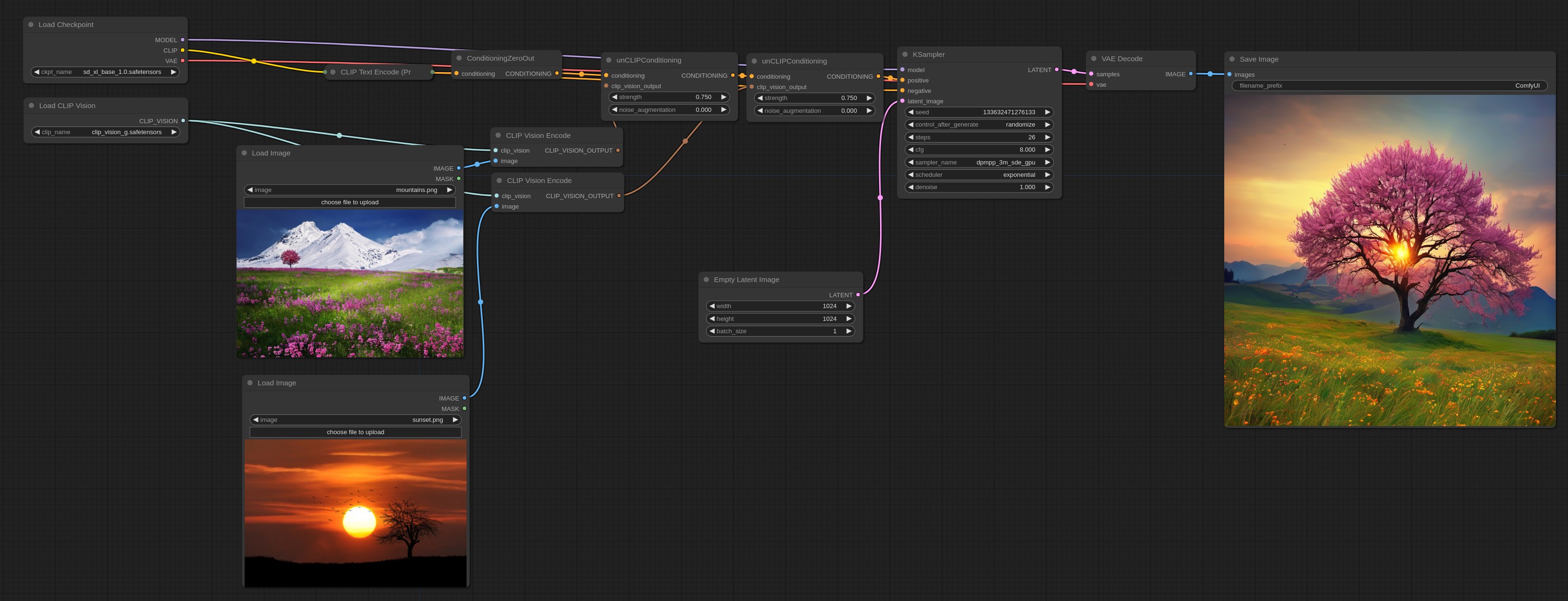
如果您想使用文本提示,可以使用这个示例:
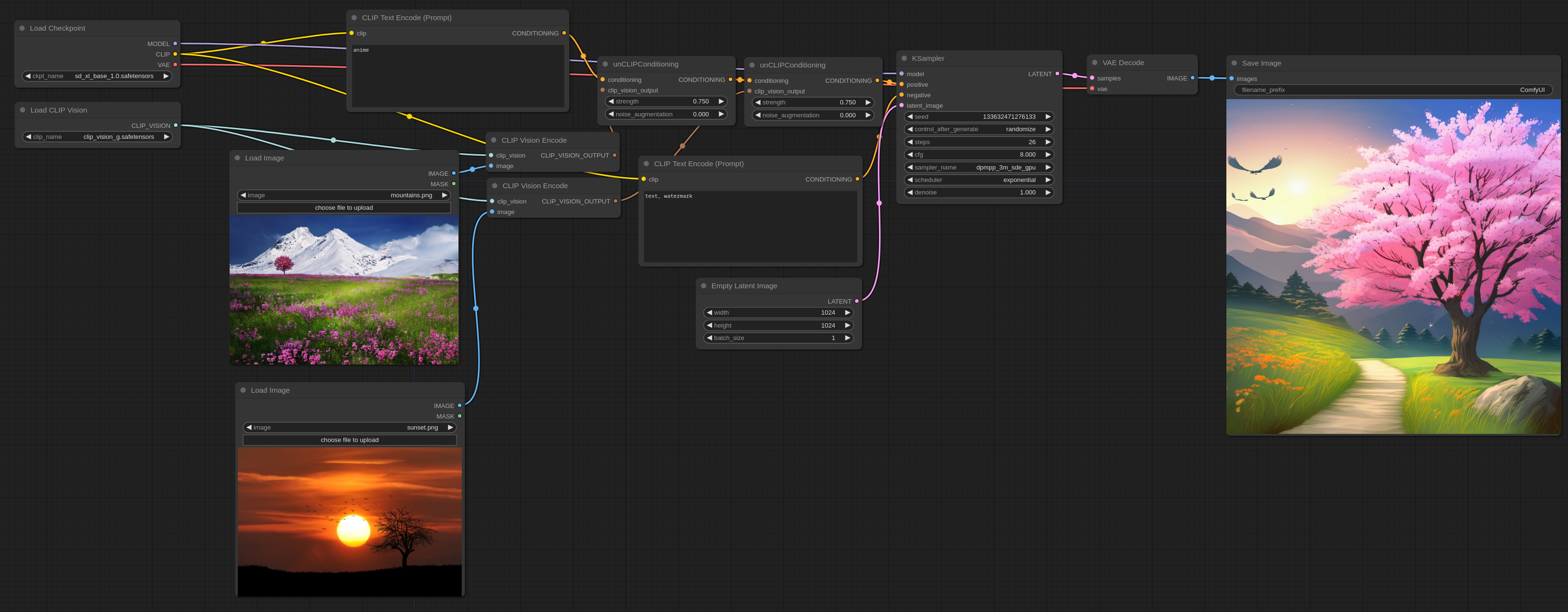
请注意,强度选项可以用来增加每个输入图像对最终输出的影响。它也可以通过使用单个unCLIPConditioning或像上面示例中那样链接多个一起使用,来处理任意数量的图像。
如果您需要它们,以下是上述工作流程的输入图像:


Stable Cascade 示例
首先下载 stable_cascade_stage_c.safetensors 和 stable_cascade_stage_b.safetensors 检查点 并将它们放入 ComfyUI/models/checkpoints 文件夹中。
Stable Cascade 是一个三阶段过程,首先使用 Stage C 扩散模型生成低分辨率潜在图像。然后使用 Stage B 扩散模型对这些潜在图像进行放大。最后,这个放大后的潜在图像再次放大并通过 Stage A VAE 转换为像素空间。
请注意,您可以下载本页上的所有图像,然后拖拽或加载到 ComfyUI 上以获取嵌入在图像中的工作流程。
文本到图像
这是一个基本的文本到图像工作流程:

图像到图像
以下是如何通过编码图像并将其传递给 Stage C 来执行基本图像到图像的示例:

图像变化
Stable Cascade 支持使用 CLIP vision 的输出创建图像的变化。以下工作流程是一个示例:

查看下一个工作流程,了解如何将多个图像混合在一起:

您可以在 unCLIP 示例页面 上找到上述工作流程的输入图像。
ControlNet
您可以从 这里 下载 Stable Cascade Controlnets。在这些示例中,我通过在文件名前面添加 stable_cascade_ 来重命名文件,例如:stable_cascade_canny.safetensors,stable_cascade_inpainting.safetensors
以下是如何使用 Canny Controlnet 的示例:

以下是如何使用 Inpaint Controlnet 的示例,示例输入图像可以在 这里 找到。提醒一下,您可以在 LoadImage 节点上右键单击图像并使用掩码编辑器编辑它们。

unCLIP模型示例
unCLIP模型是SD模型的版本,特别调整以接收图像概念作为输入,以及您的文本提示。图像是使用这些模型附带的CLIPVision进行编码的,然后由它提取的概念在采样时传递给主模型。
它基本上允许您在提示中使用图像。
以下是如何在ComfyUI中使用它(您可以将其拖放到ComfyUI中以获取工作流程):
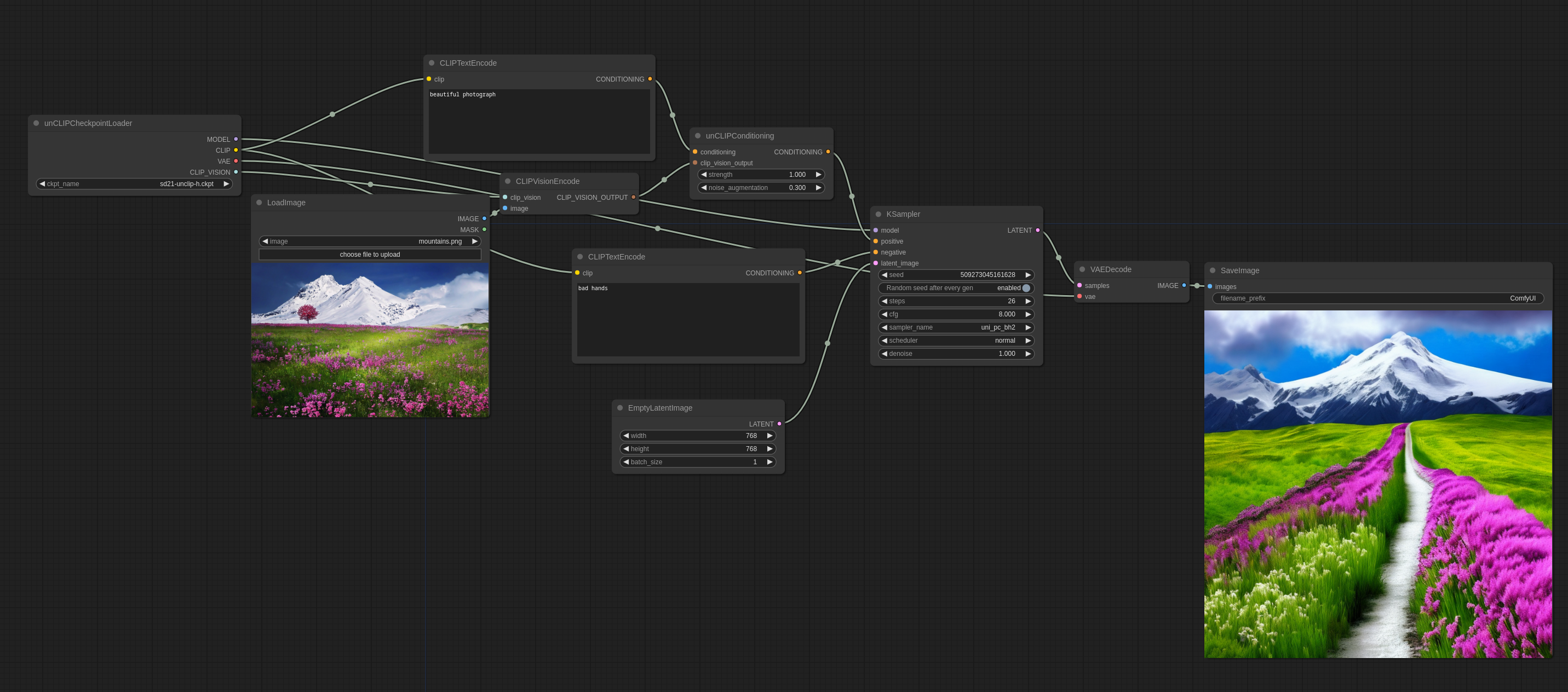
noise_augmentation控制模型将尝试遵循图像概念的紧密程度。值越低,它将越遵循概念。
strength是它将如何强烈地影响图像。
可以像这样使用多个图像:
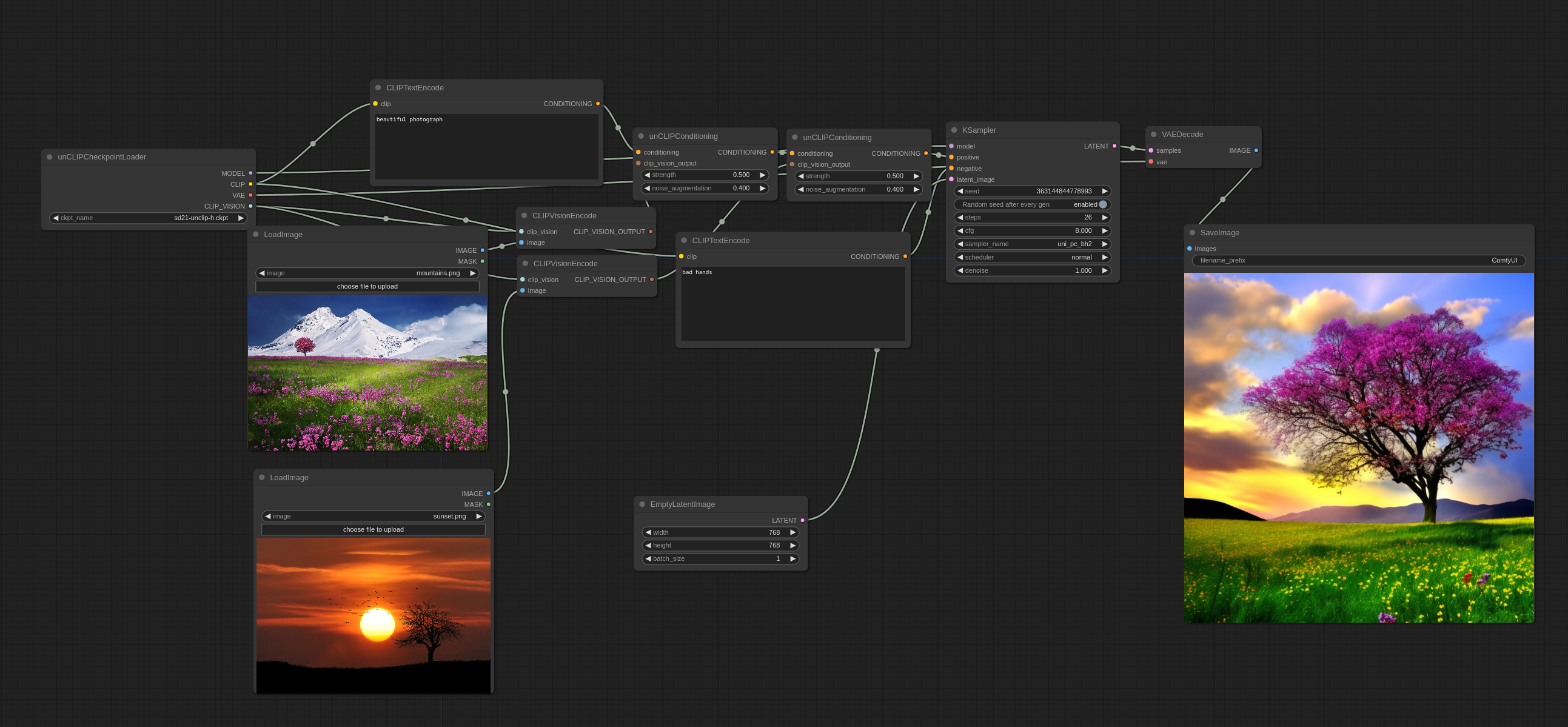
您会注意到它不会以传统意义上的方式混合图像,而是实际上从两个图像中挑选一些概念,并制作出一张连贯的图像。
输入图像:
您可以在这里找到官方unCLIP检查点
您可以在这里(基于WD1.5 beta 2)和这里(基于Illuminati Diffusion)找到我制作的一些基于现有768-v检查点的unCLIP检查点
更高级的工作流程
使用unCLIP检查点的一个好方法是将其用于两阶段工作流程的第一阶段,然后切换到1.x模型进行第二阶段。以下图像的生成方式如下。(您可以将其加载到ComfyUI中以获取工作流程)

超网络示例
你可以在 ComfyUI 中加载这些图像以获得完整的工作流程。
超网络是应用于主模型的补丁,因此要使用它们,将它们放入 models/hypernetworks 目录,并像这样使用超网络加载器节点:
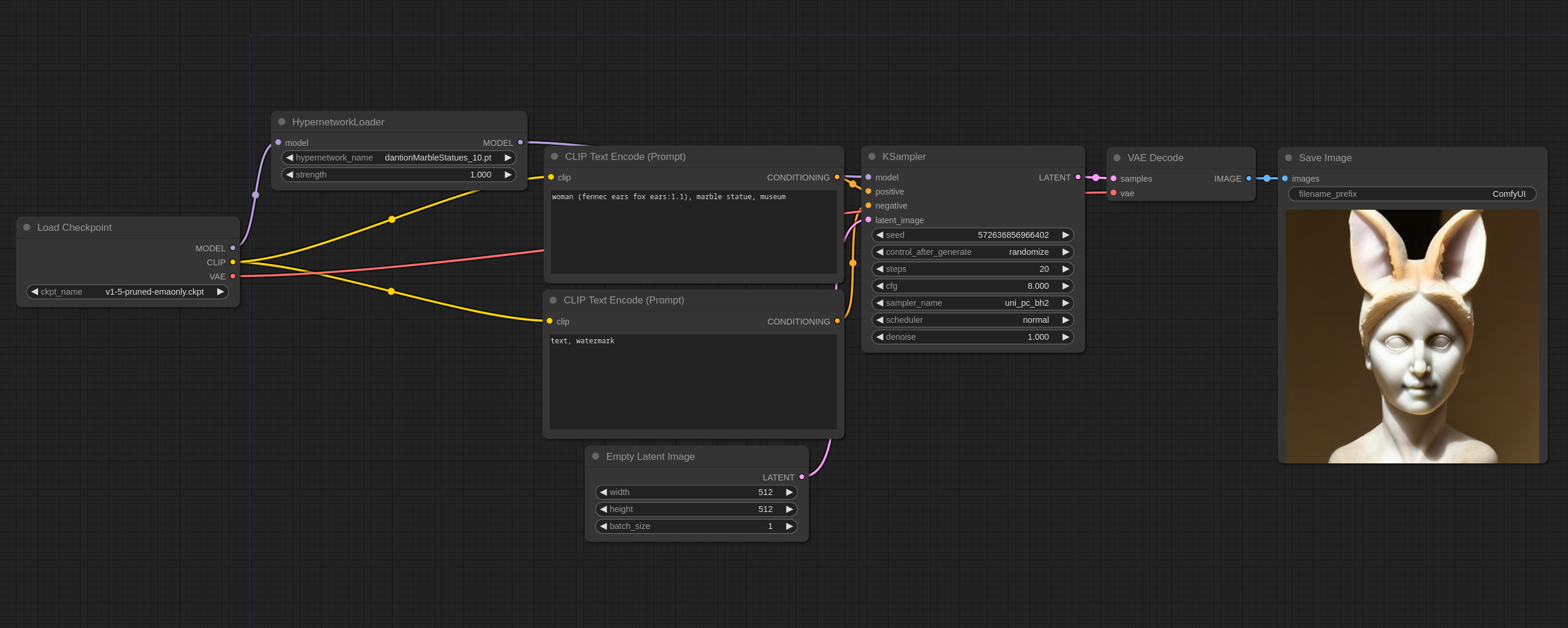
你可以通过顺序链接多个超网络加载器节点来应用多个超网络。
GLIGEN 示例
这是一个链接 下载支持的GLIGEN模型文件的精简版本
将GLIGEN模型文件放入ComfyUI/models/gligen目录中。
文本框GLIGEN
文本框GLIGEN模型允许您指定图像中多个对象的位置和大小。为了正确使用它,您应该正常编写您的提示,然后使用GLIGEN文本框应用节点来指定您希望提示中的某些对象/概念在图像中的位置。
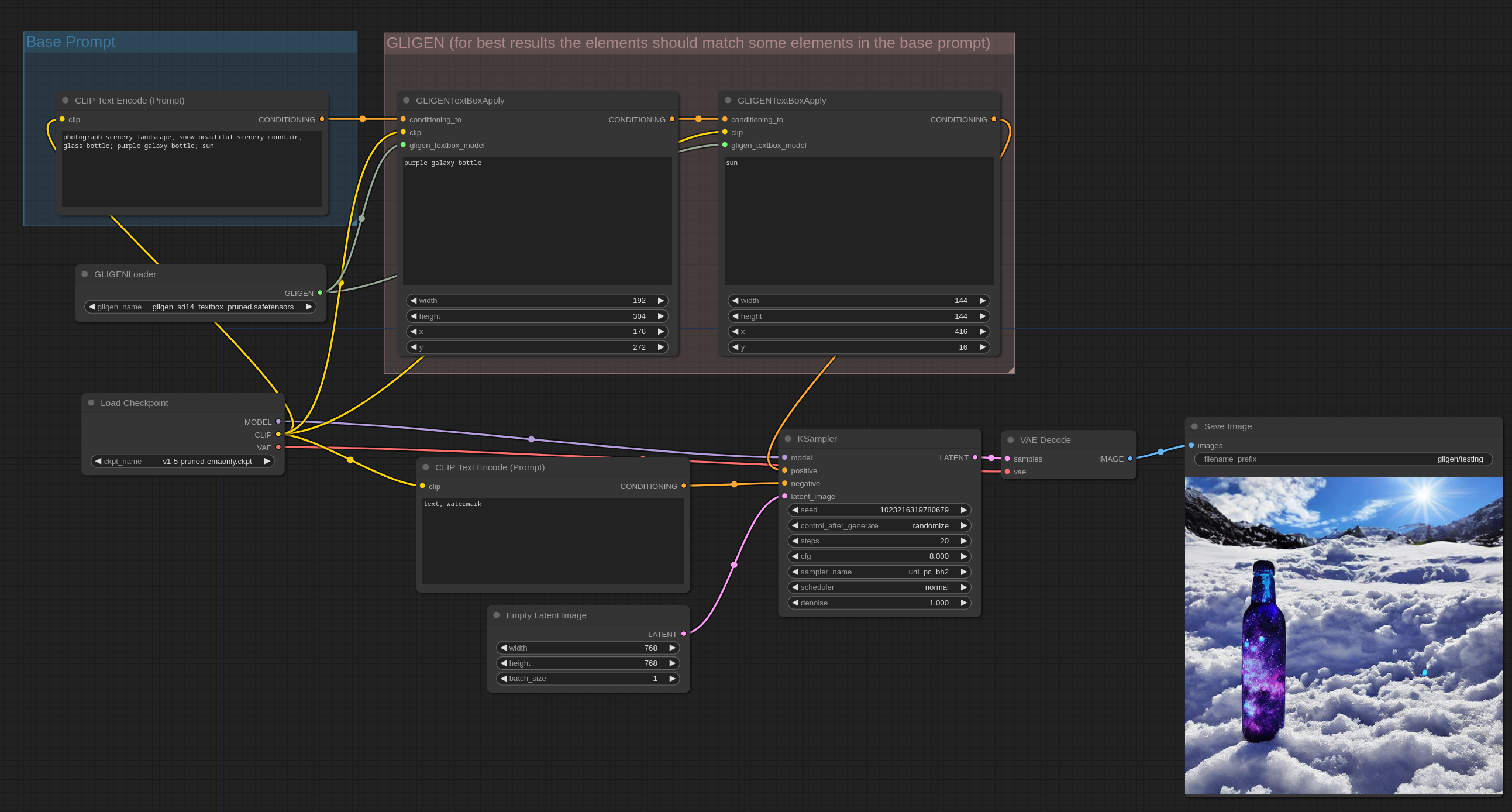
这是一个如何使用它的示例。您可以在ComfyUI中加载此图像以获取工作流程。
3D 示例 - ComfyUI工作流
Stable Zero123
Stable Zero123是一个扩散模型,它给定一个包含对象和简单背景的图像,可以从不同角度生成该对象的图像。
可以在这里下载对应的检查点达模型 将其放入 ComfyUI/models/checkpoints 文件夹中。
你可以下载这张图片并加载它,或者将其拖放到 ComfyUI 上以获取示例的工作流程。
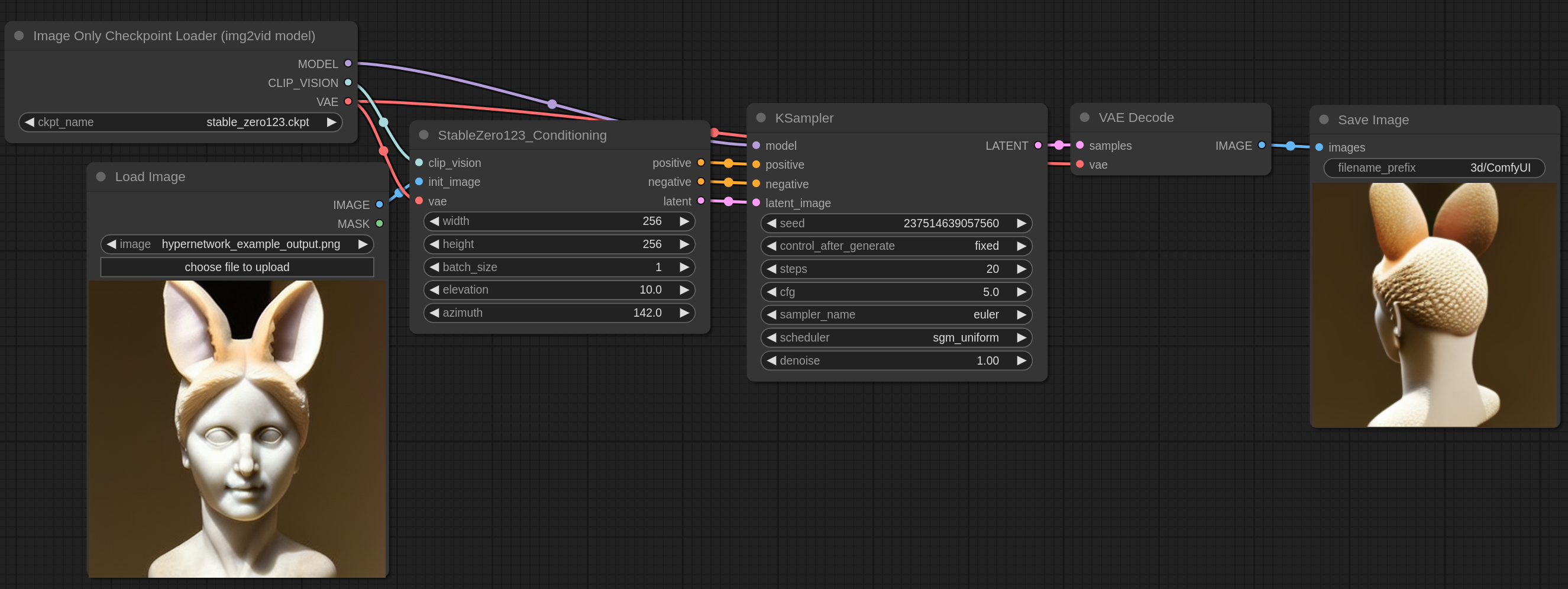
输入图像可以在 这里 找到,它是来自 超网络 示例的输出图像。
仰角(Elevation)和方位角(asimuth)是以度为单位的,控制对象的旋转。
视频示例
图像到视频
截至撰写本文时,有两个图像到视频检查点。以下是生成14帧视频的官方检查点 链接 和生成25帧视频的 链接。将它们放入 ComfyUI/models/checkpoints 文件夹中。
使用图像到视频模型的最基本方法是通过给它一个初始图像,如下所示的工作流程,该工作流程使用14帧模型。 您可以下载此 webp 动画图像并加载它或将其拖放到 ComfyUI 上以获取工作流程。

工作流程以 Json 格式
如果您想要确切的输入图像,可以在 unCLIP 示例页面 上找到它。
您也可以像这样使用工作流程,该工作流程使用 SDXL 生成一个初始图像,然后将其传递给25帧模型:

工作流程以 Json 格式
一些参数的解释:
video_frames:要生成的视频帧数。
motion_bucket_id:数字越高,视频中的动作就越多。
fps:fps 越高,视频就越不断断续续。
增强级别:添加到初始图像的噪声量,数字越高,视频看起来就越不像初始图像。增加它可以获得更多的动作。
VideoLinearCFGGuidance:这个节点对这些视频模型的采样略有改进,它的作用是在线性地跨不同帧缩放 cfg。在上面的示例中,第一帧将是 cfg 1.0(节点中的 min_cfg),中间帧是 1.75,最后一帧是 2.5(采样器中设置的 cfg)。这样,与初始帧相距较远的帧会逐渐获得更高的 cfg。
LCM 示例
LCM模型是特殊模型,旨在非常少的步骤中进行采样。
LCM Lora
LCM Lora是可以用来将常规模型转换为LCM模型的Lora。
LCM SDXL Lora可以从这里下载
下载它,将其重命名为:lcm_lora_sdxl.safetensors,然后放入你的ComfyUI/models/loras目录中。
然后你可以在ComfyUI中加载这张图片以获取工作流程,该工作流程展示了如何将LCM SDXL Lora与SDXL基础模型一起使用:

重要的部分是使用低cfg,使用“lcm”采样器和“sgm_uniform”或“simple”调度器。将ModelSamplingDiscrete节点的采样选项设置为lcm将略微提高结果,因此也推荐使用,但并非总是必要。
其他LCM Lora也可以在其各自的模型上以完全相同的方式使用。
SDXL Turbo 示例
SDXL Turbo是一个SDXL模型,能够在单步中生成一致的图像。您可以使用更多步骤来提高质量。使用它的正确方式是与新的SDTurboScheduler节点一起使用,但它也可能与常规调度器一起工作。
这是下载官方SDXL Turbo检查点的链接:官方SDXL Turbo检查点
以下是使用它的工作流程:

保存这张图片,然后在ComfyUI中加载它或将其拖放到ComfyUI上以获取工作流程。然后,我建议在界面中启用“额外选项” -> “自动队列”。然后按一次“队列提示”并开始编写您的提示。