ControlNet教程:在 ComfyUI 中使用 ControlNet 来进行精确的图像控制生成
在 AI 图像生成过程中,要精确控制图像生成并不是一键容易的事情,通常需要通过许多次的图像生成才可能生成满意的图像,但随着 ControlNet 的出现,这个问题得到了很好的解决。
ControlNet 提供了十几种控制网络模型,使得我们可以进一步开始控制图像的风格、细节、人物姿势、画面结构等等,这些限定条件让 AI 图像生成变得更加可控,在绘图过程中也可以同时使用多个 ControlNet 模型,以达到更好的效果。
你可以理解为 ContorlNet 是一个翻译的助手,把我们的参考图翻译成 AI 可以理解的指令,然后传递给 AI 模型,让 AI 模型生成符合我们要求的图像。

比如在这张图片中,通过输入一个人物的图片,通过预处理器提取出人物的控制条件后,然后通过 ControlNet 模型的应用,生成了动作一致的人物图片。
本篇教程将会涉及:
- ControlNet 的基础介绍
- ComfyUI 中 ControlNet 的工作流程
- ControlNet 的相关资源
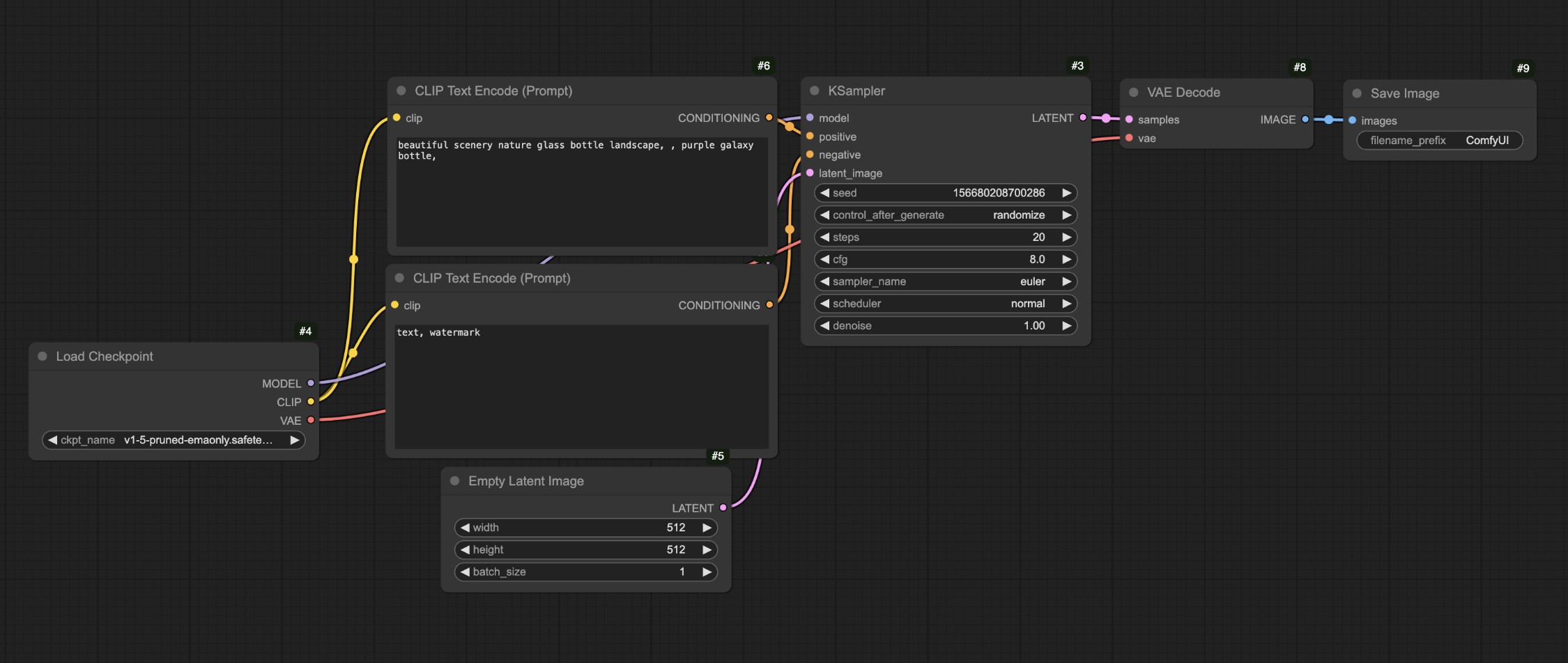
- 在 ComfyUI 中一个典型的 ControlNet 工作流的组成
然后我们会在 ComfyUI-Wiki 的其它 ControlNet 相关文章中具体说明具体单独的 ControlNet 模型如何使用及相关示例。
ControlNet 的简单介绍
ControlNet 是一种基于扩散模型(如 Stable Diffusion)的条件控制生成模型,最早由张吕敏(Lvmin Zhang)与 Maneesh Agrawala 等人于 2023 年提出。该模型通过引入多模态输入条件(如边缘检测图、深度图、姿势关键点等),显著提升了图像生成的可控性和细节还原能力。
下面是 ControlNet 相关的一些链接
- 作者主页:lllyasviel
- ControlNet 1.0:ControlNet
- ControlNet-v1-1-nightly:ControlNet-v1-1-nightly
- Hugging Face:ControlNet-v1-1
- 论文:ControlNext-to-Image Diffusion Models
ControlNet 的常见控制类型
随着这几年 ControlNet 的发展以及社区的贡献,目前 ControlNet 已经支持了十几种控制类型,下面是一些常见的控制类型,每种类型都有其适合的场景
1. 线条控制类
- Canny:通过边缘检测生成精细线稿,适合精准模仿原图结构。
- MLSD:仅检测直线,适用于建筑、室内设计等场景。
- Lineart:新一代线稿识别,比Canny更精细,支持动漫线条提取。
- SoftEdge:软边缘检测,优先识别大轮廓线,适合非精准模仿的场景。
- Scribble/Sketch:涂鸦控制,支持粗略轮廓识别或手动绘制草图生成图像。
2. 深度与结构类
- Depth:通过亮度区分前后景深度关系,白色区域靠前,黑色区域靠后。
- NormalMap:法线贴图,控制物体表面凹凸质感(如窗户凹陷效果)。
- OpenPose:骨骼姿势识别,可自动检测或手动编辑人体姿态。
3. 语义与分割类
- Segmentation:语义分割,通过颜色对应物品类别生成图像(如蓝色代表天空)。
- Inpaint/局部重绘:局部修改图像,保持与原图风格一致。
4. 风格与色彩类
- Shuffle:随机洗牌,打乱参考图语义元素生成多样性画面。
- Recolor:黑白图片重新上色,支持自动或提示词定义颜色。
- IP-Adapter:风格/人脸模仿,保持生成图像的一致性。
5. 功能扩展类
- InstructP2P:通过文本指令修改图片(如让房子“着火”)。
- Instant_ID:AI换脸,保持人脸一致性并支持多图融合。
- Tile/Blur:模糊图片高清化与细节增强。
不兼容OpenPose面部/手部专用处理器及部分语义分割预处理。
ComfyUI 中 ControlNet 的工作流程
在 ComfyUI 中,ControlNet 作为一种条件控制器,通常会涉及以下几个步骤的处理,当然由于目前ComfyUI 的 ControlNet 模型版本很多,所以具体的流程可能会有所不同,这里我们以目前 ControlNet V1.1 版本模型为例进行说明,具体工作流我们在后续的相关教程中继续补充
- 图片预处理
我们需要上传参考图,ControlNet 的预处理器会提取图中的关键特征(比如轮廓、线条、姿态)。例如本文开头的人物图片输入变成了 Openpose 的控制条件。
- 条件注入
ControlNet 将提取的特征转化为“条件信号”,传递给采样器(如 K 采样器)。这些信号会告诉 AI:“生成图片时,要尽量符合参考图的线条/姿势/结构”
- 采样器生成图像
采样器(如 K 采样器)在去噪生成图片的过程中,会参考 ControlNet 提供的条件信号,最终输出既符合文字描述、又与参考图特征匹配的图片。
ControlNet 工作流
不使用预处理器的 ControlNet 工作流
本部分将介绍一个典型的 SD1.5 ControlNet 工作流,不依赖任何第三方插件
1. 模型文件准备
为了使用这个工作流,请确保你已经安装以下内容
- 请前往下载 Dreamshaper 8 并保存在
ComfyUI/models/checkpoints/目录 - 请前往下载 control_v11p_sd15_openpose.pth 并保存在
ComfyUI/models/controlnet/目录
2. 工作流及相关素材
请点击下面的按钮下载对应的工作流,然后拖入 ComfyUI 界面或者使用菜单栏 Workflows -> Open(Ctrl+O) 进行加载
下面这张图片将作为参考图,请下载保存
3. 工作流运行
参照图片中的序号,依次完成对应操作以完成一个这个 ControlNet 工作流
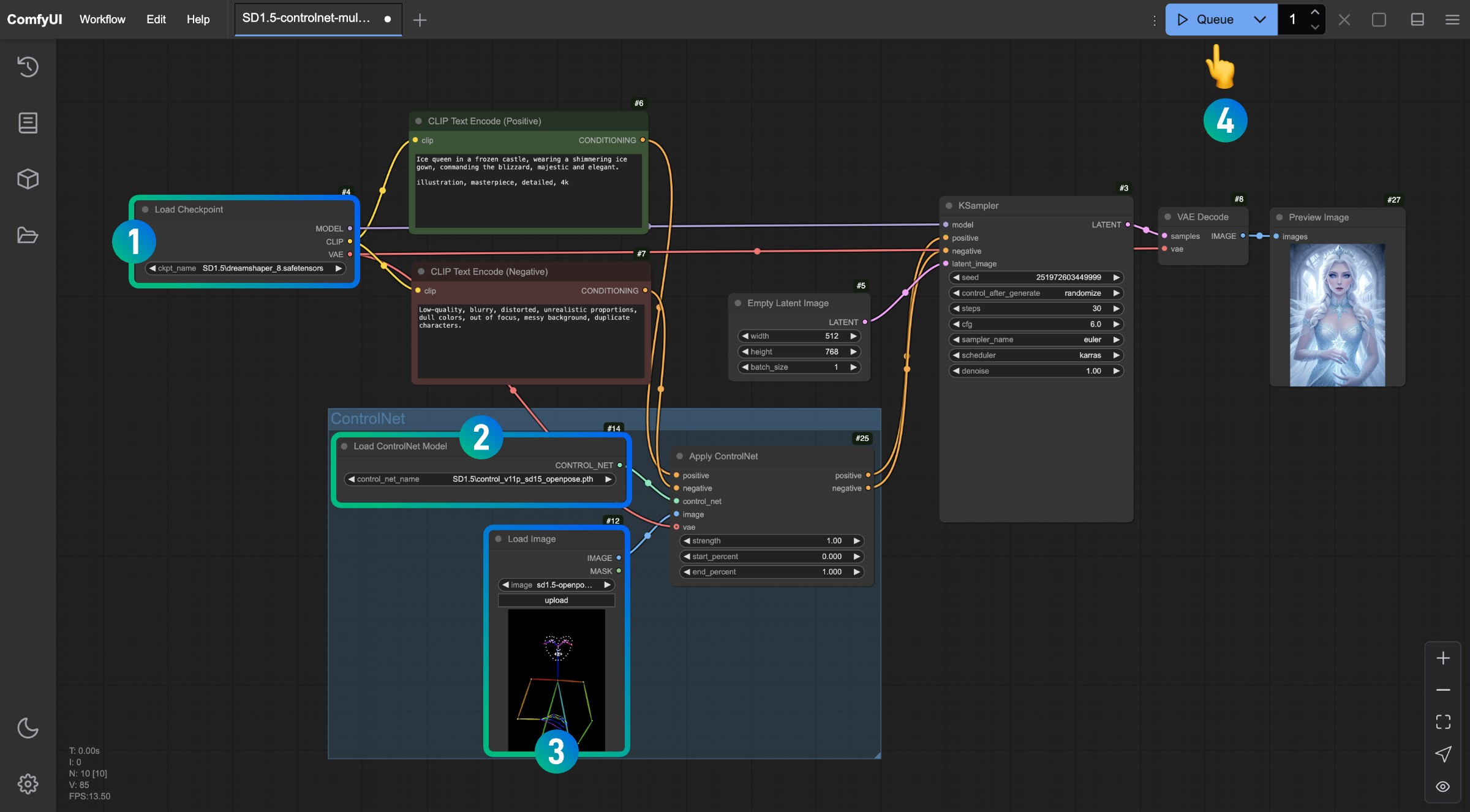
- 请确保在
Load Checkpoint节点里已经加载了 SD1.5 的模型 - 请确保在
Load ControlNet Model节点ontrol_v11p_sd15_openpose.pth模型可以被识别并加载 - 在
Load Image节点中加载上文提供的参考图 - 完成以上操作后点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来进行图片生成
试着调整Apply ControlNet节点的中的不同参数,进行生成,查看不同强度(Strength)和不同的起始比例(start_percent)和结束比例(end_percent)对生成结果的影响
4. 工作流讲解
在上面的流程中,我们把对应的工作流和我们的文生图工作流进行对比
你会发现最主要的差异就是在原本的文生图中,我们将对应的条件输入了 Apply ControlNet 节点通过这个节点我们增加了对应的控制条件,然后再将对应的输出条件输入到了KSampler节点的条件输入
你可以看到对应的人物很好地生成了,另外在 SD1.5 模型中常见的人物肢体错误的情况在这个工作流中也没有出现。
在完成以上操作后你可以尝试修改一下Empty Latent Image节点的尺寸,比如设置成512x512,然后再次生成来观察生成的画面和参考图的差异
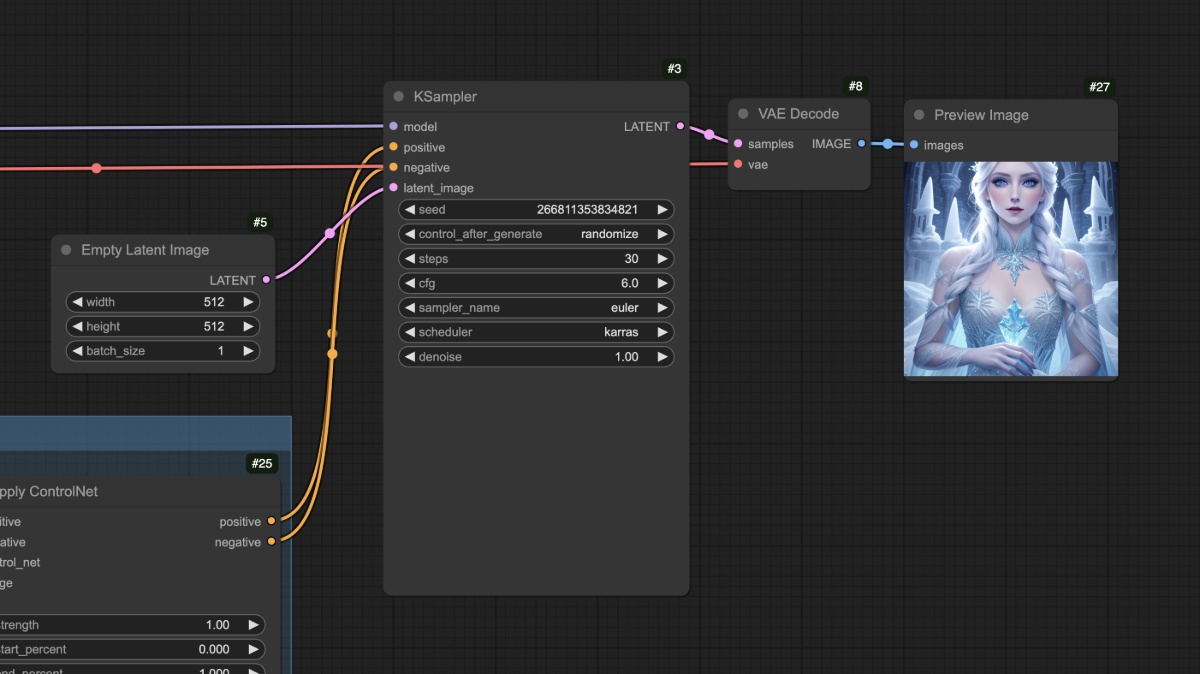
你应该可以看到最后生成的图像只使用了参考图的中心区域,另外不同类型的参考图也需要使用不同类型的 ControlNet 模型,比如 Openpose 就需要使用 control_v11p_sd15_openpose.pth 模型,而 Canny图就需要使用 control_v11p_sd15_canny.pth 模型。
在以上的工作流中,我们可能会有一个问题,我们使用的参考图(Openpose)并不是那么常见,那么我们是否可以采用其他的一些常见的参考图来生成对应的图片呢?这时候我们就需要用到预处理器,让我们接着在下一部分继续使用预处理器的工作流。
使用预处理器的 ControlNet 工作流
什么是预处理器呢?
比如在下面的图中,我们使用了 ComfyUI 的 Canny 预处理器,它把对应的图像的轮廓边缘特征提取出来了。
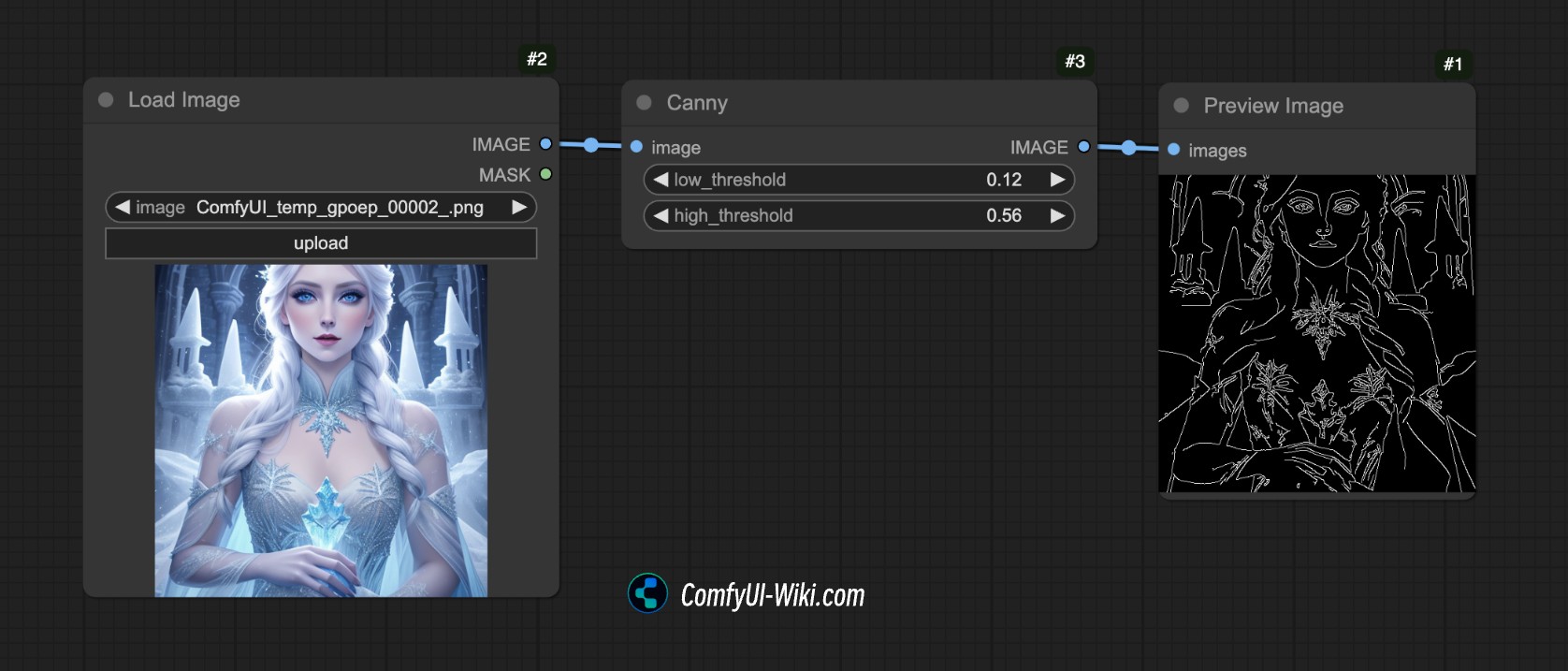
这就是预处理器的作用,它把我们提供的参考图(例如照片、线稿、涂鸦等)转换为一种 结构化的特征图,以便 ControlNet 模型能够理解并引导生成结果。
常见的预处理器有很多种比如:
- 线稿预处理器(如 canny、lineart):提取图像边缘轮廓,生成黑白线稿。
- 深度图预处理器(如 depth_midas):计算图像中物体的远近层次,生成灰度深度图。
- 姿势预处理器(如 openpose):识别人体骨骼关键点,生成火柴人骨架图。
但是在 ComfyUI 中,仅仅有 Canny 预处理器,所以我们需要依赖其它插件来完成图片预处理的工作,下面我们将进行对应工作流的内容。
1. 相关插件安装
本教程需要使用 ComfyUI ControlNet Auxiliary Preprocessors 插件
插件安装的教程可以参考 ComfyUI 插件安装教程
2. 模型文件准备
在这个示例中我们保持和之前的部分模型文件一致即可
- 请前往下载 Dreamshaper 8 并保存在
ComfyUI/models/checkpoints/目录 - 请前往下载 control_v11p_sd15_openpose.pth 并保存在
ComfyUI/models/controlnet/目录
3. 工作流及输入图片素材
下载下面的工作流文件
在运行 ComfyUI 后将工作流拖入或者使用 ComfyUI 的快捷键Ctrl+O 打开这个工作流文件
请下载下面的图片,并在 Load Image 节点中载入使用

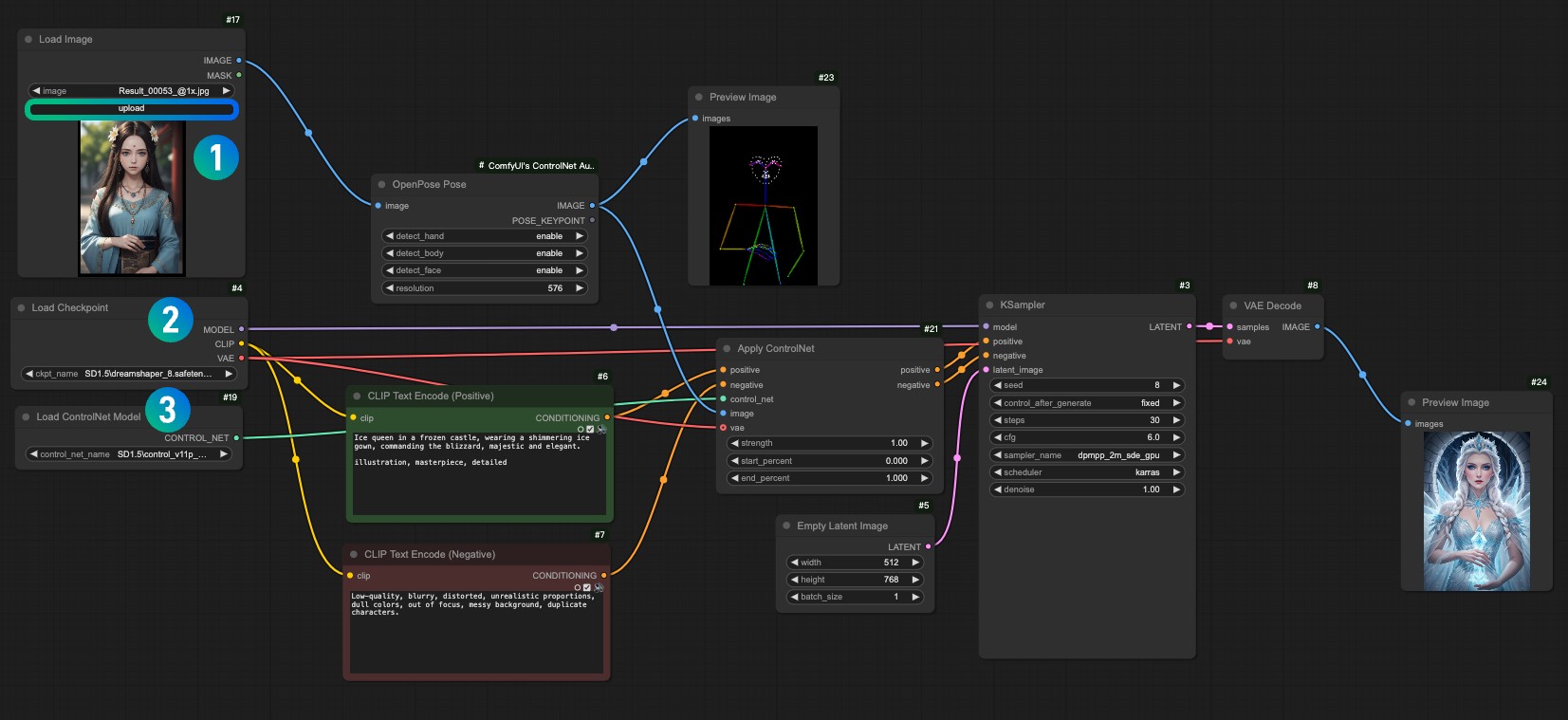
- 在
1Load Image 节点中载入输入图片 - 在
2Load Checkpoint 节点中选择你安装的模型 - 在
3Apply ControlNet 节点中选择control_v11f1p_sd15_openpose.pth模型。 - 使用 Queue 或者快捷键
Ctrl+Enter运行工作流进行图片生成
4. 工作流讲解
这个工作流和之前的工作流相比,其实就只是多了一部图像的预处理,我们把对应的图像输入到ComfyUI ControlNet Auxiliary Preprocessors 提供的预处理器OpenPose Pose节点中,完成了对应的图片预处理。
那么以上就是对应的 ComfyUI 中 ControlNet 的简单介绍了,在后续的 ControlNet 相关教程中,我们将会继续介绍更多的 ControlNet 模型,并给出对应的示例。
ComfyUI 中如何使用 Canny ControlNet SD1.5 模型 - 完整指南
SD1.5 Canny ControlNet 简介
 Canny ControlNet 是 ControlNet 模型中最常用的一种。它使用 Canny 边缘检测算法来提取图像中的边缘信息,然后利用这些边缘信息来引导 AI 生成图像。
Canny ControlNet 是 ControlNet 模型中最常用的一种。它使用 Canny 边缘检测算法来提取图像中的边缘信息,然后利用这些边缘信息来引导 AI 生成图像。
这篇教程是关于 SD1.5 模型的 Canny ControlNet 模型的使用
其它相关内容: ControlNet 模型安装使用教程汇总篇 ControlNet 模型下载地址
Canny ControlNet 主要特点
- 保持结构: 能够很好地保持原始图像的基本结构和轮廓
- 灵活性强: 可以通过调整边缘检测的参数来控制引导的强度
- 适用范围广: 适合素描、线稿、建筑设计等多种场景
- 效果稳定: 相比其他 ControlNet 模型,Canny 的引导效果更加稳定和可预测
本篇教程准备工作
1. 更新 ComfyUI 并安装必要模型
由于部分节点使用的是新的 ComfyUI 节点,所以需要先更新 ComfyUI 到最新版本
- 更新 ComfyUI 请参考 ComfyUI 更新教程
首先需要安装以下模型:
| 模型类型 | 模型文件 | 下载地址 |
|---|---|---|
| SD1.5 基础模型 | dreamshaper_8.safetensors | Civitai |
| Canny ControlNet 模型 | control_v11p_sd15_canny.pth | Hugging Face |
| VAE 模型(可选) | vae-ft-mse-840000-ema-pruned.safetensors | Hugging Face |
2. 模型存放位置
请按照以下结构放置模型文件:
3. SD1.5 Canny ControlNet 工作流文件下载
保存下面的图像到本地,在载入工作流后在 LoadImage 节点中选择加载这张图片

工作流说明
这个工作流主要包含以下几个部分:
- 模型加载部分: 加载 SD 模型、VAE 模型和 ControlNet 模型
- 提示词编码部分: 处理正面和负面提示词
- 图像处理部分: 包括图像加载和 Canny 边缘检测
- ControlNet 控制部分: 将边缘信息应用到生成过程
- 采样和保存部分: 生成最终图像并保存
关键节点说明
-
LoadImage: 用于加载输入图片
-
Canny: 进行边缘检测,有两个重要参数:
- low_threshold: 低阈值,控制边缘检测的敏感度
- high_threshold: 高阈值,控制边缘的连续性
-
ControlNetLoader: 加载 ControlNet 模型
-
ControlNetApplyAdvanced: 控制 ControlNet 的应用方式,包含以下重要参数:
- strength: 控制强度
- start_percent: 开始影响的时间点
- end_percent: 结束影响的时间点
使用步骤
-
导入工作流
- 下载本篇教程的工作流文件
- 在 ComfyUI 中点击 “Load”,或者直接将下载后的 JSON 文件拖入 ComfyUI 中
-
准备输入图片
- 准备一张你想要处理的图片
- 使用 LoadImage 节点加载图片
-
调整 Canny 参数
- low_threshold 建议范围: 0.2-0.5
- high_threshold 建议范围: 0.5-0.8
- 可以通过 PreviewImage 节点实时预览边缘检测效果
-
设置生成参数
- 在 KSampler 节点中:
- steps: 建议 20-30
- cfg: 建议 7-8
- sampler_name: 推荐使用 “dpmpp_2m”
- scheduler: 推荐使用 “karras”
- 在 KSampler 节点中:
-
调整 ControlNet 强度
- strength: 1.0 表示完全跟随边缘信息
- 可以根据需要降低 strength 值来减弱控制
使用技巧和建议
-
边缘检测参数调整
- 如果边缘太多: 提高 threshold 值
- 如果边缘太少: 降低 threshold 值
- 建议先通过 PreviewImage 预览效果
-
提示词编写
- 正面提示词要详细描述你想要的风格和细节
- 负面提示词要包含你想避免的元素
- 提示词要与原始图片的内容相关
-
常见问题解决
- 如果生成图像过于模糊: 增加 cfg 值
- 如果边缘跟随不够: 增加 strength 值
- 如果细节不够: 增加 steps 值
相关资源
ControlNet 模型下载 更多 ControlNet 教程
ComfyUI 中如何使用 Depth ControlNet SD1.5 模型 - 完整指南
SD1.5 Depth ControlNet 简介

Depth ControlNet 是一个专门用于控制图像深度和空间结构的 ControlNet 模型。它通过分析输入图像的深度信息,帮助 AI 在生成新图像时保持正确的空间关系和透视效果。这个模型在室内设计、建筑设计和场景重构等领域特别有用,因为它能够准确理解和保持空间的深度信息。
这篇教程专注于 SD1.5 模型的 Depth ControlNet 模型的使用方法和技巧,其它版本和类型的模型的 ControlNet 教程我们会在后续继续补充。
Depth ControlNet 主要特点
- 空间控制: 精确控制图像的空间深度和透视关系
- 场景重构: 能够保持原始场景的空间布局,同时改变风格和内容
- 室内设计: 特别适合室内场景的重新设计和风格转换
- 建筑可视化: 对建筑和室内设计的 3D 效果展示特别有效
- 产品展示: 适合创建具有深度感的产品展示效果
- 场景规划: 帮助进行景观设计和城市规划的可视化
SD1.5 Depth ControlNet工作流准备工作
1. 安装必要插件
由于 ComfyUI Core 并不带有对应的 Depth 图像预处理器,所以需要预先下载对应的预处理器插件 本教程需要使用 ComfyUI ControlNet Auxiliary Preprocessors 插件来生成深度图。
这里比较推荐使用 ComfyUI Manager 来进行安装 插件安装的教程可以参考 ComfyUI 插件安装教程 这个部分说得比较详细了
最新版本 ComfyUI Desktop 已经预装 ComfyUI Manager 插件了
方式一:使用 ComfyUI Manager(推荐)
- 先安装 ComfyUI Manager
- 在 Manager 中搜索并安装 “ComfyUI ControlNet Auxiliary Preprocessors”
方式二:通过 git 安装必要插件
- 打开命令行,使用 cd 命令进入 ComfyUI 的 custom_nodes 目录
- 执行以下命令:
注意:安装完插件后需要重启 ComfyUI
方式三:手动安装(不推荐)
1.访问 https://github.com/Fannovel16/comfyui_controlnet_aux
2. 下载对应的代码仓库的代码的 ZIP 包含
3. 复制解压后的文件到 ComfyUI/custom_nodes/ 文件夹下
2.1 下载工作流所需模型
首先需要安装以下模型:
| 模型类型 | 模型文件 | 下载地址 |
|---|---|---|
| SD1.5 基础模型 | dreamshaper_8.safetensors | Civitai |
| Depth ControlNet 模型 | control_v11f1p_sd15_depth.pth | Hugging Face |
| VAE 模型(可选) | vae-ft-mse-840000-ema-pruned.safetensors | Hugging Face |
SD1.5 版本的模型可以使用你自己电脑上的模型,只是作者我在这篇教程中我使用的是 dreamshaper_8 这个模型作为示例,如果是室内设计等场���,你应该选择专门为室内或建筑设计优化训练过的模型
2.2 模型存放位置
请按照以下结构放置模型文件:
3. 工作流文件
室内设计是 Depth ControlNet 最常见的应用场景之一。通过深度信息的控制,可以保持原有空间布局的同时,完全改变室内的风格和氛围。
以下是一个将传统客厅转换为赛博朋克风格的示例:


SD1.5 Depth ControlNet 工作流说明
主要组件
本工作流使用了以下关键节点:
- LoadImage: 加载输入图像
- Zoe-DepthMapPreprocessor: 生成深度图,这是由 ComfyUI ControlNet Auxiliary Preprocessors 插件提供的节点
- resolution: 控制深度图的分辨率,这个参数会影响深度图的精细程度:
- 较大分辨率(如 768, 1024):
- 优点:能够捕捉多细节,对于复杂的室内场景和建筑效果更好
- 缺点:处理速度较慢,占用更多显存
- 适用场景:精细的室内设计、建筑细节重现
- 较小分辨率(如 384, 512):
- 优点:处理速度快,显存占用少
- 缺点:可能丢失一些细节信息
- 适用场景:快速预览、简单场景重构
- 建议设置:
- 一般场景:512 是较好的平衡点
- 细节要求高:768 或更高
- 快速测试:384
- 较大分辨率(如 768, 1024):
- 使用 Zoe 深度估计算法,能够生成高质量的深度图
- 特别适合室内场景和建筑场景
- 可以通过 PreviewImage 节点预览生成的深度图
- resolution: 控制深度图的分辨率,这个参数会影响深度图的精细程度:
提示:建议先用较低的 resolution 进行测试和调整,确定其他参数后再提高 resolution 进行最终生成
提示:Zoe-DepthMapPreprocessor 是目前最适合建筑和室内场景的深度图生成器之一,它能够很好地处理复杂的空间结构和细节
工作流节点说明
本工作流的主要节点连接说明:
-
输入部分:
- LoadImage → Zoe-DepthMapPreprocessor → PreviewImage (用于预览深度图)
- LoadImage → Zoe-DepthMapPreprocessor → ControlNetApplyAdvanced
-
模型加载部分:
- CheckpointLoaderSimple (加载基础模型)
- ControlNetLoader (加载 Depth ControlNet)
-
提示词处理部分:
- CLIPTextEncode (处理正面提示词)
- CLIPTextEncode (处理负面提示词)
-
生成控制部分:
- KSampler (控制生成过程)
- VAEDecode (将潜空间图像转换为最终图像)
Depth ControlNet 使用技巧与最佳实践
-
深度图质量控制
- 使用高质量的输入图像
- 确保图像有清晰的空间层次
- 避免过于复杂的场景
- 注意光线对深度图的影响
-
提示词编写
- 详细描述空间关系
- 包含材质和光照信息
- 明确指出重要的深度元素
- 使用专业术语提升生成质量
- 推荐的关键词:
- 空间词: depth, perspective, spatial layout, composition
- 质量词: professional, high quality, detailed, realistic
- 风格词: modern, minimalist, futuristic (根据需求选择)
-
常见问题解决
- 空间感不足:增加 strength 值
- 细节丢失:适当降低 cfg 值
- 结构变形:增加 steps 值
- 深度不准:调整 resolution 值
- 风格不对:优化提示词描述
常见问题(FAQ)
-
为什么生成的图像空间感不强?
- 检查深度图是否清晰
- 确认 strength 值是否足够高
- 考虑增加 steps 值
-
如何提高生成图像的质量?
- 使用更高的 resolution
- 选择合适的采样器
- 优化提示词描述
-
生成速度太慢怎么办?
- 降低 resolution
- 使用更快的采样器
- 减少采样步数
-
如何保持原始图像的布局?
- 增加 strength 值
- 保持 end_percent 为 1
- 使用更详细的空间描述
相关资源
- ControlNet 模型下载
- 更多 ControlNet 教程
ComfyUI 中如何使用 OpenPose ControlNet SD1.5 模型
SD1.5 OpenPose ControlNet 简介
OpenPose ControlNet,是一个专门用于控制图像中人物姿态的 ControlNet 模型。它通过分析输入图像中的人物姿态,帮助 AI 在生成新图像时保持正确的人物姿态。这个模型在人物图像生成、动漫生成、游戏角色生成等情况下都有比较好的效果,因为它能够准确理解和保持人物的姿态。
这篇教程专注于 SD1.5 模型的 OpenPose ControlNet 模型的使用方法和技巧,其它版本和类型的模型的 ControlNet 教程我们会在后续继续补充。
OpenPose ControlNet 使用
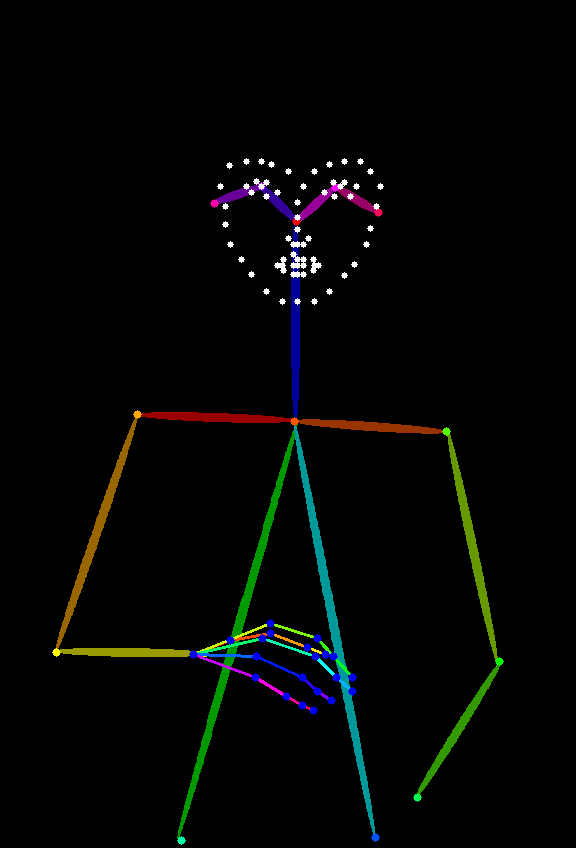
OpenPose ControlNet 的使用需要使用 OpenPose 图来来控制人物姿态的控制,然后使用 OpenPose ControlNet 模型来控制生成图像中的人物姿态,对应 OpenPose 图效果如下:
和 Depth 图一样,你可以使用 ComfyUI ControlNet Auxiliary Preprocessors 插件来生成 OpenPose 图,如果你不想安装这个插件,也可以使用类似open-pose-editor 这样的在线工具来生成 OpenPose 图用于姿态控制。 这里还是建议非常推荐安装 ComfyUI ControlNet Auxiliary Preprocessors 插件的 ,因为在后续日常的使用中,这个插件功能会被频繁使用。
使用 OpenPose ControlNet 的 Step by Step 教程
1. 升级 ComfyUI
由于本文使用的相关节点是新的 Apply ControlNet 与老的节点有所不同,所以建议你先升级或安装最新版本的 ComfyUI 相关教程你可以参考:
- ComfyUI 安装教程
- ComfyUI 更新教程
2. 安装必要插件
由于 ComfyUI Core 并不带有对应的 OpenPose 图像预处理器,所以需要预先下载对应的预处理器插件 本教程需要使用ComfyUI ControlNet Auxiliary Preprocessors 插件来生成 OpenPose 图。
这里比较推荐使用 ComfyUI Manager 来进行安装 插件安装的教程可以参考 ComfyUI 插件安装教程 这个部分说得比较详细了
最新版本 ComfyUI Desktop 已经预装 ComfyUI Manager 插件了
3. 下载工作流所需模型
首先需要安装以下模型:
| 模型类型 | 模型文件 | 下载地址 |
|---|---|---|
| SD1.5 基础模型 | dreamshaper_8.safetensors | Civitai |
| OpenPose ControlNet 模型 | control_v11f1p_sd15_openpose.pth(必须) | Hugging Face |
4. 模型存放位置
请按照以下结构放置模型文件:
安装完成后刷新或者重启 ComfyUI 让程序读取对应的模型文件
5. 工作流文件
这里提供了两个工作流文件
使用 OpenPose 图和 ControlNet 模型来进行图片生成
下载上面的工作流,在运行 ComfyUI 后将工作流拖入或者使用 ComfyUI 的快捷键Ctrl+O 打开这个工作流文件
请下载下面的图片,并在 Load Image 节点中载入使用
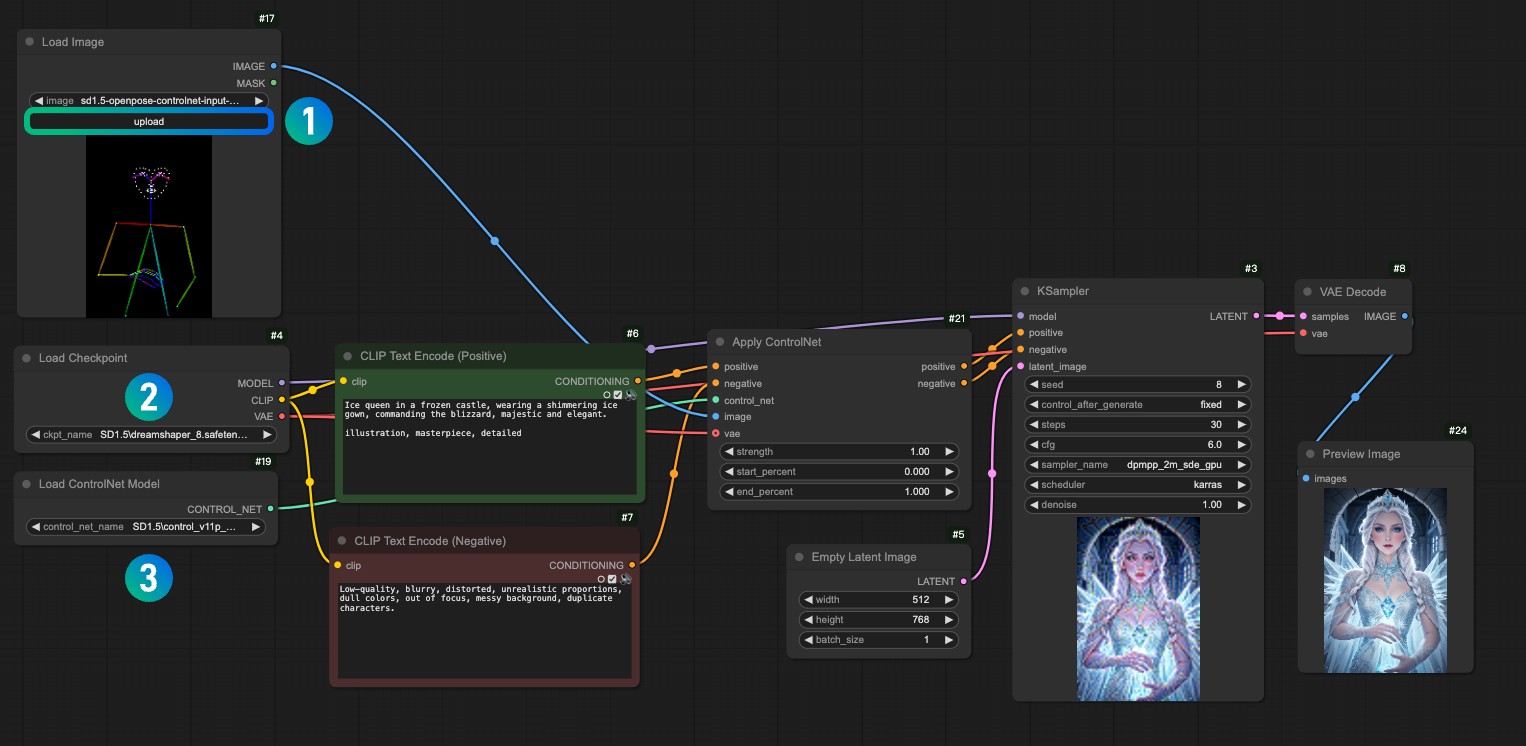
- 在
1Load Image 节点中载入参考图片 - 在
2Load Checkpoint 节点中选择你安装的模型 - 在
3Apply ControlNet 节点中选择control_v11f1p_sd15_openpose.pth模型。 - 使用 Queue 或者快捷键
Ctrl+Enter运行工作流进行图片生成
使用ComfyUI ControlNet Auxiliary Preprocessors 对参考图片进行预处理
和上面一个工作流有所差异,在有些情况下我们并不一定有现成的 OpenPose 图,那么就需要使用 ComfyUI ControlNet Auxiliary Preprocessors 插件来对参考图片进行预处理,然后使用处理后的图片作为输入图片与 ControlNet 模型一起使用
下载上面的工作流,在运行 ComfyUI 后将工作流拖入或者使用 ComfyUI 的快捷键Ctrl+O 打开这个工作流文件
请下载下面的图片,并在 Load Image 节点中载入使用
- 在
1Load Image 节点中载入输入图片 - 在
2Load Checkpoint 节点中选择你安装的模型 - 在
3Apply ControlNet 节点中选择control_v11f1p_sd15_openpose.pth模型。 - 使用 Queue 或者快捷键
Ctrl+Enter运行工作流进行图片生成
5.1 涉及的主要节点说明
ComfyUI Core 节点,核心节点文档在当前网站文档已有对应说明
- 应用ControlNet节点: Apply ControlNet
- 加载 ControlNet 模型: ControlNet Loader
5.2 ComfyUI ControlNet Auxiliary Preprocessors 节点
关于 Pose 检测的节点,这里提供了两种不同的节点,分别是 OpenPose Pose 节点和 DWPose Estimator 节点他们的作用都是从图像中提取手部、身体、面部姿态信息并生成骨架图
DWPose Estimator 节点是基于 DWPose 的姿态检测算法,OpenPose Pose 节点是基于 OpenPose 的姿态检测算法,在我提供的工作流中我是用的是 OpenPose Pose 节点,你可以在运行成功后试试 DWPose Estimator 节点,看看差异

OpenPose Pose 节点
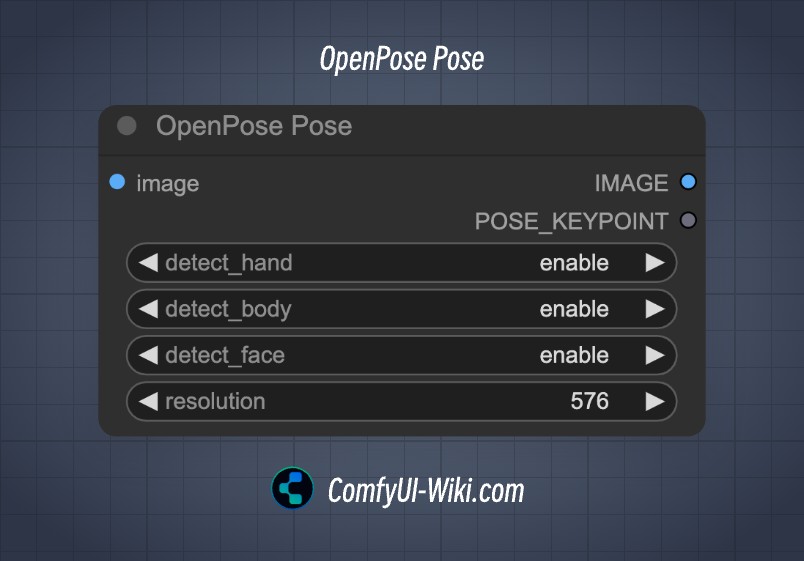
| 输入参数 | 描述 | 参数选项 |
|---|---|---|
| images | 输入图像 | - |
| detect_hand | 是否检测手部 | enable / disable |
| detect_face | 是否检测面部 | enable / disable |
| detect_body | 是否检测身体 | enable / disable |
| resolution | 输出图像的分辨率 | - |
| 输出参数 | 描述 | 参数选项 |
|---|---|---|
| image | 从图像处理后输出的图像 | - |
| POSE_KEYPOINT | 骨架点 | - |
DWPose Estimator 节点

| 输入参数 | 描述 | 参数选项 |
|---|---|---|
| images | 输入图像 | - |
| detect_hand | 是否检测手部 | enable / disable |
| detect_face | 是否检测面部 | enable / disable |
| detect_body | 是否检测身体 | enable / disable |
| resolution | 输出图像的分辨率 | - |
| bbox-detector | 是否检测人体框在图像中的文职 | enable / disable |
| pose_estimator | pose 检测的不同方法 | - |
| 输出参数 | 描述 | 参数选项 |
|---|---|---|
| image | 从图像处理后输出的图像 | - |
| POSE_KEYPOINT | 骨架点 | - |
相关资源
- ControlNet 模型下载
- 更多 ControlNet 教程
ComfyUI 中多个 ControlNet组合使用教程
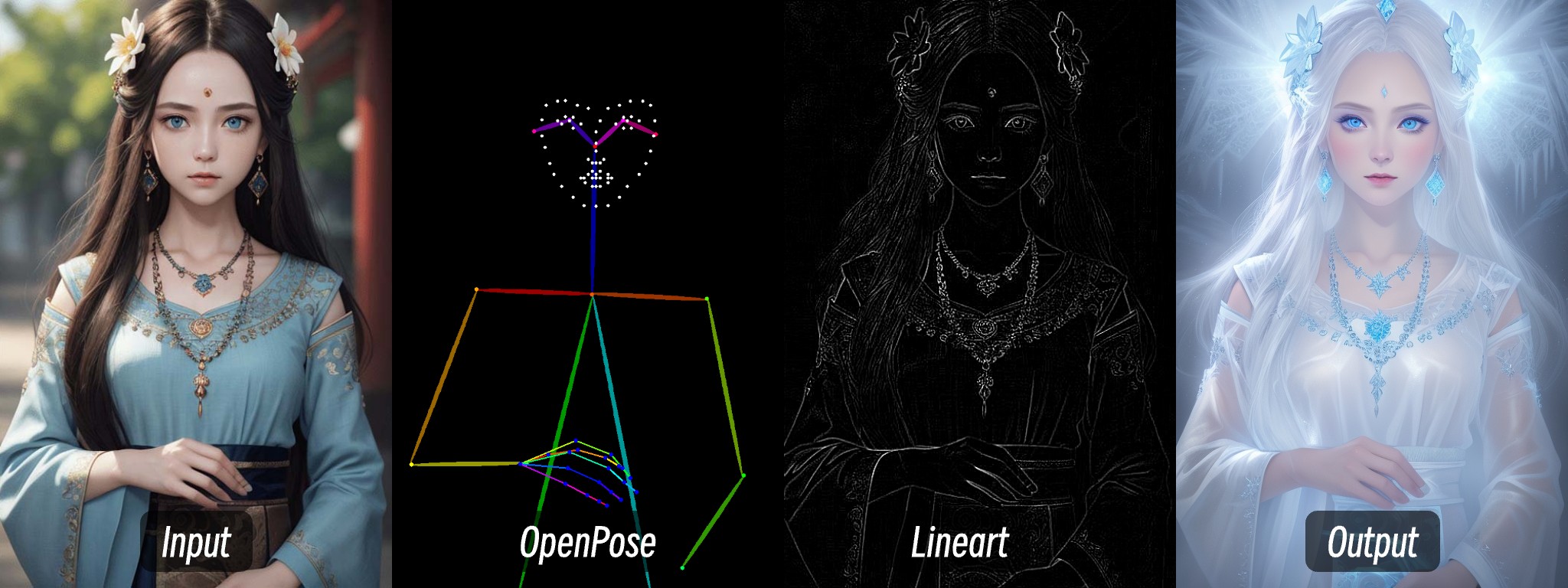 在 ControlNet 中,多个 ControlNet 可以组合使用,以实现更精准的控制的,比如在生成人物时,如果出现人物肢体错位,则可以叠加 depth 来保证正确的肢体前后关系。
在 ControlNet 中,多个 ControlNet 可以组合使用,以实现更精准的控制的,比如在生成人物时,如果出现人物肢体错位,则可以叠加 depth 来保证正确的肢体前后关系。
这篇文章里,我将会使用 OpenPose 和 Lineart 来实现画面风格的转变。
- OpenPose 用于控制人物姿态
- Lineart 用于控制人物服饰和面部特征等特点保持一致
其实主要是在使用多个 ControlNet 的时候将 Apply ControlNet 节点的条件串联
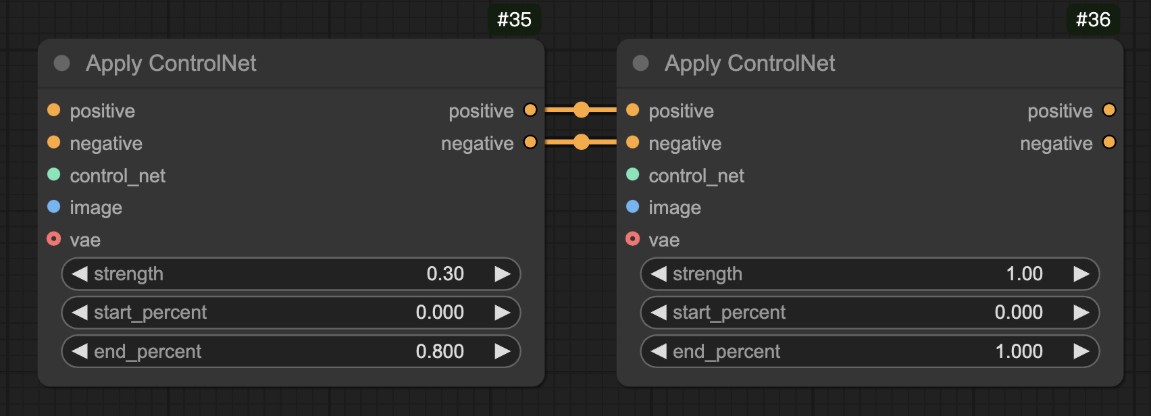 关于 ControlNet 的阶段控制等可以参考 Apply ControlNet 节点使用说明
关于 ControlNet 的阶段控制等可以参考 Apply ControlNet 节点使用说明
ComfyUI 中使用多个 ControlNet 的步骤
1. 安装必要插件
如果你学习过ComfyUI Wiki之前的其它教程,那么你应该有安装好了对应的插件,则这个步骤你可以忽略
由于 ComfyUI Core 并不带有对应的 Depth 图像预处理器,所以需要预先下载对应的预处理器插件 本教程需要使用 ComfyUI ControlNet Auxiliary Preprocessors 插件来生成深度图。
这里比较推荐使用 ComfyUI Manager 来进行安装 插件安装的教程可以参考 ComfyUI 插件安装教程 这个部分说得比较详细了
最新版本 ComfyUI Desktop 已经预装 ComfyUI Manager 插件了
2. 下载模型
首先需要下载以下模型:
| 模型类型 | 模型文件 | 下载地址 |
|---|---|---|
| SD1.5 基础模型 | dreamshaper_8.safetensors(可选) | Civitai |
| OpenPose ControlNet 模型 | control_v11f1p_sd15_openpose.pth(必须) | Hugging Face |
| Lineart | control_v11p_sd15_lineart.pth(必须) | Hugging Face |
SD1.5 版本的模型可以使用你自己电脑上的模型,只是我在这篇教程中我使用的是 dreamshaper_8 这个模型作为示例
请按照以下结构放置模型文件:
3. 工作流文文件,以及输入图片
下载下面的工作流文件和图片文件

4. 在 ComfyUI 中导入工作流加载图片用于生成
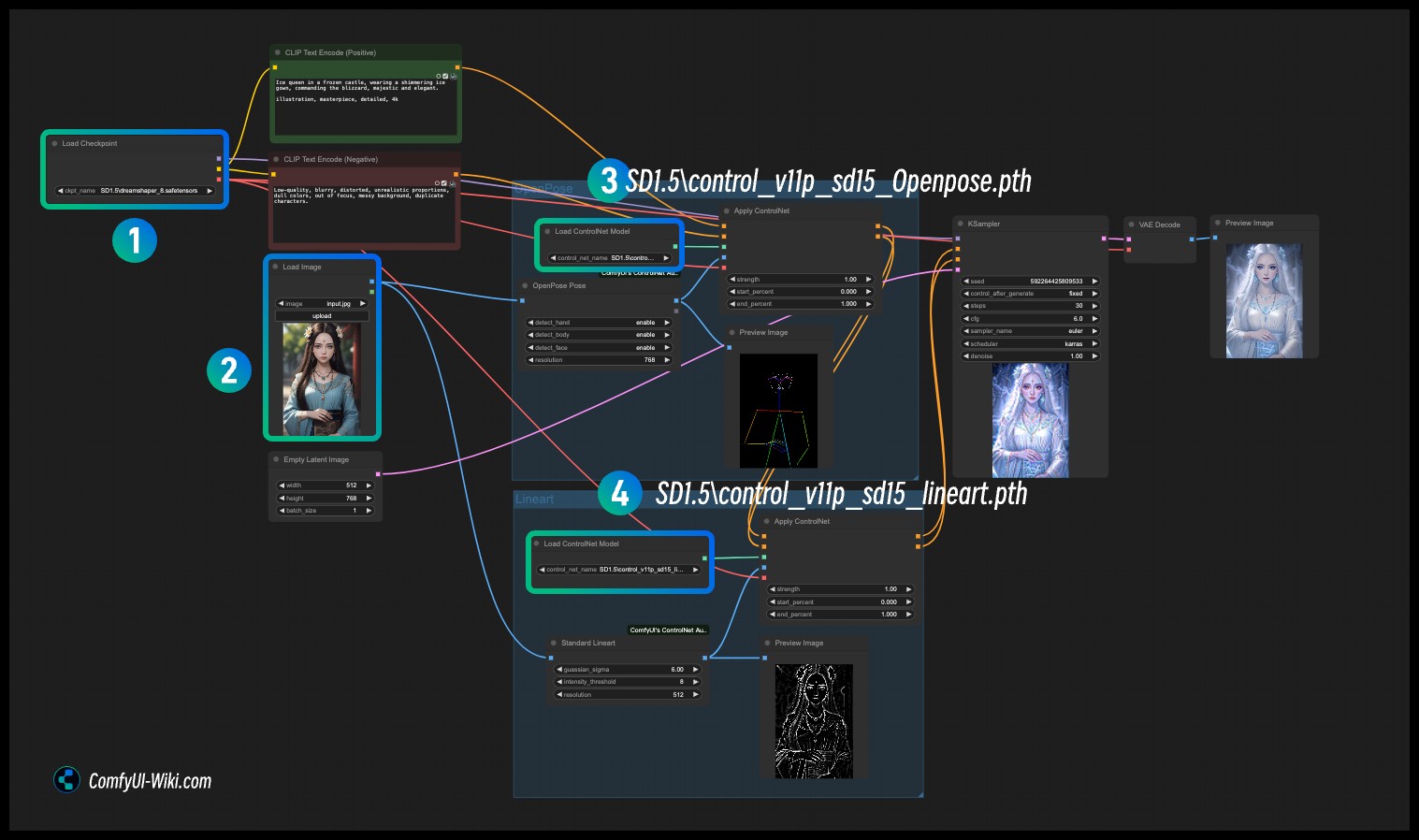
- 在序号
1加载对应的 SD1.5 Checkpoint 模型 - 在序号
2Load Image 加载输入图片 - 在序号
3加载 OpenPose ControlNet 模型 - 在序号
4加载 Lineart ControlNet 模型 - 使用 Queue 或者快捷键
Ctrl+Enter运行工作流进行图片生成
ComfyUI Sonic 工作流,数字人视频生成
Sonic 是腾讯开源的数字人模型,仅需要输入图片及音频即可输出不错的视频效果,
下面是原始 Sonic 相关的链接 项目页面:https://jixiaozhong.github.io/Sonic/ 在线体验:http://demo.sonic.jixiaozhong.online/ 项目源码:https://github.com/jixiaozhong/Sonic
最近已有社区用户完成了对应的插件集成,本教程基于 ComfyUI_Sonic 插件,复现 Sonic 的官方示例效果。
1. ComfyUI Sonic插件安装
此工作流依赖下面的插件,请确保在开始前已经完成了插件及依赖安装或下载工作流后使用 ComfyUI-manager 安装缺失节点
ComfyUI_Sonic: https://github.com/smthemex/ComfyUI_Sonic ComfyUI-VideoHelperSuite: https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
如果你不熟悉对应的安装,请参考ComfyUI 插件安装教程完成对应插件的安装
2. Sonic 相关模型的下载及安装
在插件仓库作者有提供了对应的插件下载,如果对应下面对应的模型链接失效或无法访问,请访问插件作者仓库查看是否有更新
模型需要保存的位置如下,请将下载到的模型保存到对应的位置:
2.1 Stable video diffusion 下面两个模型选择一个:
svd_xt_1_1.safetensors https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1/tree/main svd_xt_1_1.safetensors https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1/tree/main
2.2 下载 Sonic 相关模型
访问下面的网盘地址,并下载文件夹内所有的资源 sonic相关模型: https://drive.google.com/drive/folders/1oe8VTPUy0-MHHW2a_NJ1F8xL-0VN5G7W
2.3 下载 whisper-tiny 模型
whisper-tiny https://huggingface.co/openai/whisper-tiny/tree/main
仅下载下面三个文件
- config.json
- model.safetensors
- preprocessor_config.json
ComfyUI Sonic 工作流相关素材
请下载下面的音频、照片、以及工作流文件,或者使用你自己的素材
图片:

音频,请下载示例部分的任意音频: https://github.com/smthemex/ComfyUI_Sonic/tree/main/examples/wav
ComfyUI Sonic 工作流讲解
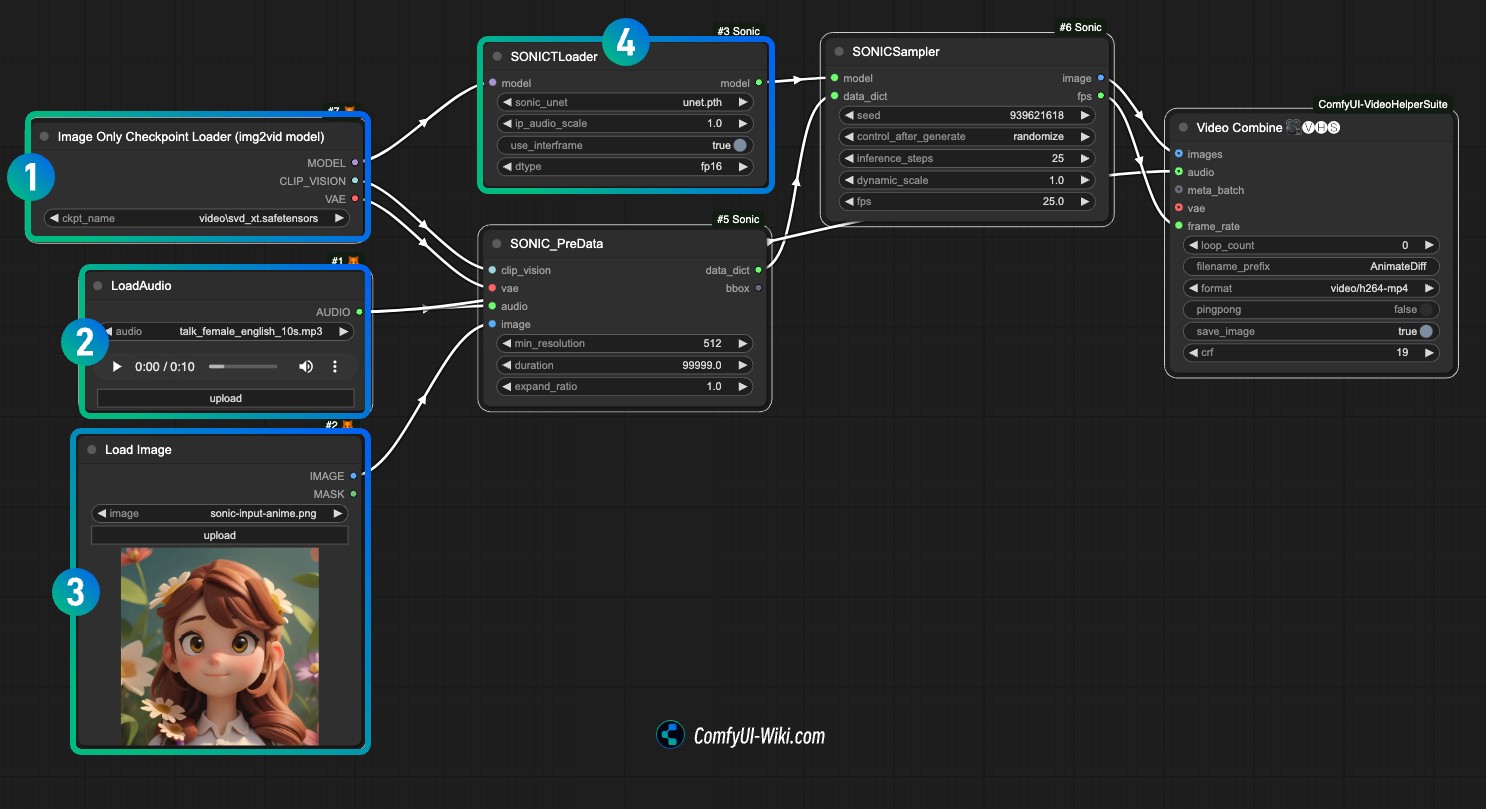
- 在序号
1处,加载 stable video diffusion 相关模型 如svd_xt_1_1.safetensors - 在序号
2处,上传音频文件,加载音频文件 - 在序号
3处,上传示例图片 - 在序号
4处,加载 unet.pth 模型文件 - 使用 Queue 或者快捷键
Ctrl(Command)+Enter运行工作流进行图片生成
问题解决
- transformers 版本问题 由于该插件要求使用 transformers==4.43.2, 如果你的工作流无法正常运行请修改
请修改 requirements.txt 文件中的
#transformers ==4.43.2去掉*#*号
transformers ==4.43.2然后重启 ComfyUI 或者使用 pip 安装对应的依赖
- frame_rate 类型不匹配问题
在最后一个节点我遇到了数字类型不匹配的问题,我试着使用 primitive 节点作为输入
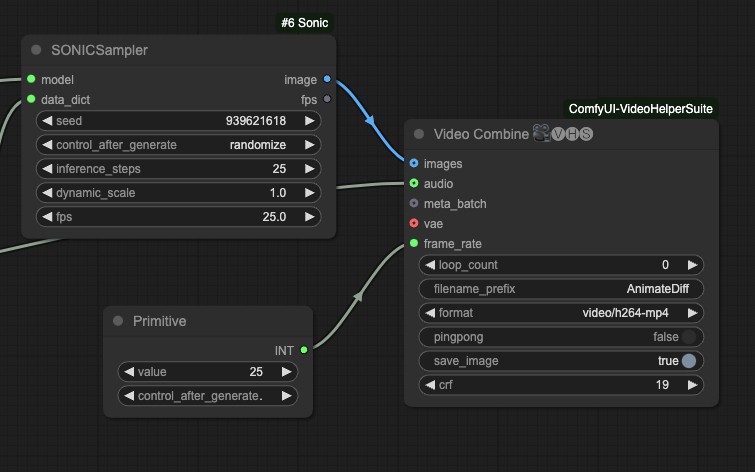
其它,由于目前还在测试这个工作流,如果你有更好的解决方案,欢迎在评论区留言,我会及时更新到这个教程中。
Stable Diffusion 3.5 在 ComfyUI 中的工作流教程
Stable Diffusion 3.5 是最新的 AI 图像生成模型,提供了多种强大的模型变体。通过 ComfyUI,用户可以轻松地在本地进行推理,并体验这些模型的强大功能。
本教程为你整理的以下资源内容,主要是关于如何在 ComfyUI 中使用 Stable Diffusion 3.5
- Stable Diffusion 3.5 FP16 版本 ComfyUI 相关工作流
- Stable Diffusion 3.5 FP8 版本 ComfyUI 相关工作流(低显存解决方案)
- Stable Diffusion 3.5 在线运行资源与 API
Stable Diffusion 3.5模型介绍
Stable Diffusion 3.5 是由 Stability AI 发布的最新一代 AI 图像生成模型。它在图像质量和提示词遵循方面实现了重大突破,标志着 AI 绘图技术迈入了一个新的纪元。该系列提供了多个模型变体,以满足不同用户的需求:

目前Stable Diffusion 3.5 官方主要提供以下版本
| 模型名称 | 参数量 | 特点 |
|---|---|---|
| Stable Diffusion 3.5 Large | 80 亿 | 最强大的基础模型,适合专业用途,支持 1 百万像素分辨率。 |
| Stable Diffusion 3.5 Large Turbo | 精简版 | 通过 4 步即可生成高质量图像,速度更快。 |
| Stable Diffusion 3.5 Medium | 25 亿 | 适用于消费级硬件,支持 0.25 到 2 百万像素分辨率,易于定制。 |
Stable Diffusion 3.5 社区许可
社区许可允许研究、非商业和年收入总额不超过 100 万美元的组织或个人免费使用。更多详细信息请参阅社区许可协议。
Stable Diffusion 3.5 原始 FP16版本 ComfyUI 相关工作流
本部分将会介绍官方认识版本的相关模型安装以及工作流文件的下载,工作流文件以及事例均来自ComfyUI 博客
下载 Stable Diffusion 3.5 模型文件
- 下载 Stable Diffusion 3.5 模型文件
| 资源名称 | 下载链接 | 安装文件夹 |
|---|---|---|
| Stable Diffusion 3.5 Large | 下载链接 | models/checkpoint |
| Stable Diffusion 3.5 Large Turbo | 下载链接 | models/checkpoint |
请参考对应的这个说明以及安装文件路径,完成对应的模型的下载和安装,按你的需要选择一个就可以
- 对应的 clip 模型文件
| 资源名称 | 下载链接 | 安装文件夹 |
|---|---|---|
| clip_g.safetensors | 下载链接 | models/clip |
| clip_l.safetensors | 下载链接 | models/clip |
| t5xxl_fp16.safetensors | 下载链接 | models/clip |
clip 模型文件如果你有使用过 3.0 或者其他相关的模型,对应的这些文件你可能已经有了,如果你是第1次使用呢,那么请下载安装
下载 Stable Diffusion 3.5 工作流workflow文件
下面是Comfy官方提供的相关事例,你可以下载对应的这个工作流文件
相对应的这个文件拖入 ComfyUI 界面,并运行生成
Stable Diffusion 3.5 FP8低显存解决方案
如果生成过程中出现内存不足的问题,可以尝试以下低显存选项:
下载 Stable Diffusion 3.5 FP8 模型文件
- 下载 Stable Diffusion 3.5 FP8 模型文件
| 资源名称 | 下载链接 | 安装文件夹 |
|---|---|---|
| Stable Diffusion 3.5 Large FP8 | 下载链接 | models/checkpoint |
请参考对应的这个说明以及安装文件路径,完成对应的模型的下载和安装
- 对应的 clip 模型文件
| 资源名称 | 下载链接 | 安装文件夹 |
|---|---|---|
| clip_g.safetensors | 下载链接 | models/clip |
| clip_l.safetensors | 下载链接 | models/clip |
| t5xxl_fp8_e4m3fn.safetensors | 下载链接 | models/clip |
| (experimental)t5xxl_fp8_e4m3fn_scaled.safetensors | 下载链接 | models/clip |
如果您的内存超过32GB,仍然建议使用t5xxl_fp16模型。
下载 Stable Diffusion 3.5 FP8 工作流workflow文件
下面是Comfy官方提供的相例子,你可以下载对应的这个工作流文件
相对应的这个文件拖入 ComfyUI 界面,并运行生成
在线运行 Stable Diffusion 3.5
您还可以通过 Hugging Face 的 Space 在线运行 Stable Diffusion 3.5:
除了可以从 Hugging Face 下载模型权重进行自托管外,用户还可以通过以下平台访问 Stable Diffusion 3.5:
其他资源
- Stable Diffusion 3.5 LoRA 模型 https://huggingface.co/Shakker-Labs/SD3.5-LoRA-Linear-Red-Light https://huggingface.co/Shakker-Labs/SD3.5-LoRA-Futuristic-Bzonze-Colored https://huggingface.co/Shakker-Labs/SD3.5-LoRA-Chinese-Line-Art
2.controlnet 模型
- 待更新
LTX Video 工作流程详细教程

LTX Video 模型介绍
LTX Video 是一个仅有 2B 参数的 DiT 架构视频生成模型,具有以下特点:
- 实时生成:能以超过实时播放速度生成视频
- 高质量输出:768x512 分辨率,24FPS 的流畅视频
- 多种生成模式:支持文本到视频、图像到视频、视频到视频转换
环境准备
系统要求
- Python 3.10.5 或更高版本
- CUDA 12.2 或更高版本
- PyTorch >= 2.1.2
ComfyUI 环境
-
更新 ComfyUI 首先确保你的 ComfyUI 已更新到最新版本,如果你不知道如何更新和升级 ComfyUI 请参考如何更新和升级 ComfyUI
-
安装 ComfyUI-LTXVideo 插件 有两种安装方式:
方式一:通过 ComfyUI Manager (推荐)
- 打开 ComfyUI Manager
- 搜索 “LTXVideo”
- 点击安装
方式二:手动安装
- 进入 ComfyUI 的
custom_nodes目录 - 克隆仓库:
- 安装依赖:
如果你不太熟悉插件安装相关操作,可以参考ComfyUI 插件安装教程
LTX Video 模型及相关模型下载
你需要下载以下模型文件:
| 模型名称 | 文件名 | 安装位置 | 下载链接 |
|---|---|---|---|
| LTX Video 模型 | ltx-video-2b-v0.9.safetensors | models/checkpoints | Hugging Face |
| PixArt 文本编码器 | model-00001-of-00002.safetensors | models/text_encoders/PixArt-XL-2-1024-MS/text_encoder | Hugging Face |
| T5 文本编码器 | t5xxl_fp16.safetensors | models/text_encoders | Hugging Face |
注意:
- PixArt 文本编码器需要下载完整的 text_encoder 文件夹内容
- T5 文本编码器文件较大(约9.79GB),建议使用下载工具下载
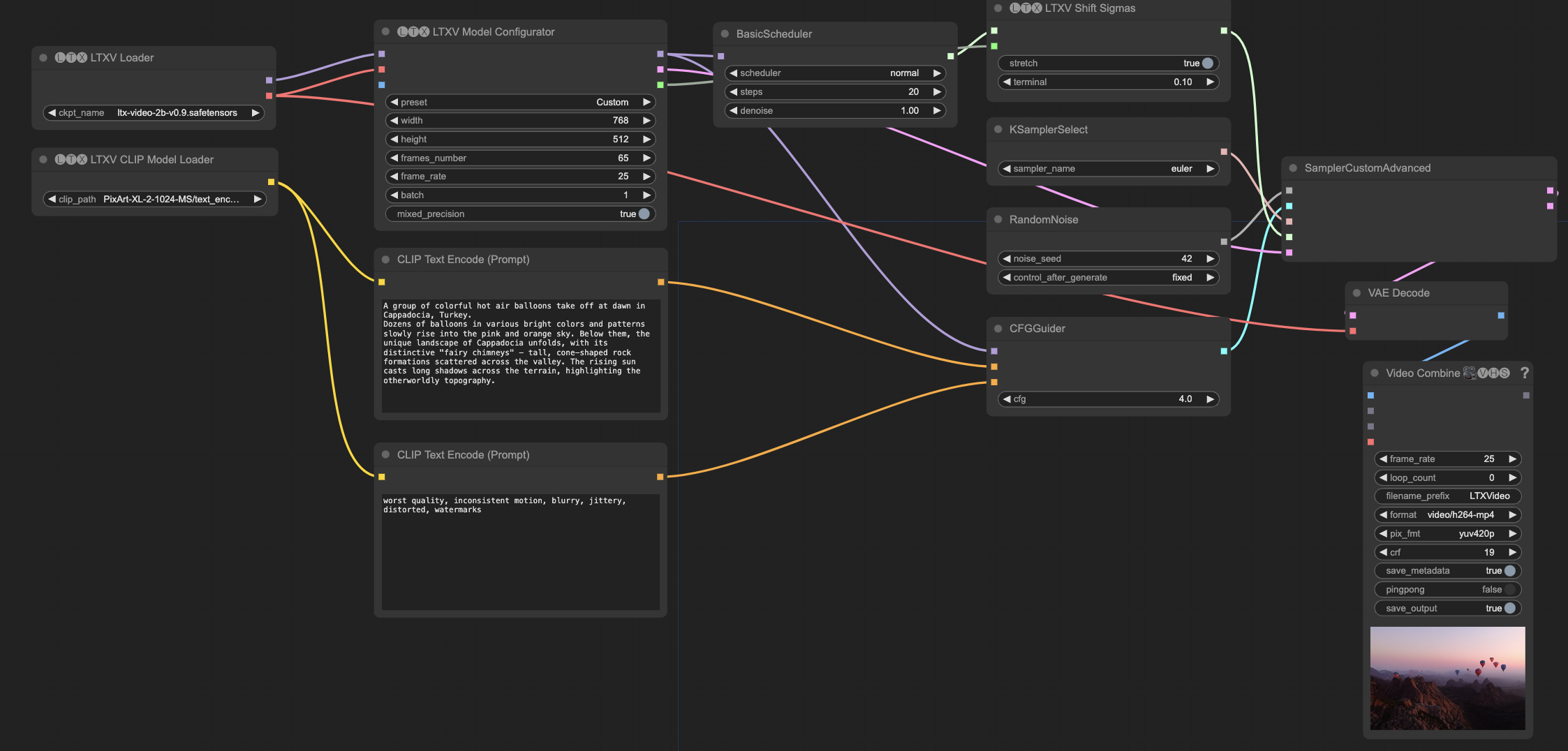
LTX Video 工作流文件
文本到视频工作流
图像到视频工作流
视频到视频工作流
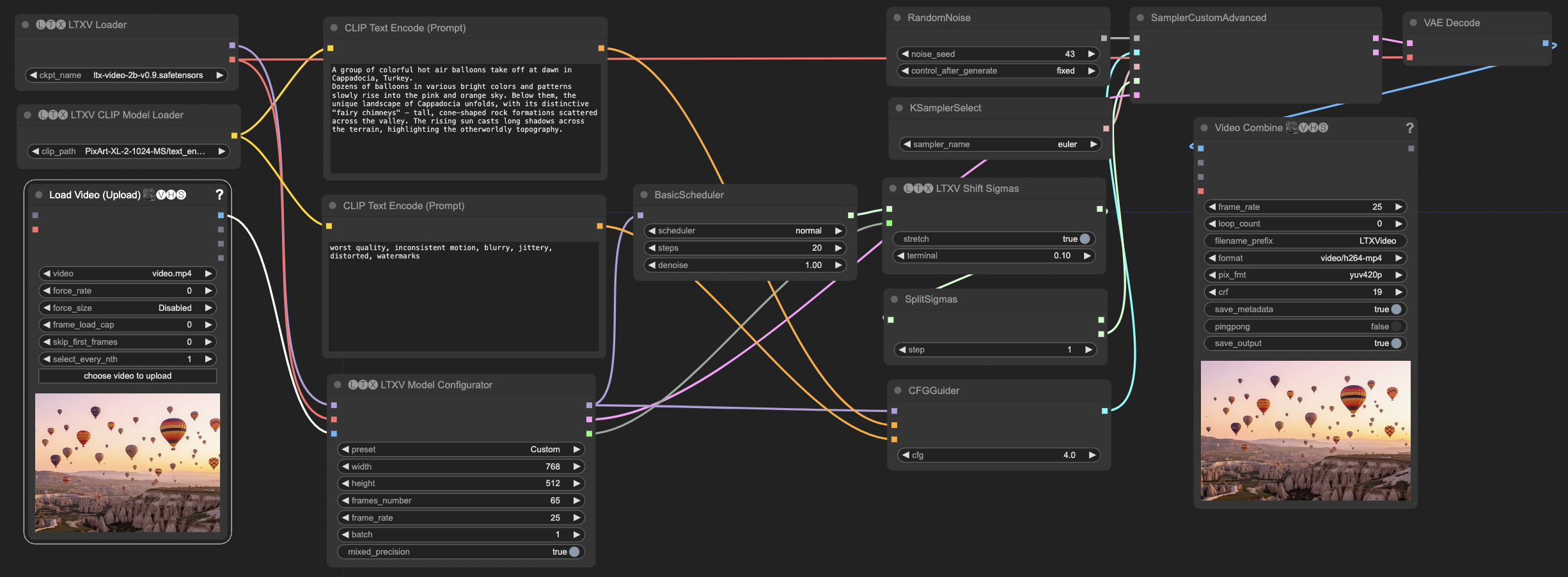
LTX Video 使用限制说明
分辨率和帧数
- 分辨率必须是32的倍数
- 帧数必须是8的倍数+1(如65帧、257帧等)
- 建议分辨率不超过720x1280
- 建议帧数不超过257帧
提示词规范
- 必须使用英文
- 提示词越详细越好
- 建议包含场景、动作、细节等完整描述
工作流使用教程
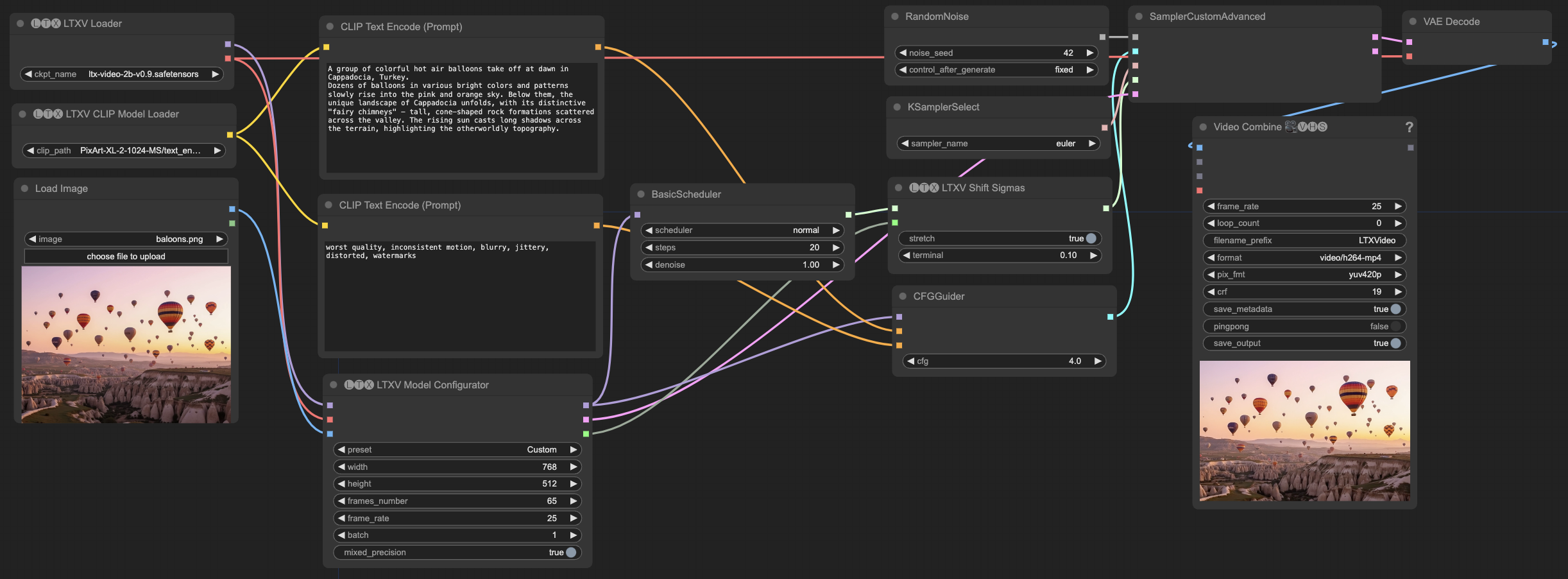
基础节点说明
所有工作流都包含以下基础节点:
- 模型加载节点
LTXVLoader: 加载 LTX Video 主模型- 选择
ltx-video-2b-v0.9.safetensors文件
- 选择
LTXVCLIPModelLoader: 加载文本编码器- 选择
PixArt-XL-2-1024-MS/text_encoder/model-00001-of-00002.safetensors文件
- 选择
LTXVModelConfigurator: 配置模型参数- 设置分辨率、帧数、FPS等基本参数
- 可选择是否启用 conditioning 输入
- 提示词处理节点
CLIPTextEncode (Positive): 正向提示词编码- 使用 PixArt 编码器处理正向提示词
CLIPTextEncode (Negative): 负向提示词编码- 使用 PixArt 编码器处理负向提示词
CFGGuider: 控制提示词引导强度- 建议值范围: 2-7
- 数值越大,生成内容越接近提示词描述
- 采样控制节点
KSamplerSelect: 选择采样器- 推荐使用 euler 采样器
BasicScheduler: 设置采样步数和调度器- 步数范围: 10-25
- 调度器类型: normal
RandomNoise: 生成随机噪声- 可设置固定种子以获得可重复的结果
SamplerCustomAdvanced: 执行采样过程- 整合所有采样相关参数进行最终生成
- 输出节点
VAEDecode: 解码生成的帧- 使用 LTX Video 内置的 VAE 解码器
VHS_VideoCombine: 合成最终视频- 可设置输出视频的帧率、格式、编码参数
- 支持预览生成的视频
LTX Video 生成模式教程
文本到视频 (Text-to-Video)
- 设置基本参数
在
LTXVModelConfigurator中:
- 分辨率: 768x512
- 帧数: 65 (约2.5秒)
- FPS: 25
- 编写提示词
- 正向提示词要尽可能详细,描述场景、动作和细节
- 负向提示词建议包含: “worst quality, inconsistent motion, blurry, jittery, distorted, watermarks”
- 调整采样参数
- Steps: 建议 20 步
- CFG: 建议 4-7
- Sampler: euler
- Scheduler: normal
图像到视频 (Image-to-Video)
除了基本设置外,还需要:
- 准备参考图像
- 使用
LoadImage节点加载参考图像 - 图像最好符合目标分辨率比例
- 调整转换参数
- 降低 CFG 值(建议 3-5)以保持与参考图像的一致性
- 可以适当减少采样步数(15-20)
视频到视频 (Video-to-Video)
- 加载源视频
使用
VHS_LoadVideo节点:
- 设置适当的帧率
- 选择是否需要调整分辨率
- 参数调优
- 使用较低的 CFG (2-4)
- 减少采样步数(10-15)
- 适当调整
sigma_shift参数
LTX Video 优化指南
参数优化
-
提示词优化
- 使用详细、具体的描述
- 包含动作、场景转换的描述
- 添加镜头语言相关的词汇
-
性能优化
- 适当降低分辨率提升速度
- 减少帧数进行测试
- 使用较少的采样步数
-
质量优化
- 画面抖动:降低 CFG 值
- 细节不足:增加采样步数
- 转场不自然:优化提示词描述
LTX Video 高级应用技巧
长视频制作
- 使用多个片段分别生成
- 通过提示词保持风格一致性
- 使用视频编辑工具进行后期衔接
风格控制
- 在提示词中加入具体的艺术风格描述
- 使用参考图像引导风格
- 通过 CFG 值调整风格强度
动作控制
- 在提示词中详细描述动作过程
- 使用关键帧作为参考
- 适当调整帧率以获得理想效果
LTX Video 示例与模板
场景示例
- 简单场景过渡
正向提示词: “A serene lake at sunrise, gentle ripples on the water surface, morning mist slowly rising, birds flying across the golden sky” 采样步数: 20 CFG: 4
- 复杂动作序列 正向提示词: “A professional dancer performing a graceful contemporary dance sequence, flowing movements, dynamic spins and leaps, soft lighting, studio setting” 采样步数: 25 CFG: 5
记得保存你满意的参数组合,以便后续使用。通过不断实验和调整,你会逐渐掌握 LTX Video 的使用技巧。
LTX Video 提示词模板
LTX Video 资源链接
LTX Video 官方资源
LTX Video 模型下载
LTX Video 在线服务
LTX Video 社区资源
支持与帮助
title: HunyuanVideo 文生视频工作流指南及示例 description: 详细介绍如何在 ComfyUI 中使用腾讯混元 HunyuanVideo 模型进行文生视频生成的完整教程,包括环境配置、模型安装和工作流使用说明 tag: video,t2v
HunyuanVideo 文生视频工作流指南及示例
本教程将详细介绍如何在 ComfyUI 中使用腾讯混元 HunyuanVideo 模型进行文生视频生成。我们会一步步指导你完成整个过程。
1. 安装并更新 ComfyUI 到最新版本
如果你还没有安装 ComfyUI,请参考对应板块内容完成安装:
ComfyUI 安装教程 ComfyUI 更新教程
因为需要使用到 ‘EmptyHunyuanLatentVideo’ 节点,所以需要先安装并更新 ComfyUI 到最新版本才有对应的节点
2. 模型下载和安装
HunyuanVideo 需要下载以下模型文件:
2.1 主模型文件
从 HunyuanVideo 主模型下载页面 下载以下文件:
| 文件名 | 大小 | 放置目录 |
|---|---|---|
| hunyuan_video_t2v_720p_bf16.safetensors | 约 25.6GB | ComfyUI/models/diffusion_models |
2.2 文本编码器文件
从 HunyuanVideo 文本编码器下载页面 下载以下文件:
| 文件名 | 大小 | 放置目录 |
|---|---|---|
| clip_l.safetensors | 约 246MB | ComfyUI/models/text_encoders |
| llava_llama3_fp8_scaled.safetensors | 约 9.09GB | ComfyUI/models/text_encoders |
2.3 VAE 模型文件
从 HunyuanVideo VAE 下载页面 下载以下文件:
| 文件名 | 大小 | 放置目录 |
|---|---|---|
| hunyuan_video_vae_bf16.safetensors | 约 493MB | ComfyUI/models/vae |
模型目录结构参考
3.工作流文件下载
工作流文件来源地址: HunyuanVideo 工作流文件下载
基础视频生成工作流
HunyuanVideo 支持以下分辨率设置:
| 分辨率 | 9:16 比例 | 16:9 比例 | 4:3 比例 | 3:4 比例 | 1:1 比例 |
|---|---|---|---|---|---|
| 540p | 544×960×129帧 | 960×544×129帧 | 624×832×129帧 | 832×624×129帧 | 720×720×129帧 |
| 720p (推荐) | 720×1280×129帧 | 1280×720×129帧 | 1104×832×129帧 | 832×1104×129帧 | 960×960×129帧 |
4. 工作流节点说明
4.1 模型加载节点
-
UNETLoader
- 用途:加载主模型文件
- 参数:
- Model:
hunyuan_video_t2v_720p_bf16.safetensors - Weight Type:
default(如果显存不足可以选择 fp8 类型)
- Model:
-
DualCLIPLoader
- 用途:加载文本编码器模型
- 参数:
- CLIP 1:
clip_l.safetensors - CLIP 2:
llava_llama3_fp8_scaled.safetensors - Text Encoder:
hunyuan_video
- CLIP 1:
-
VAELoader
- 用途:加载 VAE 模型
- 参数:
- VAE Model:
hunyuan_video_vae_bf16.safetensors
- VAE Model:
4.2 视频生成关键节点
-
EmptyHunyuanLatentVideo
- 用途:创建视频潜空间
- 参数:
- Width: 视频宽度(如 848)
- Height: 视频高度(如 480)
- Frame Count: 帧数(如 73)
- Batch Size: 批次大小(默认 1)
-
CLIPTextEncode
- 用途:文本提示词编码
- 参数:
- Text: 正向提示词(描述你想要生成的内容)
- 建议使用详细的英文描述
-
FluxGuidance
- 用途:控制生成引导强度
- 参数:
- Guidance Scale: 引导强度(默认 6.0)
- 数值越大,生成结果越接近提示词,但可能影响视频质量
-
KSamplerSelect
- 用途:选择采样器
- 参数:
- Sampler: 采样方法(默认
euler) - 其他可选:
euler_ancestral,dpm++_2m等
- Sampler: 采样方法(默认
-
BasicScheduler
- 用途:设置采样调度器
- 参数:
- Scheduler: 调度方式(默认
simple) - Steps: 采样步数(建议 20-30)
- Denoise: 去噪强度(默认 1.0)
- Scheduler: 调度方式(默认
4.3 视频解码和保存节点
-
VAEDecodeTiled
- 用途:将潜空间视频解码为实际视频
- 参数:
- Tile Size: 256(如果显存不足可以调小)
- Overlap: 64(如果显存不足可以调小)
注意:优先使用 VAEDecodeTiled 而不是 VAEDecode,因为它更节省显存
-
SaveAnimatedWEBP
- 用途:保存生成的视频
- 参数:
- Filename Prefix: 文件名前缀
- FPS: 帧率(默认 24)
- Lossless: 是否无损(默认 false)
- Quality: 质量(0-100,默认 80)
- Filter Type: 过滤类型(默认
default)
5. 参数优化建议
5.1 显存优化
如果遇到显存不足问题:
- 在 UNETLoader 中选择 fp8 权重类型
- 减小 VAEDecodeTiled 的 tile_size 和 overlap 参数
- 使用较低的视频分辨率和帧数
5.2 生成质量优化
-
提示词优化
[主体描述], [动作描述], [场景描述], [风格描述], [质量要求]示例:
anime style anime girl with massive fennec ears and one big fluffy tail, she has blonde hair long hair blue eyes wearing a pink sweater and a long blue skirt walking in a beautiful outdoor scenery with snow mountains in the background -
参数调整
- 增加采样步数(Steps)可提高质量
- 适当提高 Guidance Scale 可增强文本相关性
- 根据需要调整 FPS 和视频质量参数
6. 常见问题
-
显存不足
- 参考显存优化部分的建议
- 关闭其他占用显存的程序
- 使用较低的视频分辨率设置
-
生成速度慢
- 这是正常现象,视频生成需要较长时间
- 可以适当减少采样步数和帧数
- 使用较低分辨率可以加快速度
-
生成质量问题
- 优化提示词描述
- 增加采样步数
- 调整 Guidance Scale
- 尝试不同的采样器
参考内容链接
HunyuanVideo 图生视频GGUF、FP8及ComfyUI Native 工作流完整指南及示例
腾讯于2025年3月6日正式发布了 HunyuanVideo 图生视频模型,目前模型已开源,你可以在 HunyuanVideo-I2V 找到模型。
下面是 HunyuanVideo 的整体架构图
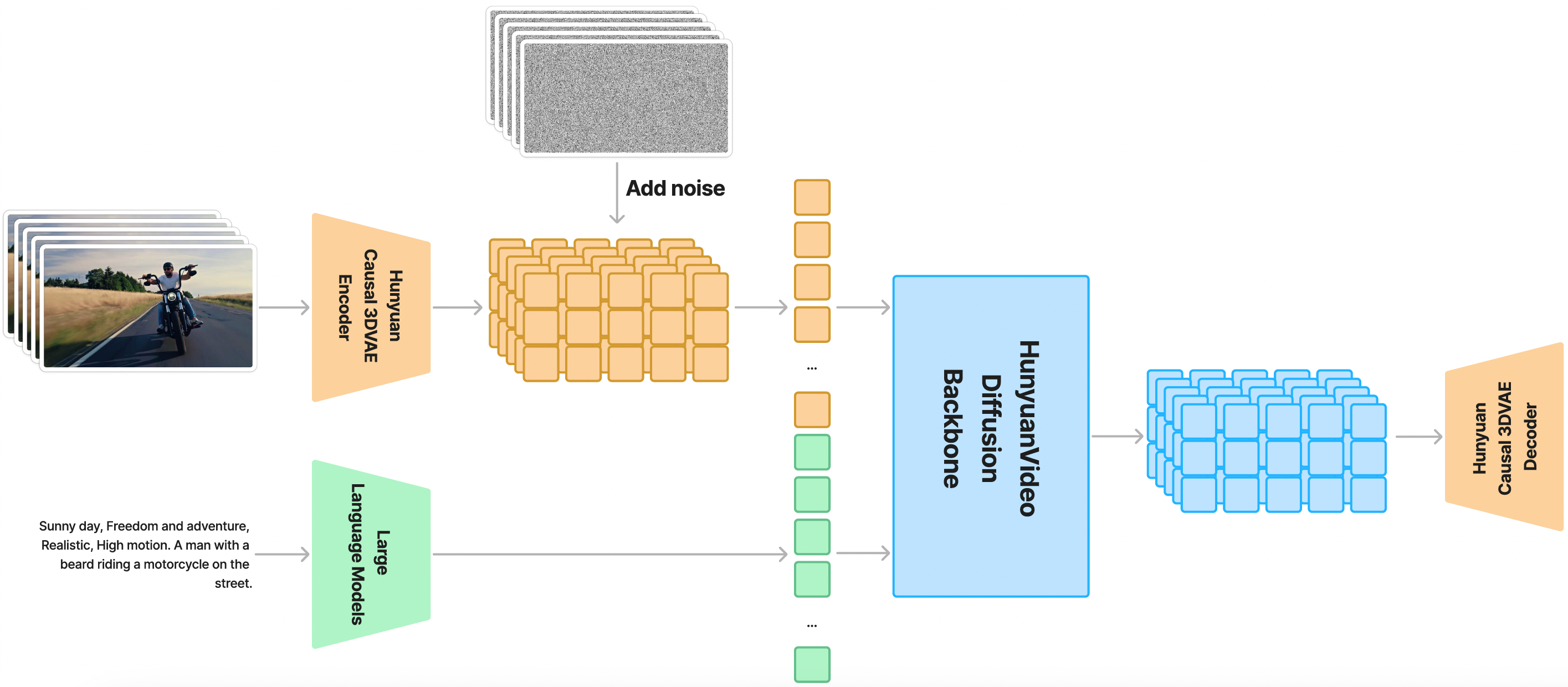
目前 ComfyUI 官方已原生支持 HunyuanVideo-I2V 模型,社区作者 kijai 和 city96 的自定义节点目前已更新支持 HunyuanVideo-I2V 模型。
目前对应模型除了腾讯官方之外,下面是目前 ComfyUI Wiki 搜索整理到的对应版本
- ComfyUI 官方重新打包版本,无需插件:Comfy-Org/HunyuanVideo_repackaged
- Kijai 版本,需安装ComfyUI-HunyuanVideoWrapper :Kijai/HunyuanVideo_comfy
- city96 打包版本,需安装ComfyUI-GGUF:city96/HunyuanVideo-I2V-gguf
在本文里,我们将会基于这些版本分别提供对应的完整模型安装和工作流示例使用说明。
本文主要讲解图生视频工作流,如果你想要了解腾讯混元文生视频工作流,可以参考腾讯混元文生视频工作流指南及示例
Comfy 官方 HunyuanVideo I2V工作流
相应工作流来自 ComfyUI 官方文档
请在开始本教程前请参考如何更新 ComfyUI部分更新你的 ComfyUI 到最新版本,防止出现 Comfy_Core 针对 HunyuanVideo 的相关节点缺失
- HunyuanImageToVideo
- TextEncodeHunyuanVideo_ImageToVideo
1. HunyuanVideo I2V 工作流文件
下载下面的工作流文件,然后拖入 ComfyUI, 或者使用菜单 Workflows -> Open(ctrl+o) 打开以加载工作流

JSON 格式工作流下载
2. HunyuanVideo I2V 相关模型下载
以下模型均来自Comfy-Org/HunyuanVideo_repackaged,请下载对应的模型:
- llava_llama3_vision.safetensors
- clip_l.safetensors
- llava_llama3_fp16.safetensors
- llava_llama3_fp8_scaled.safetensors
- hunyuan_video_vae_bf16.safetensors
- hunyuan_video_image_to_video_720p_bf16.safetensors
下载后请按照下面的文件组织,将他们保存到 ComfyUI/models 的对应文件夹下
3. 输入图片
下载下面的图片作为输入图片

按步骤完成对应 HunyuanVideo I2V 工作流节点的检查
参照图片完成对应节点内容的检查,确保工作流正常运行
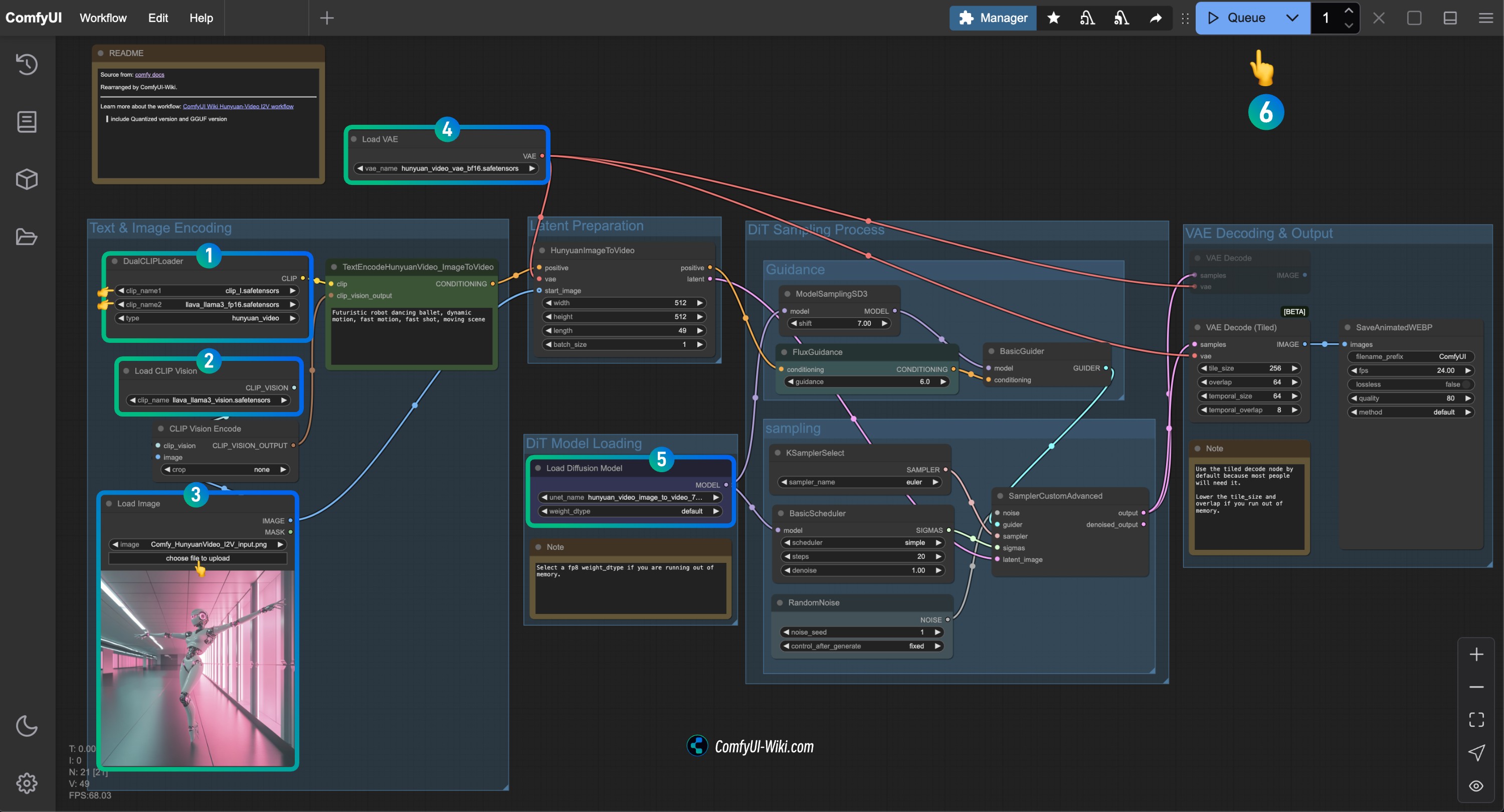
- 检查
DualCLIPLoader节点:
- 确保
clip_name1: clip_l.safetensors 正确加载 - 确保
clip_name2: llava_llama3_vision.safetensors 正确加载
- 检查
Load CLIP Vision节点: 确保 llava_llama3_vision.safetensors 正确加载 - 在
Load Image节点中,上传之前提供的输入图片 - 检查
Load VAE节点: 确保 hunyuan_video_vae_bf16.safetensors 正确加载 - 检查
Load Diffusion Model节点: 确保 hunyuan_video_image_to_video_720p_bf16.safetensors 正确加载
- 如果运行过程中遇到
running out of memory.错误,可以试着把weight_dtype设置为fp8类型的
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Kijai HunyuanVideoWrapper 版本
1. 自定义节点安装
你需要安装以下自定义节点:
如果你不知道如何安装自定义节点,请参考ComfyUI 自定义节点安装指南
2. 模型下载
下载后请按照下面的文件组织,将他们保存到 ComfyUI/models 的对应文件夹下
3. HunyuanVideo I2V 工作流文件
按步骤完成对应 HunyuanVideo I2V 工作流节点的检查
参照图片完成对应节点内容的检查,确保工作流正常运行
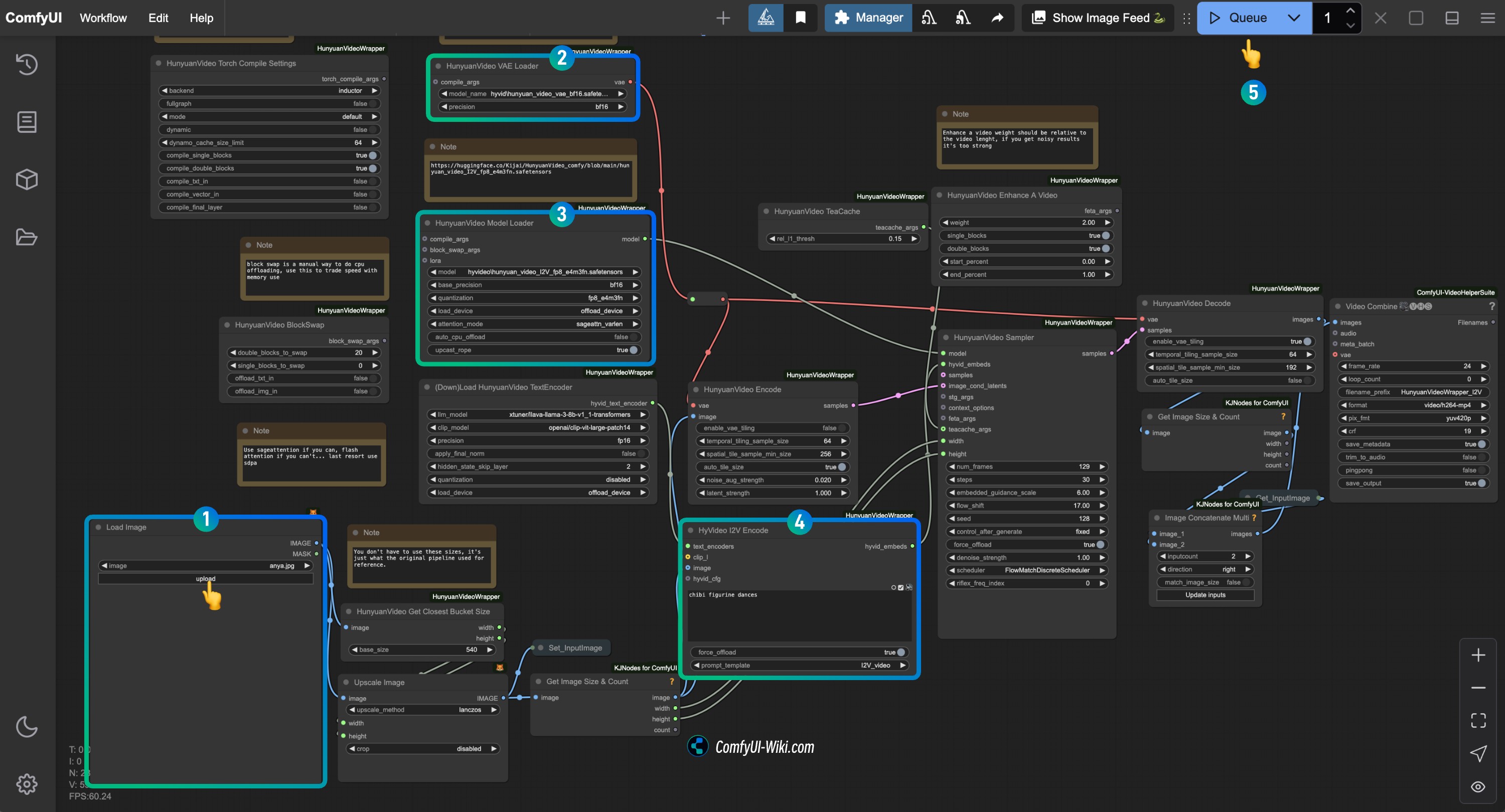
- 在
Load Image节点中,上传你要用于图生视频的图片 - 在
HunyuanVideo VAE Loader节点中,确保hunyuan_video_vae_bf16.safetensors正确加载 - 在
HunyuanVideo Model Loader节点中,确保hunyuan_video_I2V_fp8_e4m3fn.safetensors正确加载 - 修改
HyVideo I2V Encode节点中的 prompt 文本,输入你想要生成的视频描述 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
city96 GGUF 版本
1. 自定义节点安装
你需要安装以下自定义节点:
如果你不知道如何安装自定义节点,请参考ComfyUI 自定义节点安装指南
2. 模型下载
这部分的模型除了 HunyuanVideo 模型之外,基本和 Comfy 官方版本一致, 对应模型请参考本文 Comfy 官方版本部分进行手动下载
你需要访问 city96/HunyuanVideo-I2V-gguf 下载你需要版本的模型,并保存对应的 gguf 模型文件到 ComfyUI/models/unet 文件夹下
3. HunyuanVideo I2V 工作流文件
按步骤完成对应 HunyuanVideo I2V 工作流节点的检查
参照图片完成对应节点内容的检查,确保工作流正常运行
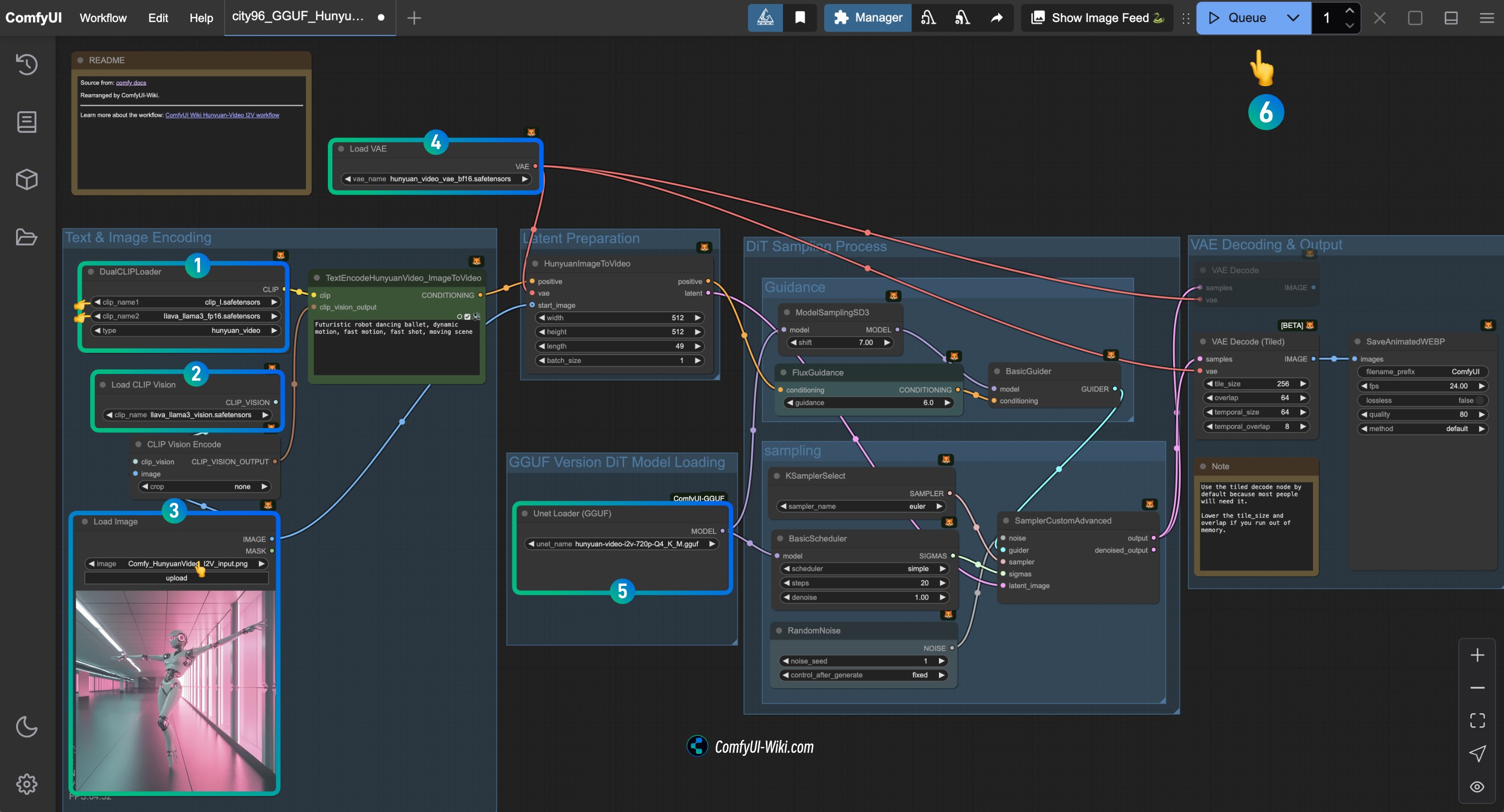
- 检查
DualCLIPLoader节点:
- 确保
clip_name1: clip_l.safetensors 正确加载 - 确保
clip_name2: llava_llama3_vision.safetensors 正确加载
- 检查
Load CLIP Vision节点: 确保 llava_llama3_vision.safetensors 正确加载 - 在
Load Image节点中,上传之前提供的输入图片 - 检查
Load VAE节点: 确保 hunyuan_video_vae_bf16.safetensors 正确加载 - 检查
Load Diffusion Model** 节点: 确保对应的 HunyuanVideo GGUF 模型 正确加载** - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
IC-Light V2 工作流教程
由于 IC-Light V2 目前尚未开源完整模型,但官方提供了 Hugging Face Space 在线体验环境,让我们可以直接体验这个强大的图像编辑工具。
在线运行使用 IC-Light V2
你可以直接在下方的交互界面中使用 IC-Light V2。如果感觉屏幕尺寸较小,可以点击右上角的全屏按钮进入全屏模式,或点击新窗口按钮在新标签页中打开。
IC-Light V2使用说明
IC-Light V2 运行基本操作步骤
-
上传图片
- 点击界面中的上传按钮
- 支持常见的图片格式(JPG、PNG等)
- 建议使用清晰的原始图片以获得最佳效果
-
选择处理模式
- 目前仅开放了前景条件模型
- 可以处理多种风格的图像,包括油画和动漫风格
-
调整参数
- 根据界面提供的选项调整处理参数
- 观察实时预览效果
- 可以随时调整直到达到理想效果
-
下载结果
- 处理完成后可以直接下载生成的图片
- 建议保存原图以便对比或重新处理
IC-Light V2 ComfyUI 相关资源
由于官方目前暂未开源模型,目前只能通过 Space 来体验。官方正在开发更多功能模型,等待官方开源后,我们会第一时间更新相关内容。以下是一些相关资源:
- ComfyUI-IC-Light 插件 - 提供了 IC-Light 相关的节点和使用示例
- IC-Light V2 模型仓库
- IC-Light V2 ComfyUI Workflow
IC-Light V2使用许可
IC-Light V2 仅供非商业用途使用。在使用该模型时,请确保遵守相关许可条款和使用规范。
许可限制说明
- 仅限个人和研究用途使用
- 禁止用于商业项目或商业产品
- 禁止将模型或其生成的内容用于商业目的
- 禁止在未经授权的情况下修改或分发模型
请在使用 IC-Light V2 之前仔细阅读并遵守这些许可条款,以避免任何潜在的法律问题。
IC-Light V2 相关资源
- IC-Light V2 发布新闻
- GitHub 项目地址
- 技术讨论
DeepSeek Janus Pro ComfyUI 工作流
Janus Pro 是 DeepSeek 于 2025年1月27日开源的多模态模型,同时具有图像理解和生成的能力
本教程基于 https://github.com/CY-CHENYUE/ComfyUI-Janus-Pro 插件,详细介绍如何在 ComfyUI 中搭建使用 DeepSeek Janus Pro
Janus Pro ComfyUI Setp by Step 教程
1. 安装 ComfyUI-Janus-Pro 插件
插件地址为: https://github.com/CY-CHENYUE/ComfyUI-Janus-Pro 安装方法:
- 在 ComfyUI Manager “Janus-Pro” 安装(推荐)
- ComfyUI-Janus-Pro 的仓库中也有详尽的插件安装说明,主要是当你使用手动安装时需要安装相关依赖
- 其它安装方法请参考ComfyUI 插件安装教程
请确保你的网络可以正常访问 github
2. 下载 DeepSeek Janus Pro 相关模型
在这个步骤中我们需要下载 DeepSeek Janus Pro 1B 或者 7B 模型下载
DeepSeek Janus Pro 模型下载和安装
| 模型名称 | 模型地址 | 安装位置 |
|---|---|---|
| Janus-Pro-1B | 🤗 Hugging Face | ComfyUI/models/Janus-Pro/Janus-Pro-1B/ |
| Janus-Pro-7B | 🤗 Hugging Face | ComfyUI/models/Janus-Pro/Janus-Pro-7B/ |
你需要下载所有的 json格式文件以及 .bin格式的模型文件,最后安装完成后对应的文件夹结构如下
3. Janus Pro 工作流文件下载
这个工作流节点包含了图像描述和图像生成
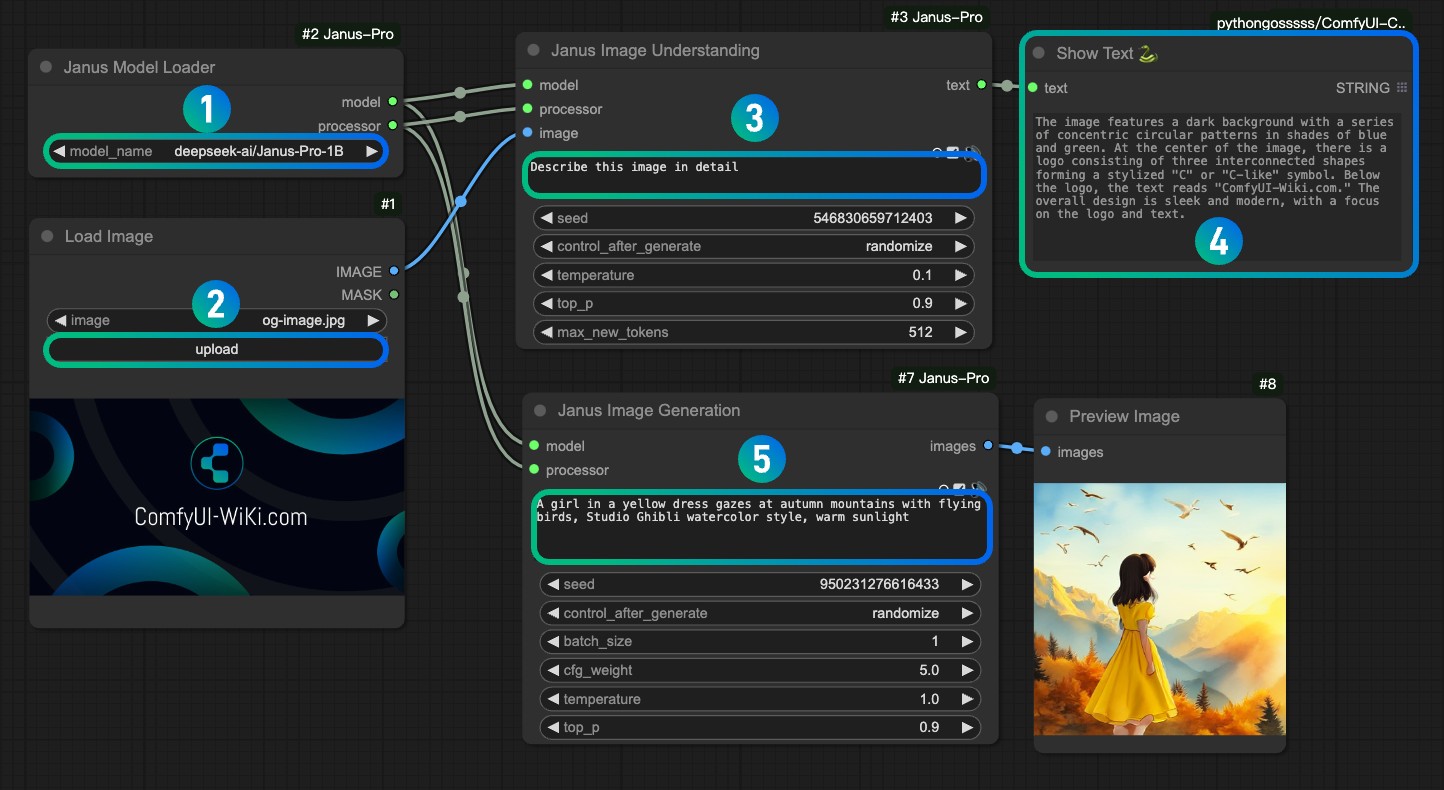
- 在序号
1选择 1B 或者 7B 模型 - 在序号
2上传你需要用于 Janus Pro 解读的图片 - 在序号
3可以调整用于图片描述的 Prompt, 我测试过中文、英文、日语输入都没有问题,但是如果你需要特定语言的输出,请你在 prompt 中声明,类似 请使用日语输出 这样的要求 - 序号
4是一个展示 文本的节点,我这里使用的是ComfyUI-Custom-Scripts 插件中的Show Text节点 - 请在序号
5出输入用于图像生成的 prompt
Janus Pro 相关链接
Janus Pro Huggingface 模型下载
| Model | Sequence Length | Download |
|---|---|---|
| Janus-1.3B | 4096 | 🤗 Hugging Face |
| JanusFlow-1.3B | 4096 | 🤗 Hugging Face |
| Janus-Pro-1B | 4096 | 🤗 Hugging Face |
| Janus-Pro-7B | 4096 | 🤗 Hugging Face |
Janus Pro Github地址:
https://github.com/deepseek-ai/Janus
在 Huggingface Space 体验 DeepSeek Janus Pro
Chat With Janus 1.3B: https://huggingface.co/spaces/deepseek-ai/Janus-1.3B Chat With Janus Pro 7B: https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B Chat With Janus: https://huggingface.co/spaces/deepseek-ai/JanusFlow-1.3B
DeepSeek Janus-Pro ComfyUI 节点
ComfyUI-Janus-Pro节点: https://github.com/CY-CHENYUE/ComfyUI-Janus-Pro
Lumina Image 2.0 ComfyUI 工作流示例
 Lumina-Image-2.0 是由 Alpha-VLLM 团队在 2025 年春节期间开源的一款文生图模型,参数量为 2.6B,基于 DiT 架构
这一模型在图像质量、排版、提示词理解等诸多方面都有不错的表现。
Lumina-Image-2.0 是由 Alpha-VLLM 团队在 2025 年春节期间开源的一款文生图模型,参数量为 2.6B,基于 DiT 架构
这一模型在图像质量、排版、提示词理解等诸多方面都有不错的表现。
Lumina-Image-2.0 Github:https://github.com/Alpha-VLLM/Lumina-Image-2.0 Lumina-Image-2.0 huggingface:https://huggingface.co/Alpha-VLLM/Lumina-Image-2.0 在线体验地址1(中文):https://magic-animation.intern-ai.org.cn/image/create 在线体验地址(Gradio):http://47.100.29.251:10010/
本文将基于 ComfyUI Example 的相关示例进行讲解
Lumina Image 2.0 工作流示例
1. 下载并安装 Lumina Image 2.0 模型
| 名称 | 体积 | 安装位置 | 下载链接 |
|---|---|---|---|
| Lumina Image 2.0 | 10.6GB | ComfyUI/models/checkpoints | 前往下载 |
2. Lumina Image 2.0 ComfyUI 工作流
请点击下面的按钮下载对应的 ComfyUI 工作流,并使用 ComfyUI 打开
Lumina Image 2.0 工作流说明
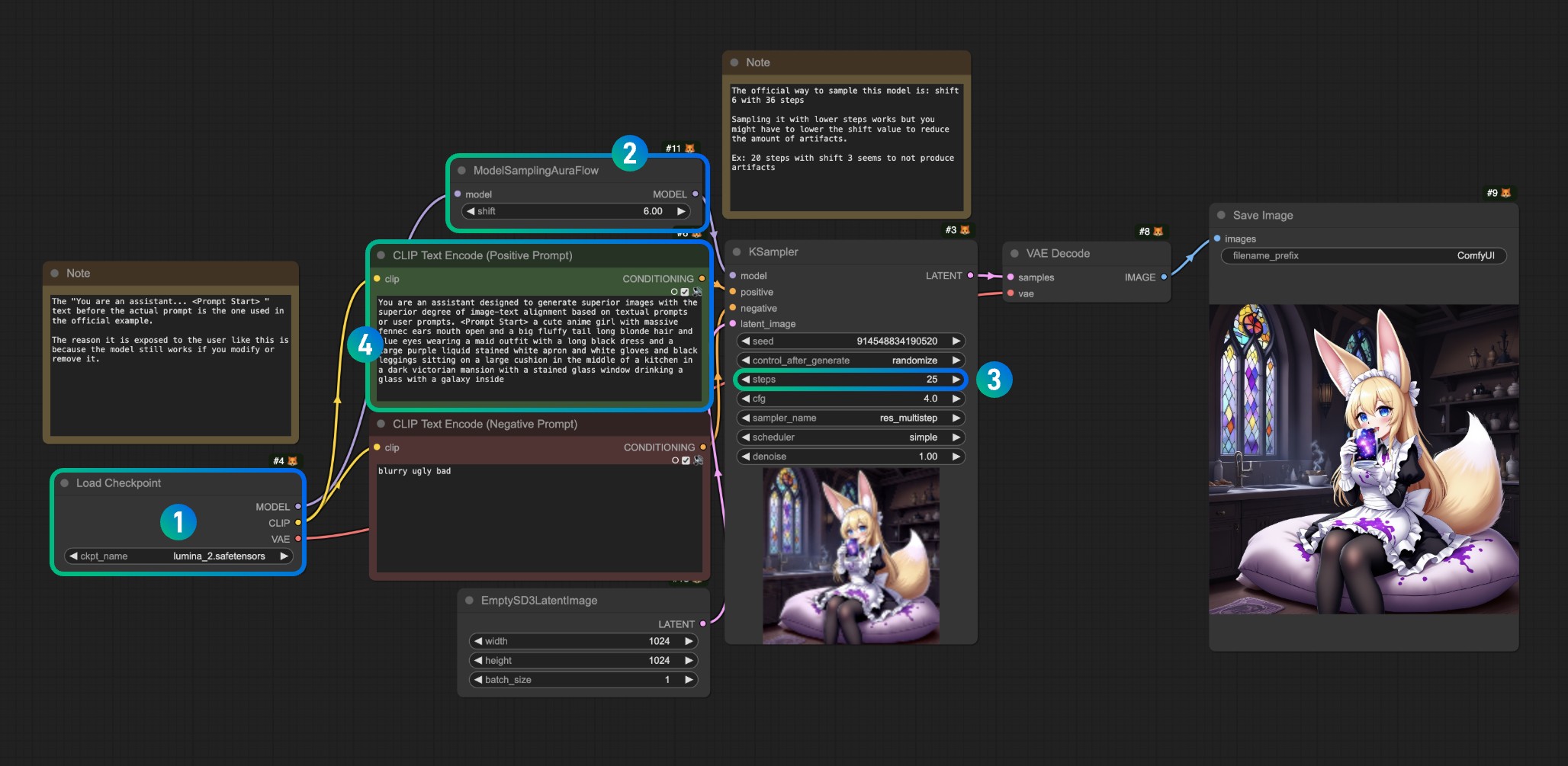
参考图片,请在对应序号出完成对应操作
- 请确保
lumina_2.safetensors模型在Load Checkpoint 处有正常载入,如没有对应模型,请检查对应模型位置,或者刷新/重启 ComfyUI
载入对应的模型后使用 Queue 或者快捷键 Ctrl(Command)+Enter 运行工作流进行图片生成
如果你修改采样步数序号3 对应序号 2 处的偏移量可以采取等比例修改
如:
- step 36 对应 shift 6
- step 20 对应 shift 3
Hunyuan3D 2.0 完整使用指南,包括 ComfyUI 原生支持、ComfyUI-Hunyuan3DWrapper

Hunyuan3D-2 是腾讯推出的开源 3D 生成大模型系列,目前(2025 年 3 月)最新版本为 2.0, 支持通过文本、图像或草图生成带有高分辨率纹理贴图的高保真 3D 模型。
技术亮点
系统采用 几何生成 + 纹理合成 的分离式流程:
- 几何生成(Hunyuan3D-DiT):基于流扩散模型生成无纹理的 3D 几何模型,参数量达 2.6B,可精准提取输入图像或文本的几何信息。
- 纹理合成(Hunyuan3D-Paint):为几何模型添加高分辨率(4K)纹理,参数量 1.3B,支持多视图扩散生成技术,确保纹理逼真且光照一致。
通过解耦形状与纹理生成,有效降低了复杂度并提升生成质量。
性能与效率优化
- 快速生成:最快 30 秒完成模型生成,加速版本(Hunyuan3D-DiT-v2-0-Fast)通过指导蒸馏技术将推理时间缩短 50%。
- 多模态输入:支持文本描述、图片、草图等多种输入方式,兼容 Blender 插件和 Gradio 应用,降低使用门槛。
开源模型生态 项目开源了 6 个模型(部分为简化版),覆盖不同场景需求:
- Hunyuan3D-2mv:多视角形状生成模型,适用于复杂场景建模。
- Hunyuan3D-Delight-v2-0:图像去光影模型,生成光照不变的纹理。 其他模型包括轻量级版本(2mini)、高保真几何生成(DiT-v2-0)等。
下面一些在线体验或者不依赖 ComfyUI 的实现来体验 Hunyuan3D 2.0 的方式:
下面我们将开始介绍在 ComfyUI 中实现 Hunyuan3D 2.0 模型生成的方案。
实现 Hunyuan3D 2.0 模型生成的 ComfyUI 方案
下面是在本篇指南中将会主要涉及的内容,我会提供对应完整的工作流和相关步骤教程。
ComfyUI-Hunyuan3DWrapper
由 Kijai 开发,目前在ComfyUI 中表现和支持的效果比较完整,能实现从模型到材质的整体渲染输出,但是材质生成部分需要单独编译一个相关的组件,需要稍微懂一些 Python 虚拟环境及 pip 相关的简单知识

ComfyUI 官方原生支持

目前 ComfyUI 已经官方支持了 Hunyuan3D 2.0 及 2mv 系列的模型,可以渲染出模型,但是目前还没有支持材质渲染,最后输出的是体素模型,不过也挺有美感的,只需要更新到 ComfyUI 最新版本即可使用, 使用和体验都比较简单
ComfyUI 3D Pack
这个插件主要还是它的依赖环境和最新的 ComfyUI 依赖环境不同,导致安装非常困难,我尝试了很多次也没有成功安装,所以这里在本文里我只能给出本文的相关部分给出介绍以及相关的资源。
输入图片
由于在本示例中涉及了多个工作流,所以在这里我们提供了对应的输入输入图片,这些素材都来自于 comfyUI 官方文档 中使用的示例图片,你也可以使用自己的图片来生成。
由于 ComfyUI-Hunyuan3DWrapper 插件使用了 ComfyUI-essentials 插件节点来完成了背景的自动移除,而 ComfyUI 原生支持的工作流并没有提供相应的功能,目前这里提供的图片都是处理后的,如果你需要使用自己的图片,可以参考 ComfyUI-Hunyuan3DWrapper 插件的背景移除部分来实现背景的自动移除。
ComfyUI-Hunyuan3DWrapper Hunyuan3D 2.0 工作流
这部分,我们将使用 ComfyUI-Hunyuan3DWrapper 插件来实现 Hunyuan3D 2.0 模型生成,我重新整理了对应的工作流,并添加了模型下载链接到工作流文件中。
1. 相关插件安装
Kijai 的工作流依赖于下面两个插件:
你可以通过 ComfyUI Manager 来安装上面的插件
1.1 插件基础依赖安装
这部分熟悉 ComfyUI 插件安装的读者应该比较熟悉,如果你是通过 ComfyUI Manager 安装的插件,那么插件应该会自动完成安装。
如果你是通过手动或者 git 安装,你需要在对应的 ComfyUI 的虚拟环境中执行依赖安装的命令,
对应插件依赖安装请参考 ComfyUI插件的安装指南 最后的依赖安装部分来完成。
1.2 纹理生成相关组件安装
在安装完成 ComfyUI-Hunyuan3DWrapper 基础依赖后,纹理生成部分依赖的组件需要编译安装。作者已经提供了针对特定环境的预编译wheel文件。
对应的文件,作者在对应的目录下已经提供了,并且在插件的 Readme 中也有说明如何使用,考虑到 ComfyUI Wiki 的读者是多语言用户,所以在这里对这部分的内容进行了一定的翻译整理
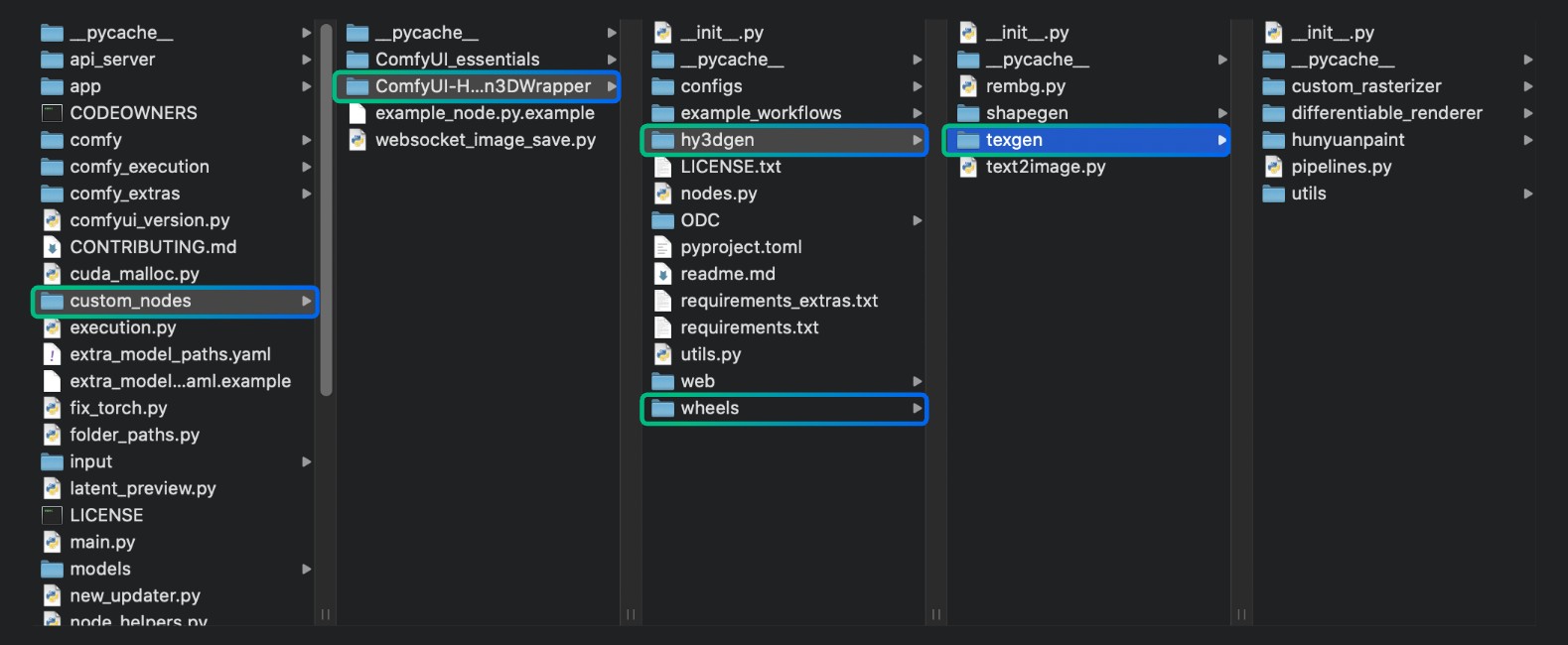
1.2.1 预编译wheel文件安装
以下是针对不同环境的预编译wheel文件安装,如果没有符合你环境的版本,请参考自行编译安装部分
对于ComfyUI 桌面版 你可以参考哦下面的路径来完成在对应环境中的安装
对于桌面版 ComfyUI 你需要启动桌面版后按照下图打开对应的 terminal,对应的 python 环境目前是已经激活了的,所以你可以直接在这个终端中运行对应的按照
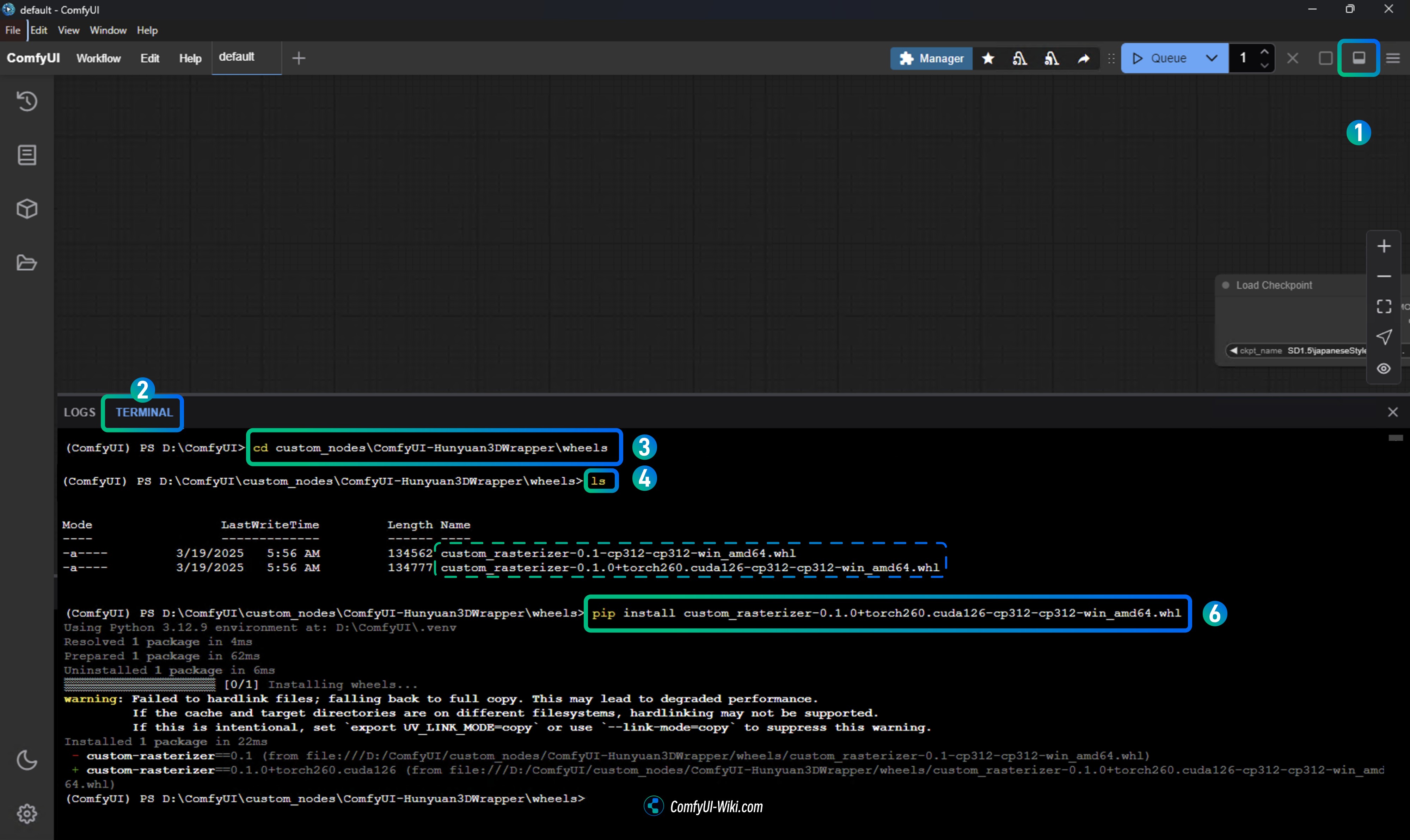
- 启动桌面版后,点击右上角的 toggle 按钮,来打开底部的日志面板
- 选择底部面板中的
terminal标签,来打开对应的终端 - 在终端中运行对应的安装命令
pip install ComfyUI\custom_nodes\ComfyUI-Hunyuan3DWrapper\wheels\custom_rasterizer-0.1-cp312-cp312-win_amd64.whl这样是可以的,但是有的用户反馈这样安装找不到文件,所以这里有了使用 cd 命令进入对应文件夹的指令
cd custom_nodes\ComfyUI-Hunyuan3DWrapper\wheels进入对应的文件夹
- 使用
ls列出 wheel 文件夹下文件 - 使用
pip install安装对应的 wheel 文件,如:
pip install custom_rasterizer-0.1-cp312-cp312-win_amd64.whl具体情况需要根据你的版本选择
1.2.2 自行编译安装(如预编译文件不适用于你的系统)
如果预编译的wheel文件不适用于你的系统,你需要自行编译:
编译并安装Rasterizer:
请参考 1.2.1 部分进入对应的桌面版终端后,使用 cd 命令进入对应文件夹然后执行安装
cd custom_nodes/ComfyUI-Hunyuan3DWrapper/hy3dgen/texgen/custom_rasterizer
python setup.py install安装成功后,应在Python环境的site-packages文件夹中看到custom_rasterizer_kernel*.pyd文件和custom_rasterizer文件夹。
编译mesh_processor扩展:
请参考 1.2.1 部分进入对应的桌面版终端后,使用 cd 命令进入对应文件夹然后执行安装
cd custom_nodes/ComfyUI-Hunyuan3DWrapper/hy3dgen/texgen/differentiable_renderer
python setup.py build_ext --inplace这个文件应该存在于该文件夹中。它仅用于顶点修复,如果此文件不存在,将在CPU上运行备用方案,速度会慢很多。顶点修复在单独的节点上,最坏情况下可以绕过,缺点是纹理填充效果较差。
1.3 可选安装: BPT(边界保护变换)
该组件是完全可选的,但安装要求较高:
请参考 1.2.1 部分进入对应的桌面版终端后,使用 cd 命令进入对应文件夹然后执行安装
cd custom_nodes/ComfyUI-Hunyuan3DWrapper/hy3dgen/shapegen/bpt
pip install -r requirements.txt下载权重文件:bpt-8-16-500m.pt
将bpt-8-16-500m.pt复制到ComfyUI-Hunyuan3DWrapper-main\hy3dgen\shapegen\bpt目录。
1.4 修复高多边形模型UV包装的Xatlas升级程序
要修复高多边形模型的UV贴图问题,可以升级Xatlas:
首先卸载当前版本:
python_embeded\python.exe -m pip uninstall xatlas在便携版根目录(ComfyUI_windows_portable)下:
git clone --recursive https://github.com/mworchel/xatlas-python.git
cd .\xatlas-python\extern删除xatlas文件夹,然后克隆新版本:
git clone --recursive https://github.com/jpcy/xatlas在xatlas-python\extern\xatlas\source\xatlas中修改xatlas.cpp文件:
- 将第6774行的
#if 0改为//#if 0 - 将第6778行的
#endif改为//#endif
最后返回便携版根目录(ComfyUI_windows_portable)执行:
.\python_embeded\python.exe -m pip install .\xatlas-python\2. Hunyuan3D 2.0 单视角工作流
Hunyuan3D 2.0 的模型不是一个多视角模型,因此在使用 ComfyUI-Hunyuan3DWrapper 时,需要使用 Hunyuan3D-DiT-v2-0 系列模型而非 Hunyuan3D-DiT-v2-mv 系列。该插件不仅支持模型几何形状生成,还支持纹理生成,可以生成完整的 3D 模型。
2.1 工作流文件
下载下面的工作流文件,并拖入 ComfyUI ,将会自动提示完成相关模型的下载。
2.2 手动模型安装
由于早期 Hunyuan3D 2.0 发布时并没有提供 safetensors 格式的模型,所以 Kijai 提供了对应的转换后的版本,但目前 Hunyuan3D 2.0 已经提供了 safetensors 格式的模型,你可以从下面任选一个模型进行下载,并保存到 ComfyUI/models/diffusion_models/ 目录下。
- Kijai:hunyuan3d-dit-v2-0-fp16.safetensors
- Tencent:hunyuan3d-dit-v2-0/model.fp16.safetensors 下载后重命名为
hunyuan3d-dit-v2-0.safetensors
2.3 按图片完成工作流的运行
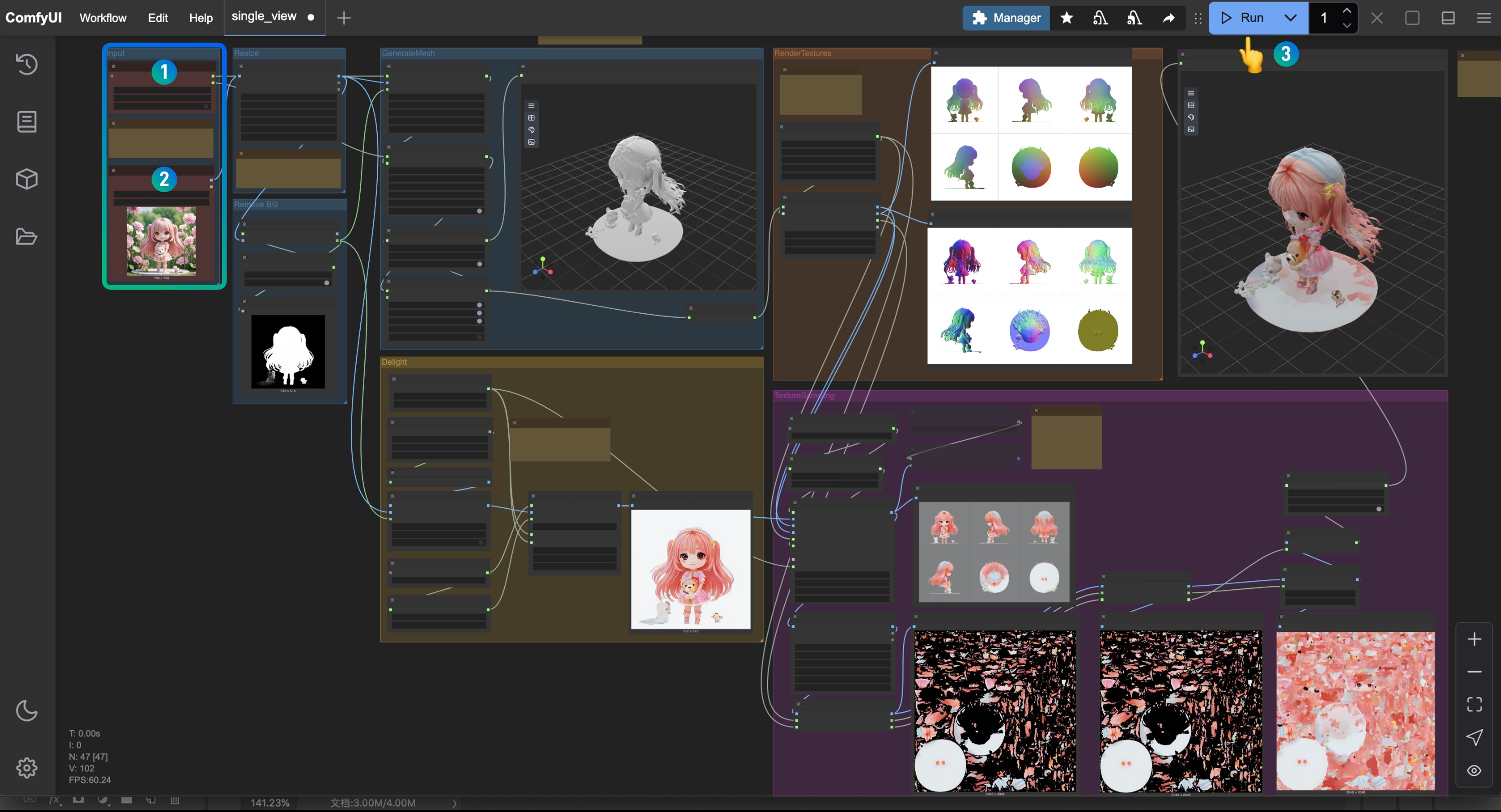
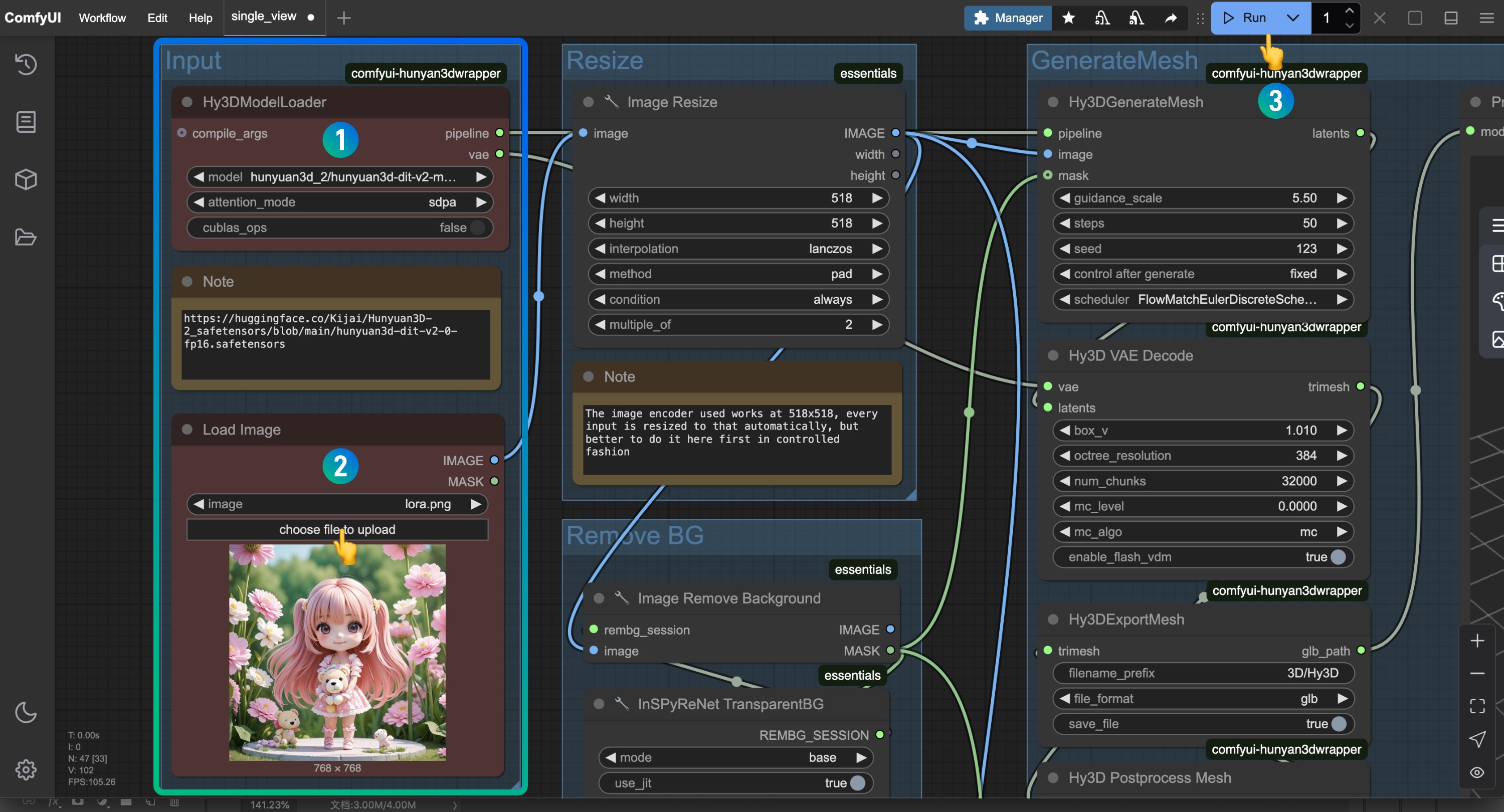
- 请在
Hy3DModelLoader处确保对应的hunyuan3d-dit-v2-0.safetensors已经加载 - 请在
Load Image节点处加载对应的输入图片,用于模型生成 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
如果有出现关于 custom_rasterizer 的报错,请参考插件安装部分提供的解决方便进行对应的依赖组件的安装或者编译
对应模型将会输出至 ComfyUI/output/3D 文件夹中,这个是在Hy3DExportMesh节点中设置的输出路径
3. Hunyuan3D 2.0 多视角工作流
3.1 工作流文件
下载下面的工作流文件,并拖入 ComfyUI ,将会自动提示完成相关模型的下载。
3.2 手动模型安装
Hunyuan3D 2mv 多视角模型与之前相同,Kijai 也提供了早期转换过的版本,后续tencent 也提供了对应的 safetensors 版本,你可以从下面任选一个模型进行下载,并保存到 ComfyUI/models/diffusion_models/ 目录下。
- Kijai:hunyuan3d-dit-v2-0-fp16.safetensors
- Tencent:hunyuan3d-dit-v2-mv/model.fp16.safetensors 下载后重命名为
hunyuan3d-dit-v2-mv-fp16.safetensors
如果生成运行太过缓慢,你可以尝试使用:
3.3 按图片完成工作流的运行
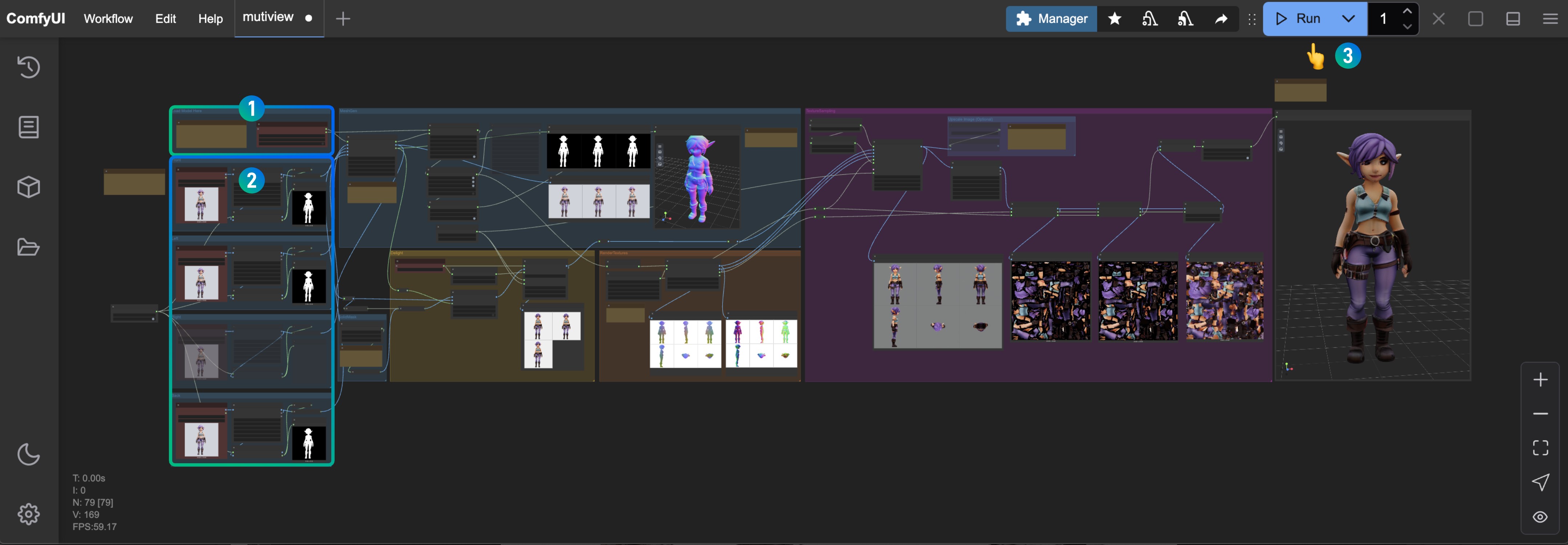
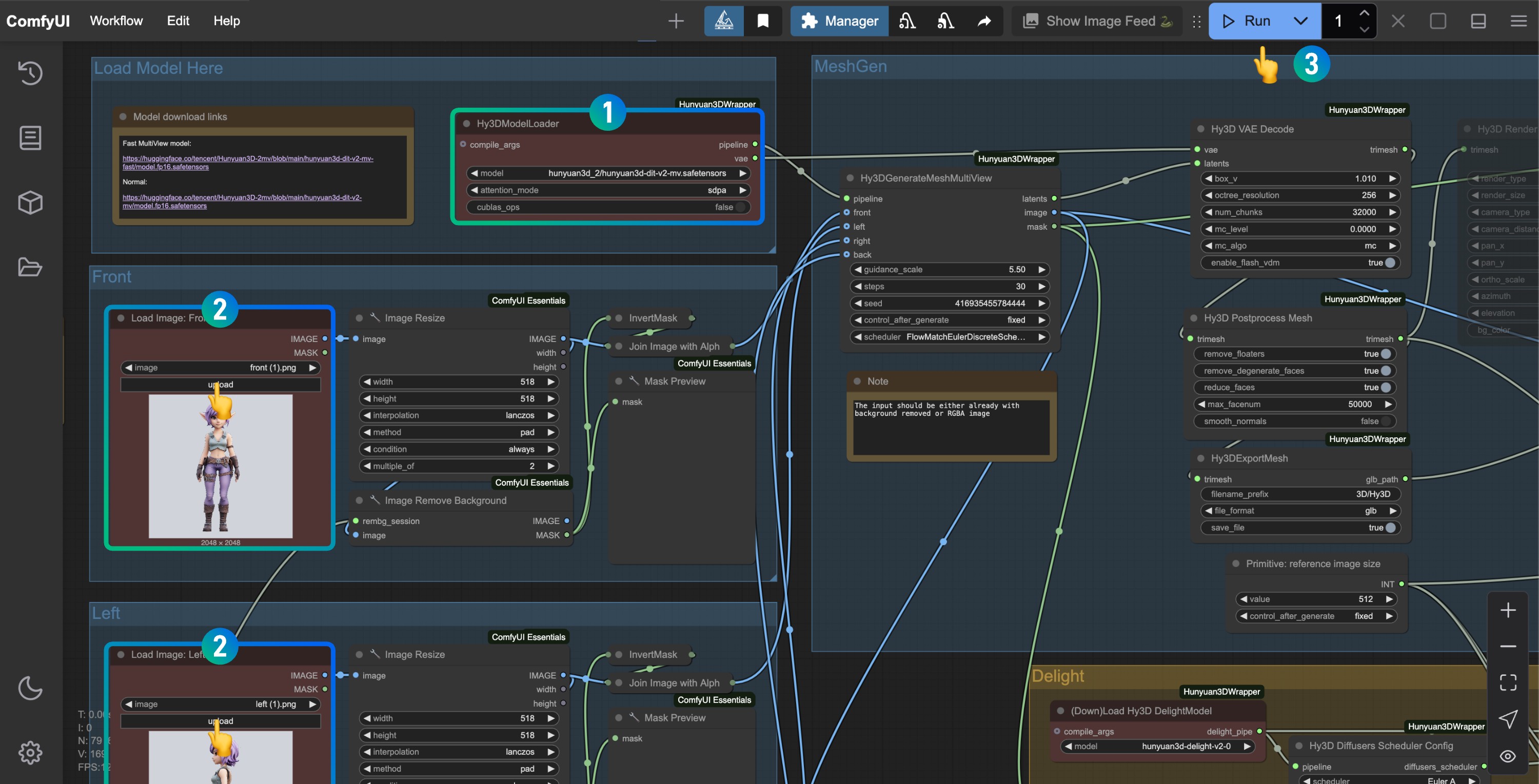
- 请在
Hy3DModelLoader处确保对应的hunyuan3d-dit-v2-mv-fp16.safetensors已经加载 - 请在
Load Image节点出上传不同视角的输入图片,如果对应视角的图片没有,请在右键将对应的节点 mode 设置为Never - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
ComfyUI 原生 Hunyuan3D 2.0 工作流
目前 ComfyUI 已经原生支持 Hunyuan3D-2mv 系列模型,可以直接生成 3D 几何模型(暂不支持纹理材质),只需要升级 ComfyUI 到最新版本即可体验。 由于 ComfyUI Wiki 已经开始和 Comfy 官方一起协作维护Comfy 官方文档,这部分内容在 Comfy 官方文档 中我们已有详细介绍。 但目前官方文档我们仅对中英文进行了支持,为了方便 ComfyUI Wiki 的读者,ComfyUI Wiki 对原本发布在 docs.comfy.org 在我们的站点进行了重新的整理和编辑。
目前 ComfyUI 提供三个原生的工作流,主要是对 Hunyuan3D 2.0 和 Hunyuan3D-2mv 系列模型的支持。
- Hunyuan3D-2mv 多视角工作流
- Hunyuan3D-2mv-turbo 多视角加速版工作流
- Hunyuan3D-2 单视角工作流
目前这个工作流已经在最新版本的 ComfyUI 工作流模板中新增了,你可以看到在菜单栏 workflow -> workflow templates -> 3d 中看到对应的 Hunyuan3D 2.0 工作流
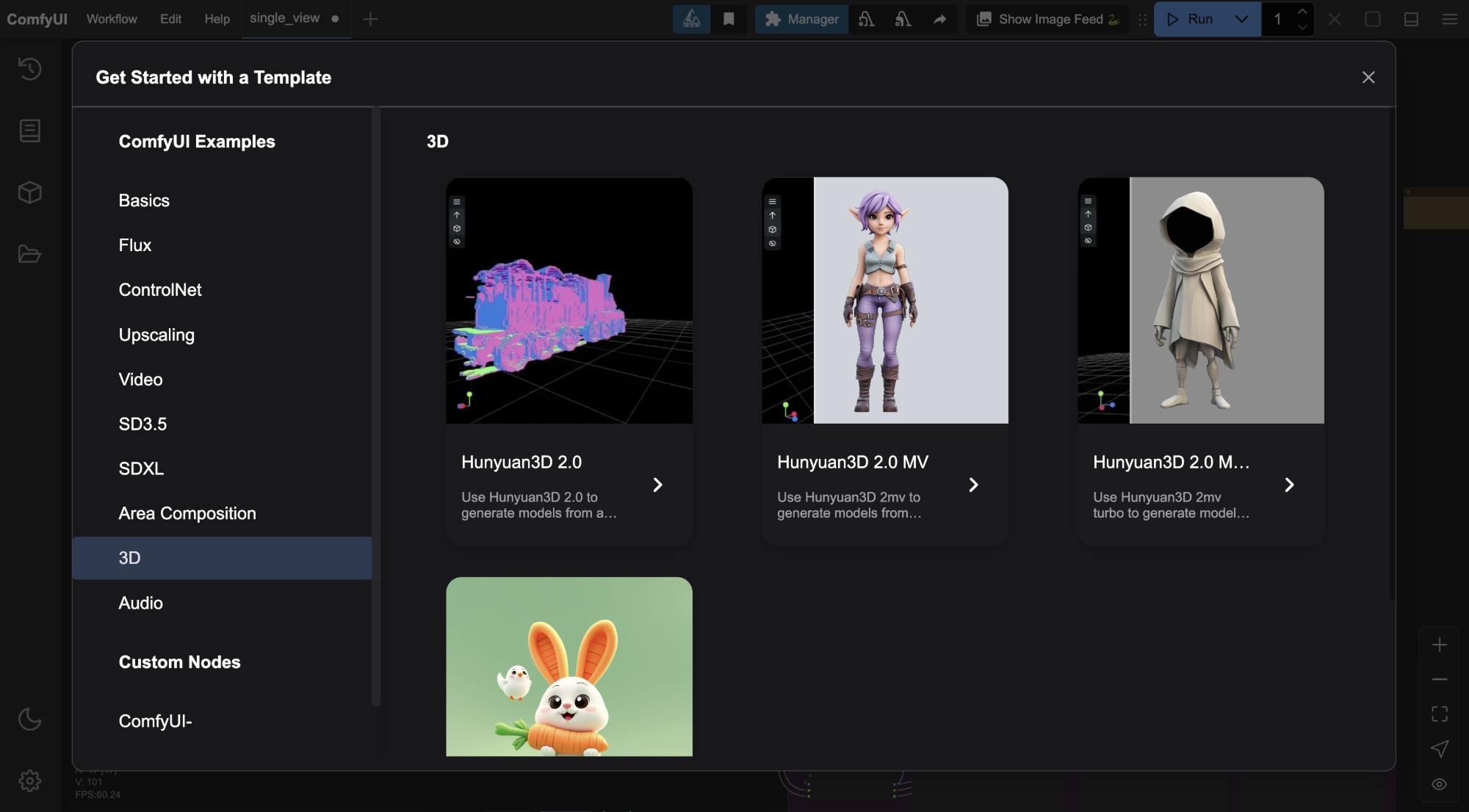
请在开始这部分内容之前,确保你已经升级到了最新版本的 ComfyUI,你可以参考ComfyUI 升级指南 进行 ComfyUI 的更新。
- 与 ComfyUI-Hunyuan3DWrapper 对比,原生工作流把对应模型位置保存在
ComfyUI/models/checkpoints/目录下,使用的模型是相同的的,所以如果你之前使用的是 ComfyUI-Hunyuan3DWrapper 插件工作流,注意调整下对应模型保存的目录。 - 对应
.glb文件的输出位置在ComfyUI/output/mesh目录下,这个是在SaveGLB节点中设置的输出路径。
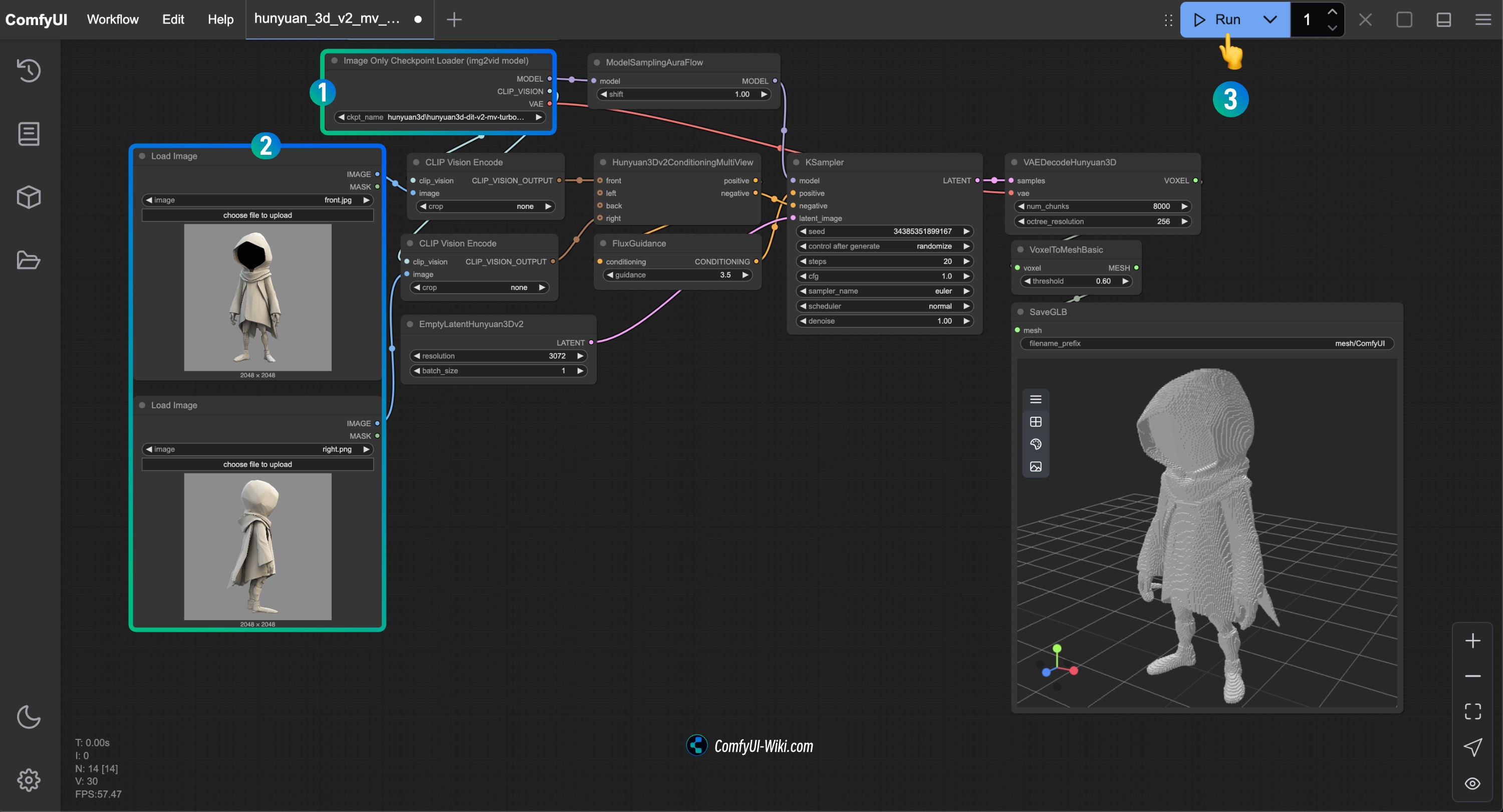
1. 使用 Hunyuan3D-2mv 多视角工作流
1.1 工作流示例
下载下面的图片,并拖入 ComfyUI 中,将会自动提示完成相关模型的下载。
1.2 手动模型安装
下载 hunyuan3d-dit-v2-mv.safetensors 并保存到 ComfyUI/models/checkpoints/ 目录, 并重命名为 hunyuan3d-dit-v2-mv.safetensors。
1.3 按步骤完成工作流的运行
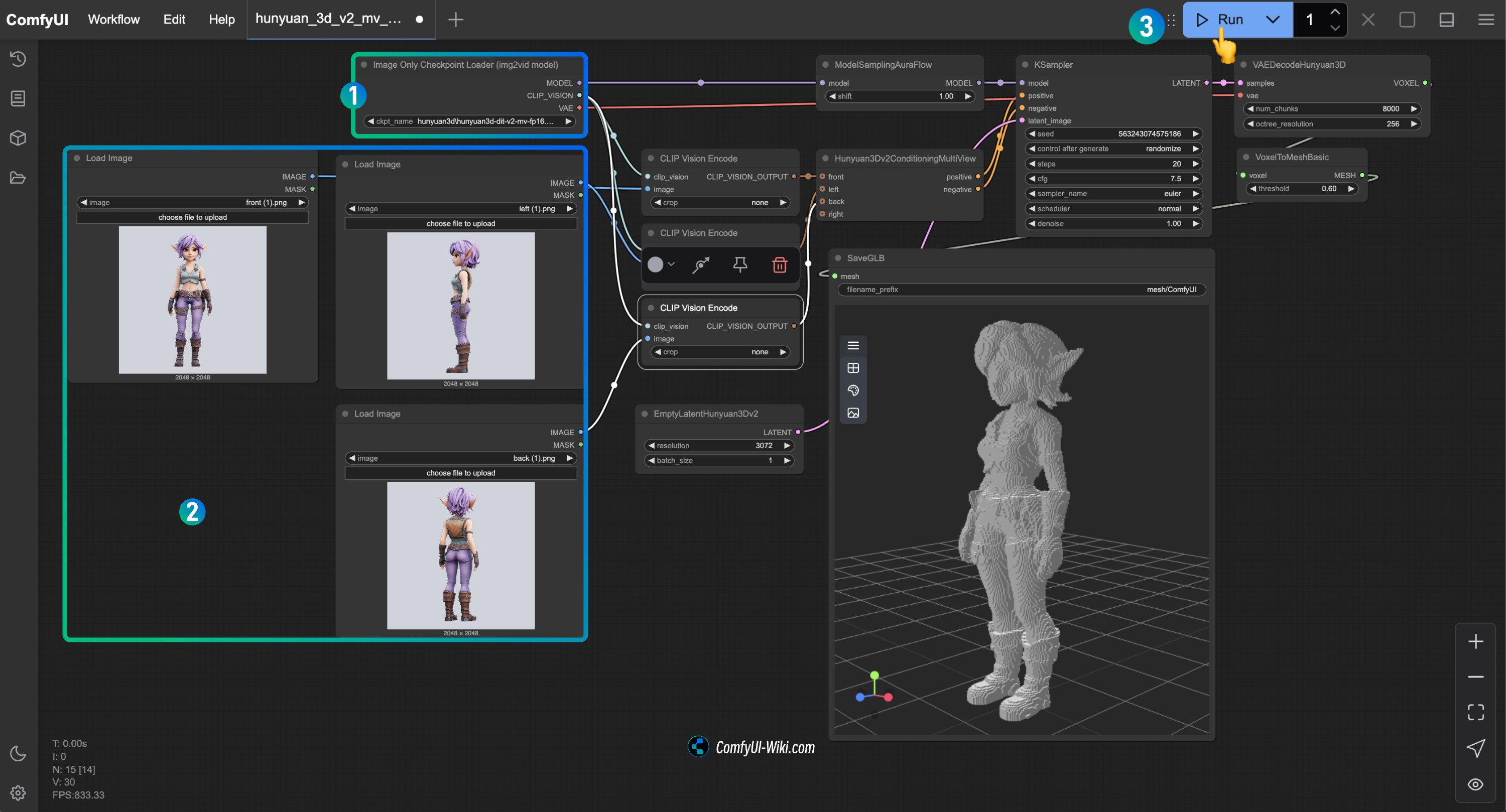
- 确保
Image Only Checkpoint Loader(img2vid model)节点加载了 hunyuan3d-dit-v2-mv.safetensors 模型 - 在各个
Load Image节点中加载对应视角的图片 - 运行工作流生成 3D 模型
2. 使用 Hunyuan3D-2mv-turbo 加速版工作流
Hunyuan3D-2mv-turbo 是 Hunyuan3D-2mv 的蒸馏版本,运行速度更快。
2.1 工作流示例
下载下面的图片,并拖入 ComfyUI 中,将会自动提示完成相关模型的下载。
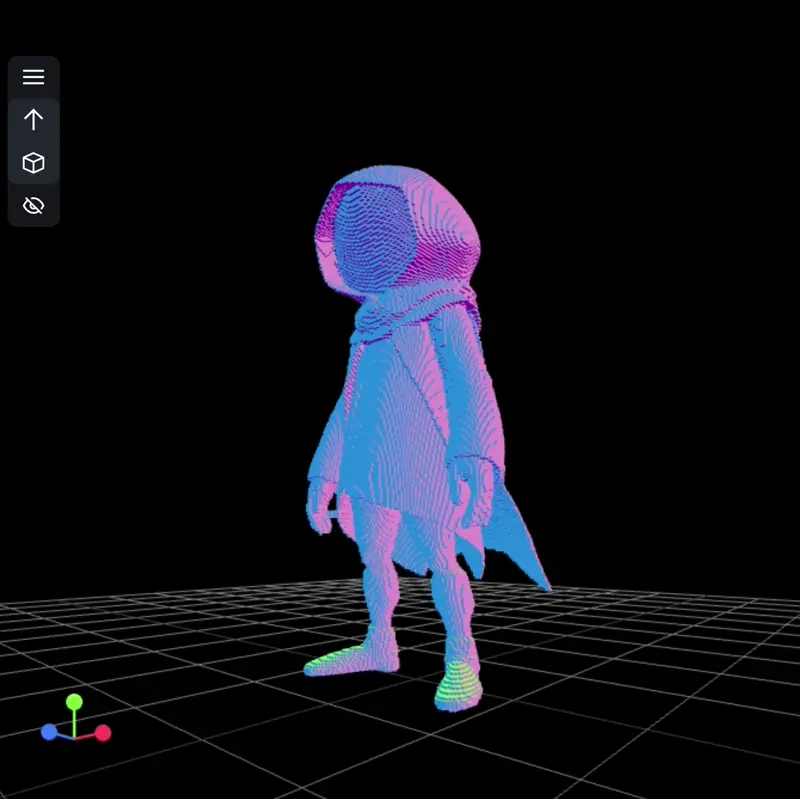
2.2 手动模型安装
下载 hunyuan3d-dit-v2-mv-turbo.safetensors 重命名为 hunyuan3d-dit-v2-mv-turbo.safetensors并保存到 ComfyUI/models/checkpoints/ 目录下。
2.3 按步骤完成工作流的运行
- 确保
Image Only Checkpoint Loader(img2vid model)节点加载了 hunyuan3d-dit-v2-mv-turbo.safetensors 模型 - 在各个
Load Image节点中加载对应视角的图片 - 在此工作流中,注意 cfg 设置为 1.0,并增加了
flux guidance节点来控制蒸馏 cfg 的生成 - 运行工作流生成 3D 模型
3. 使用 Hunyuan3D-2 单视角工作流
Hunyuan3D-2 模型支持单视角输入生成 3D 模型。
3.1 工作流示例
下载下面的图片,并拖入 ComfyUI 中,将会自动提示完成相关模型的下载。

3.2 输入图像示例

3.3 手动安装模型
下载 hunyuan3d-dit-v2.safetensors 重命名为hunyuan3d-dit-v2.safetensors 并保存到 ComfyUI/models/checkpoints/ 目录,
3.4 按步骤完成工作流的运行
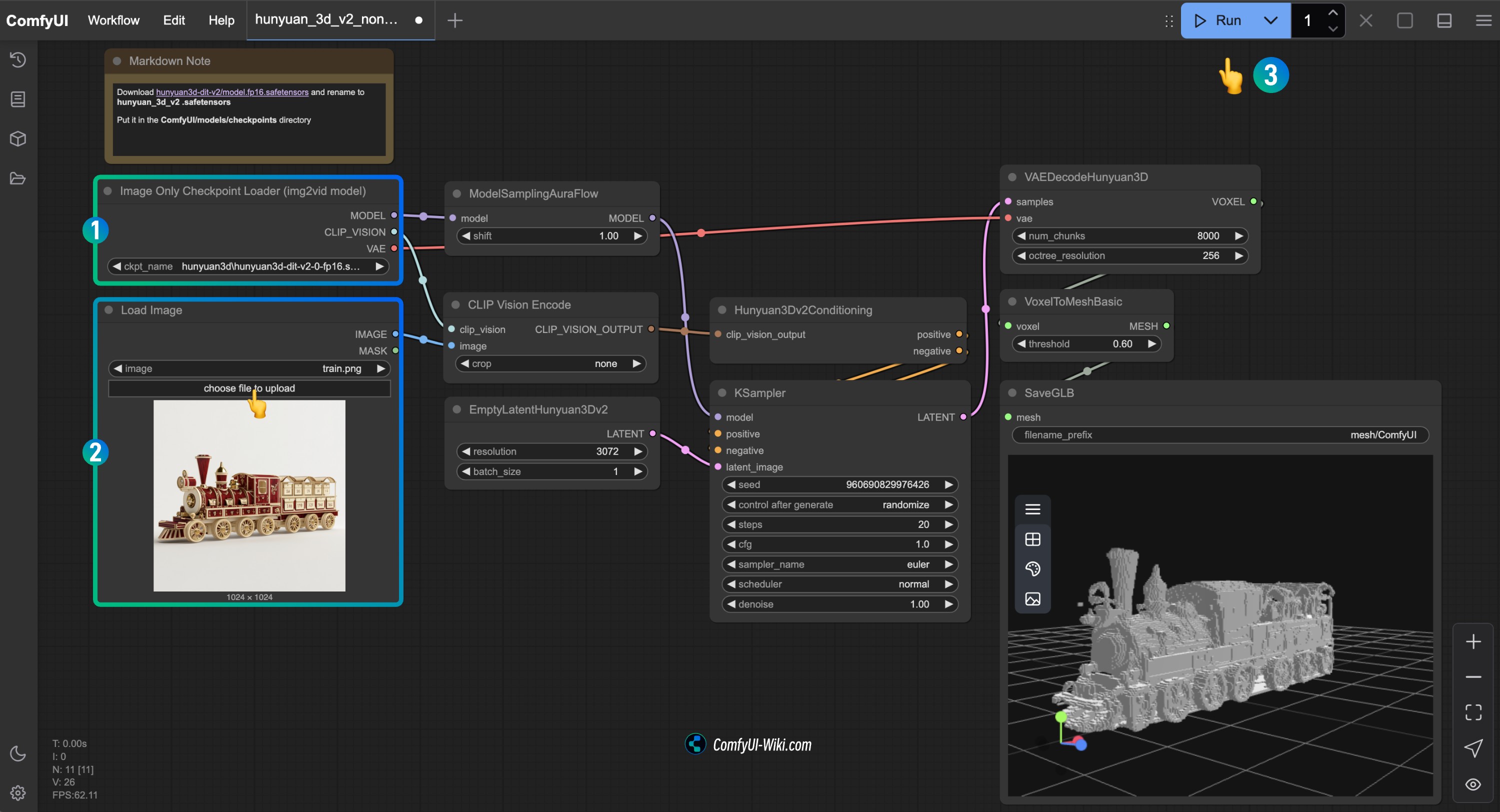
- 确保
Image Only Checkpoint Loader(img2vid model)节点加载了hunyuan3d-dit-v2.safetensors模型 - 在
Load Image节点中加载输入图片 - 注意此工作流使用
Hunyuan3Dv2Conditioning节点而非Hunyuan3Dv2ConditioningMultiView - 运行工作流生成 3D 模型
ComfyUI 3D Pack
在安装 ComfyUI 3D Pack 时可能遇到的主要问题是依赖关系冲突。该插件依赖的环境与最新版本的 ComfyUI 环境有所不同,特别是在 PyTorch 版本和 CUDA 版本支持方面。如果你想尝试,可以参考 ComfyUI-3D-Pack 项目的安装说明。 另外有社区用户提供了对应的整合包的形式,你可以尝试Comfy3D-WinPortable | 整合包来体验
其它补充内容
如何进行文生模型
在上面的工作流中,我们使用的都是输入图片的形式,你可以在这个工作流之前加上一个文生图的工作流,来完成对应图片部分的内容生成,如果需要多视角的输入,你可以尝试使用ComfyUI-MVAdapter 插件的功能来完成对应角色的多角度图片生成。
混元3D 2.0 开源模型系列
目前混元3D 2.0 开源了多个模型,覆盖了完整的3D生成流程,你可以访问 Hunyuan3D-2 了解更多。
Hunyuan3D-2mini 系列
| 模型 | 描述 | 日期 | 参数 | Huggingface |
|---|---|---|---|---|
| Hunyuan3D-DiT-v2-mini | Mini 图像到形状模型 | 2025-03-18 | 0.6B | 前往 |
Hunyuan3D-2mv 系列
| 模型 | 描述 | 日期 | 参数 | Huggingface |
|---|---|---|---|---|
| Hunyuan3D-DiT-v2-mv-Fast | 指导蒸馏版本,可以将 DIT 推理时间减半 | 2025-03-18 | 1.1B | 前往 |
| Hunyuan3D-DiT-v2-mv | 多视角图像到形状模型,适合需要用多个角度理解场景的 3D 创作 | 2025-03-18 | 1.1B | 前往 |
Hunyuan3D-2 系列
| 模型 | 描述 | 日期 | 参数 | Huggingface |
|---|---|---|---|---|
| Hunyuan3D-DiT-v2-0-Fast | 指导蒸馏模型 | 2025-02-03 | 1.1B | 前往 |
| Hunyuan3D-DiT-v2-0 | 图像到形状模型 | 2025-01-21 | 1.1B | 前往 |
| Hunyuan3D-Paint-v2-0 | 纹理生成模型 | 2025-01-21 | 1.3B | 前往 |
| Hunyuan3D-Delight-v2-0 | 图像去光影模型 | 2025-01-21 | 1.3B | 前往 |
Hunyuan 3D 2.0 相关链接
- Hunyuan3D 主页: https://3d.hunyuan.tencent.com
- Hunyuan3D-2 演示: https://huggingface.co/spaces/tencent/Hunyuan3D-2
- Hunyuan3D-2 模型: https://huggingface.co/Tencent/Hunyuan3D-2
- Hunyuan3D-2mv 模型: https://huggingface.co/tencent/Hunyuan3D-2mv
- Hunyuan3D-2mv 演示: https://huggingface.co/spaces/tencent/Hunyuan3D-2mv
- GitHub: https://github.com/Tencent/Hunyuan3D-2
- Discord: https://discord.gg/GuaWYwzKbX
- 报告: https://github.com/Tencent/Hunyuan3D-2/blob/main/assets/report/Tencent_Hunyuan3D_2_0.pdf
- 官方网站: http://3d-models.hunyuan.tencent.com
ComfyUI ACE-Step 音乐生成工作流完整指南
ACE-Step是由中国团队阶跃星辰(StepFun)与ACE Studio联合开发的开源音乐生成基础大模型,旨在为音乐创作者提供高效、灵活且高质量的音乐生成与编辑工具。
该模型采用Apache-2.0许可证发布,可免费商用。
ACE-Step 作为一个强大的音乐生成的基座模型,提供了丰富的扩展能力。可以通过 LoRA、ControlNet 等微调技术,开发者可以根据实际需求对模型进行定制化训练。 无论是音频编辑、歌声合成、伴奏制作、声音克隆还是风格转换等应用场景,ACE-Step 都能提供稳定可靠的技术支持。 这种灵活的架构设计大大简化了音乐 AI 应用的开发流程,让更多创作者能够快速将 AI 技术应用到音乐创作中。
目前 ACE-Step 已经发布相关的训练代码,包括 LoRA 模型训练等,对应 ControlNet 的训练代码也将在未来陆续发布,你可以访问他们的Github 来了解更多详情。
在ComfyUI 中 ACE-Step 的实现及关于多语言的实现的说明
在 ACE-Step 模型针对多语言的实现,主要是通过将不同语言统一转换成为对应的英文字符,然后进行音乐生成的,但是目前在 ComfyUI 原生的支持中并没有实现不同语言到英文字符转换的这一步,仅对日文片假名进行了匹配转换可以查看这个commit。 因为实现这一步需要引入额外的依赖,对核心依赖贸然增加可能会导致各种潜在的问题和自定义节点冲突,所以目前在 ComfyUI 中我们不能够直接使用不同语言来输入,而是需要转为对应的英文字符。
不过目前有自定义节点作者实现了对应的语言的转换,可以实现多语言的直接输入,所在在本文档中我们将会结合原生工作流和自定义节点来完成 ACE-Step 的工作流,你可能已经下载了这个文件。 下面是对两种ACE-Step 在 ComfyUI 实现方式的说明。
1. ComfyUI 原生支持
- 优点: 使用合并的 All in one 模型加载方便,使用简单
- 缺点: 不支持多语言直接输入,需要把对应的语言转换成对应的英文字符,然后进行音乐生成
目前在 ComfyUI 已经原生支持了 ACE-Step 但是缺点是并不支持直接的多语言输入,
2. 自定义节点 ComfyUI_ACE-Step 的实现
ComfyUI_ACE-Step ,主要实现了多语言直接输入,并且支持了多语言的歌词输入,并且支持了多语言的提示词输入。
- 优点: 支持多语言直接输入,使用简单
- 缺点: 没有使用合并的模型,需要下载多个模型
这个自定义节点目前在它的核心依赖中添加了比如日语、中文、韩语翻译的依赖,所以使用这个节点你可以直接使用多语言来进行音乐生成,另外作者也针对多语言混合输入有进行处理优化。
在本篇教程工作流我们会添加 ComfyUI_ACE-Step 的对应 ACE-Step Lyrics Language Switch 如果你需要使用多语言输入时,可以大大方便对应的语言输入。
不过在测试中发现,这个语言转换的节点似乎对日文的转换还存在一定问题,所以目前如果想要使用日语进行歌曲生成,那么请直接使用日文片假名进行输入

另外我提供的工作流中,对应的节点默认是 绕过(Bypass) 模式,所以如果你需要启动多语言输入还需要在节点上右键将对应节点的模式设置为 总是(Always) 模式。

开始前的准备
- 请升级你的 ComfyUI 到最新版本,保证你有对应的原生支持
- (可选,如果你需要多语言直接输入的话)安装 ComfyUI_ACE-Step 插件(直接使用 ComfyUI Manager 来进行安装)
- 模型下载, 下载ace_step_v1_3.5b.safetensors 后保存到
ComfyUI/models/checkpoints文件夹下
ComfyUI ACE-Step 文本到音频生成
1. 工作流文件下载
点击下面的按钮下载对应的工作流文件,拖入 ComfyUI 中即可加载对应的工作流信息,对应工作流已包含模型下载信息。
2. 按步骤完成工作流的运行
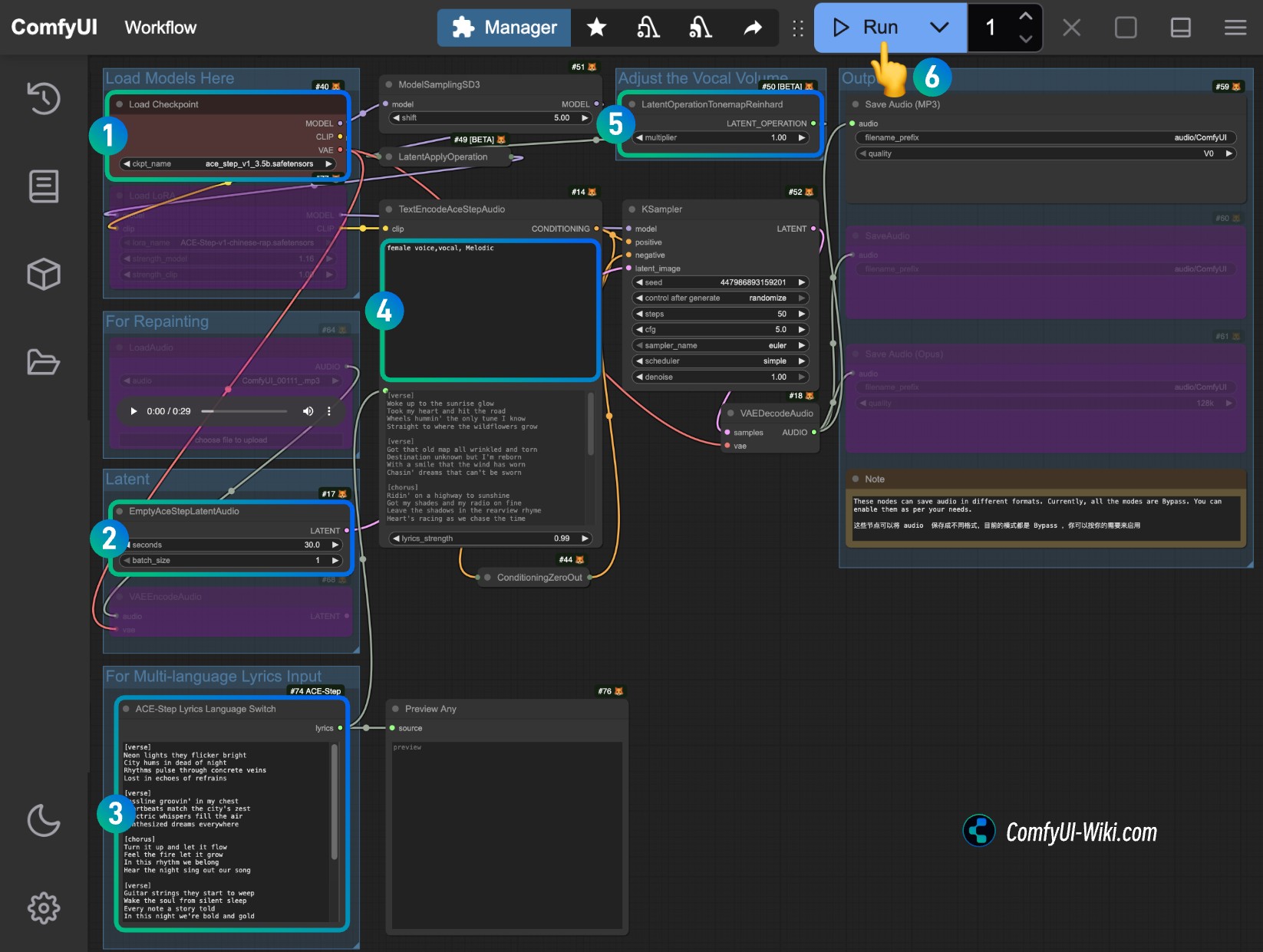
- 确保
Load Checkpoints节点加载了ace_step_v1_3.5b.safetensors模型 - (可选)在
EmptyAceStepLatentAudio节点上你可以设置生成音乐的时长 - (可选)在
ACE-Step Lyrics Language Switch的输入对应的歌词,如果你不知道如何输入可以参考ACE-Step 项目页,如果你需要日文输入请删除这个部分直接使用 ComfyUI 原生的节点输入日文片假名。 - (可选)在
TextEncodeAceStepAudio的tags输入对应的音乐风格等等 - (可选)在
LatentOperationTonemapReinhard节点,你可以调整multiplier来调整人声的音量大小(数字越大,人声音量越明显) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行音频的生成。 - 工作流完成后,你可在
Save Audio节点中查看生成的音频,你可以点击播放试听,对应的音频也会被保存至ComfyUI/output/audio(由Save Audio节点决定子目录名称)。
ComfyUI ACE-Step 音频到音频
在使用 ACE Step 音频到音频工作流时,你可以像图生图工作流一样,输入一段音乐,使用下面的工作流来达到重新对音乐采样生成,同样,你也可以通过控制 Ksampler 的 denoise 来调整和原始音频的区别程度。
你可以实现:
- 对音乐风格的调整
- 修改部分的歌词等等
你可以在ACE-Step 项目页看到更多的示例
1. 工作流文件下载
点击下面的按钮下载对应的工作流文件,拖入 ComfyUI 中即可加载对应的工作流信息
我们可以使用文生音频工作流中的音频作为输入音频
2. 按步骤完成工作流的运行
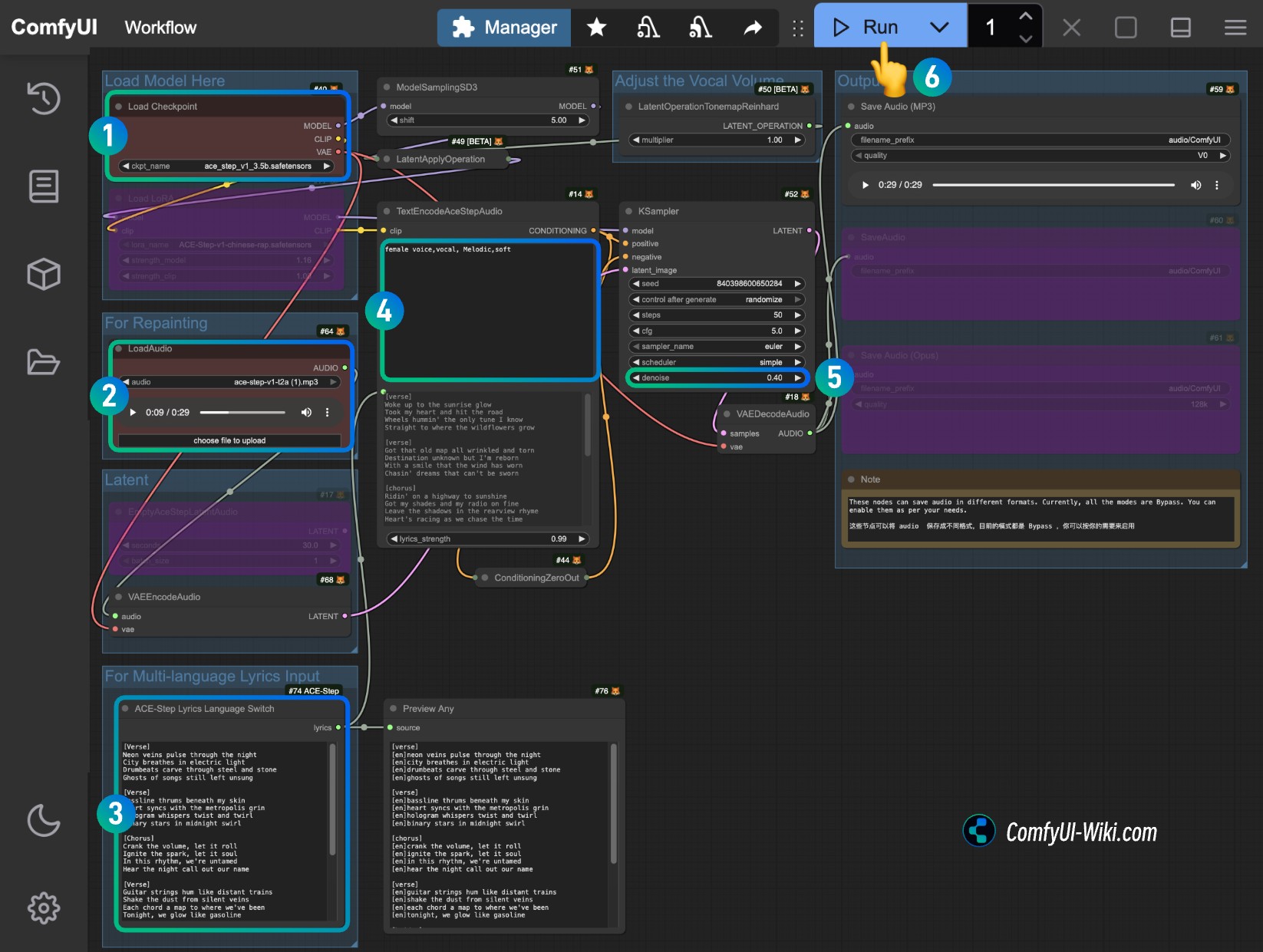
- 确保
Load Checkpoints节点加载了ace_step_v1_3.5b.safetensors模型 - 在
LoadAudio节点上上传用于编辑的音频 - (可选)在
ACE-Step Lyrics Language Switch的输入修改后的歌词,可以参考ACE-Step 项目页 - (可选)在
TextEncodeAceStepAudio的tags输入对应的音乐风格 - (可选)修改
KSampler节点的denoise参数(数字越大和原始的音频差别越大) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行音频的生成。 - 工作流完成后,你可在
Save Audio节点中查看生成的音频,你可以点击播放试听,对应的音频也会被保存至ComfyUI/output/audio(由Save Audio节点决定子目录名称)。
ComfyUI ACE-Step LoRA
目前 ACE-Step 官方发布了一个 Chinese RAP 风格的 LoRA 模型,你可以访问 ACE-Step/ACE-Step-v1-chinese-rap-LoRA 来下载对应的 LoRA 模型,记得重命名为 ace-step-v1-chinese-rap-lora.safetensors 在开始前你需要手动将对应的文件下载并保存到 ComfyUI/models/loras 文件夹下
1. 工作流文件下载
2. 按步骤完成工作流的运行
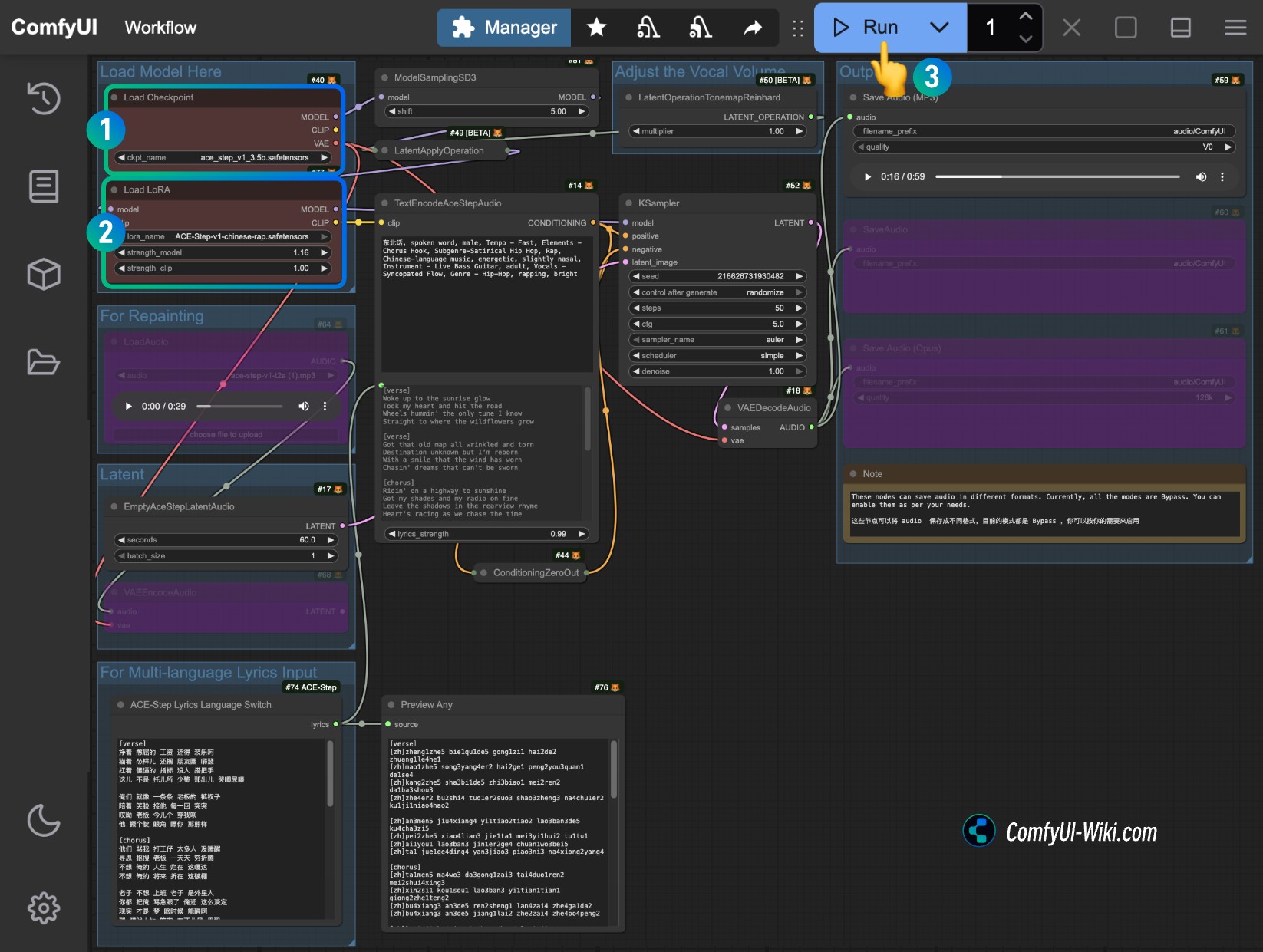
- 确保
Load Checkpoints节点加载了ace_step_v1_3.5b.safetensors模型 - 在
Load LoRA节点上添加ace-step-v1-chinese-rap-lora.safetensors模型 - 其它选项修改与文生视频等一致,请点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行音频的生成。 - 工作流完成后,你可在
Save Audio节点中查看生成的音频,你可以点击播放试听,对应的音频也会被保存至ComfyUI/output/audio(由Save Audio节点决定子目录名称)。
ACE-Step 音乐扩展
ACE-Step 提示词指南
ACE 的提示词目前使用的有两个,一个是 tags 一个是 lyrics。
tags: 主要用来描述音乐的风格、场景等, 和我们平常其它生成的 prompt 类似,主要描述音频整体的风格和要求,使用英文逗号分隔lyrics: 主要用来描述歌词,支持歌词结构标签,如 [verse](主歌)、[chorus](副歌)和 [bridge](过渡段)来区分歌词的不同部分,也可以在纯音乐情况下输入乐器名称
对应的 tags 和 lyrics 在 ACE-Step 模型主页 中可以找到丰富的示例,你可以参考对应示例来尝试对应的提示词,
下面的提示词我在 ComfyUI 的官方文档也有做了整理,基本上都是来自ACE-Step 项目主页,建议你可以访问他们的官方文档来了解如何撰写提示词。
tags标签(prompt)
主流音乐风格
使用简短标签组合,来生成特定风格的音乐
- electronic(电子音乐)
- rock(摇滚)
- pop(流行)
- funk(放克)
- soul(灵魂乐)
- cyberpunk(赛博朋克)
- Acid jazz(酸爵士)
- electro(电子)
- em(电子音乐)
- soft electric drums(软电鼓)
- melodic(旋律)
更多音乐风格组合示例
- DUBSTEP, DARKNESS, FEAR, TERROR(重复标签可增强效果)
- dark, death rock, metal, hardcore, electric guitar, powerful, bass, drums, 110 bpm, G major
- Cuban music, salsa, son, Afro-Cuban, traditional Cuban
- alternative rock, pop, rock
- dark electro, industrial techno, gothic rave
- disco
- electronic rap
- country rock, folk rock, southern rock, bluegrass, pop
- melancholic, world, sad
场景类型
结合具体使用场景和氛围,生成符合对应氛围的音乐
- background music for parties(派对背景音乐)
- radio broadcasts(电台广播音乐)
- workout playlists(健身播放列表音乐)
乐器元素
- saxophone, jazz(萨克斯风、爵士)
- piano, violin(钢琴、小提琴)
- 808 bass, sub bassline(808低音、副低音线)
- orchestral, synthesizer, violin, viola, cello(管弦乐、合成器、小提琴、中提琴、大提琴)
- phonk, russian dark accordion, russian psaltery, russian harmonica(俄罗斯手风琴、俄罗斯古筝、俄罗斯口琴)
人声类型
- female voice(女声)
- male voice(男声)
- clean vocals(纯净人声)
- crystal-clear soprano voice(清澈的女高音)
- deep male voice(深沉男声)
专业用语
使用音乐中常用的一些专业用词,来精准控制音乐效果:
- 110 bpm, 140 bpm, 160 bpm(指定每分钟节拍数)
- fast tempo(快节奏)
- slow tempo(慢节奏)
- loops(循环片段)
- fills(填充音)
- acoustic guitar(木吉他)
- electric bass(电贝斯)
- G major, B flat major, D minor(G大调、降B大调、D小调)
高级控制参数
变体控制
控制生成音乐与原始风格的差异程度:
- variance=0.1(相似度很高,几乎相同)
- variance=0.3(适度变化,保留基本风格)
- variance=0.5(中等变化,有明显差异)
- variance=0.7(较大变化,风格转变明显)
音频重绘(Repaint)
可以修改音频的特定方面或区域,同时保留其余部分:
- change singing gender(改变演唱性别)
- change style(改变音乐风格)
- change lyrics(改变特定歌词)
特殊音乐类型提示词
- 纯人声/清唱:使用”a cappella”标签,歌词可以使用元音字母组合(如”aaaaaaaa, eeeeeeeee”)
- 说唱/节奏控制:使用”b-box, deep male voice, trap, hip-hop, super fast tempo”
- 实验性音乐:可以使用非常规输入如元音重复或特殊文本格式
- 纯器乐:在lyrics部分使用”[inst]“标记
实验性输入格式
可以尝试使用更结构化的HTML格式描述音乐,例如:
歌词(lyrics)
歌词结构标签
- [intro] (前奏)
- [verse] (主歌)
- [pre-chorus] (导歌)
- [chorus] (副歌/合唱)
- [bridge] (过渡段/桥段)
- [outro] (尾声)
- [hook] (钩子/主题旋律)
- [refrain] (重复段落)
- [interlude] (间奏)
- [breakdown] (分解段)
- [ad-lib] (即兴段落)
纯器乐音乐
对于纯器乐音乐,可以在lyrics部分使用: [inst] 或者指定乐器演奏部分:
多语言支持
- ACE-Step V1 是支持多语言的,实际使用的时候 ACE-Step 会获取到对应的不同语言转换后的英文字母,然后进行音乐生成。
- 在 ComfyUI 中我们并没有完全实现全部多语言到英文字母的转换,目前仅实现了日语平假名和片假名字符
所以如果你需要使用多语言来进行相关的音乐生成,你需要首先将对应的语言转换成英文字母,然后在对应
lyrics开头输入对应语言代码的缩写,比如中文[zh]韩语[ko]等,或者用我在本文提到的ACE-Step Lyrics Language Switch节点来完成对应语言的转换。
比如:
[verse]
[zh]wo3zou3guo4shen1ye4de5jie1dao4
[zh]leng3feng1chui1luan4si1nian4de5piao4liang4wai4tao4
[zh]ni3de5wei1xiao4xiang4xing1guang1hen3xuan4yao4
[zh]zhao4liang4le5wo3gu1du2de5mei3fen1mei3miao3
[chorus]
[verse]
[ko]hamkke si-kkeuleo-un sesang-ui sodong-eul pihae
[ko]honja ogsang-eseo dalbich-ui eolyeompus-ileul balaboda
[ko]niga salang-eun lideum-i ganghan eum-ag gatdago malhaess-eo
[ko]han ta han tamada ma-eum-ui ondoga eolmana heojeonhanji ijge hae
[bridge]
[es]cantar mi anhelo por ti sin ocultar
[es]como poesía y pintura, lleno de anhelo indescifrable
[es]tu sombra es tan terca como el viento, inborrable
[es]persiguiéndote en vuelo, brilla como cruzar una mar de nubes
[chorus]
[fr]que tu sois le vent qui souffle sur ma main
[fr]un contact chaud comme la douce pluie printanière
[fr]que tu sois le vent qui s'entoure de mon corps
[fr]un amour profond qui ne s'éloignera jamais目前 ACE-Step 支持了 19 种语言,但下面十种语言的支持会更好一些:
- English
- Chinese: [zh]
- Russian: [ru]
- Spanish: [es]
- Japanese: [ja]
- German: [de]
- French: [fr]
- Portuguese: [pt]
- Italian: [it]
- Korean: [ko]
歌词编辑示例
在音频到音频工作流中,可以精确修改特定歌词:
- “When I was young” -> “when you were kid”
- “When I was young” -> “When I was old”
- “I’d listen to the radio” -> “I’d listen to the spotify”
- “It made me smile” -> “It made me cry”
也可以进行语言转换,保留相同的旋律和风格:
- “When I was young” -> “Quand j’étais jeune”(法语)
- “When I was young” -> “In meiner Jugend”(德语)
- “When I was young” -> “子供の頃に”(日语)
- “When I was young” -> “내가 어렸을 때”(韩语)
- “When I was young” -> “我小的时候”(中文)
但是在 ComfyUI 原生节点输入可能会比较麻烦,建议使用 ACE-Step Lyrics Language Switch 节点来完成对应语言的转换。
ACE-Step 相关资源
Flux Fill 工作流程详细教程

Flux.1 Fill Dev 是 Black Forest Labs 推出的开源图像编辑模型,属于 FLUX.1 Tools 套件中的重要组件,专注于图像修复(Inpainting)和扩展(Outpainting)任务。
在本篇教程里我们将简要介绍对应的模型,并提供完整的 Flux Fill 模型安装、工作流文件和使用教程。
在本篇中,我们将完成:
- Flux.1 fill dev inpainting 工作流
- Flux.1 fill dev outpainting 工作流
Flux.1 Fill dev 模型简介
Flux.1 Fill dev 是由 Black Forest Labs 推出的 FLUX.1 Tools 套件 中的核心工具之一,专为图像修复和扩展设计。该模型主要用于:
- 图像修复:填充图像中缺失或被移除的区域
- 图像扩展:无缝地扩展现有图像的边界
- 通过蒙版和提示词来精确控制生成内容
Flux.1 Fill dev 的核心特点:
- 强大的图像重绘(Inpainting)和扩绘(Outpainting)能力
- 出色的提示词理解和跟随能力,能够精确捕捉用户意图并与原图保持高度一致性
- 采用先进的引导蒸馏训练技术,使模型在保持高质量输出的同时更加高效
- 灵活的使用许可,生成的内容可以用于个人、科学和商业用途请查看FLUX.1 [dev] Non-Commercial License
Flux.1 Fill dev 模型仓库地址: Flux.1 Fill dev
Flux.1 Fill dev 完整版工作流
Flux.1 Fill dev Inpainting 工作流
1. inpainting 工作流文件下载
下载下面的图片,并拖入 ComfyUI 以加载工作流

我们将使用下面这张图片作为输入图片:

2. 手动模型安装
如果对应模型下载存在问题,请参考下面的模型文件列表,手动下载对应模型文件,并放置到 ComfyUI 的对应目录下。
你需要下载以下模型文件:
| 模型名称 | 文件名 | 安装位置 | 下载链接 |
|---|---|---|---|
| CLIP 模型 | clip_l.safetensors | ComfyUI/models/text_encoders | 下载 |
t5xxl_fp16.safetensors | ComfyUI/models/text_encoders | 下载 | |
| VAE 模型 | ae.safetensors | ComfyUI/models/vae | 下载 |
| Flux Fill 模型 | flux1-fill-dev.safetensors | ComfyUI/models/diffusion_models | 下载 |
文件保存位置:
3. 检查下面对应的节点,并完成对应工作流运行
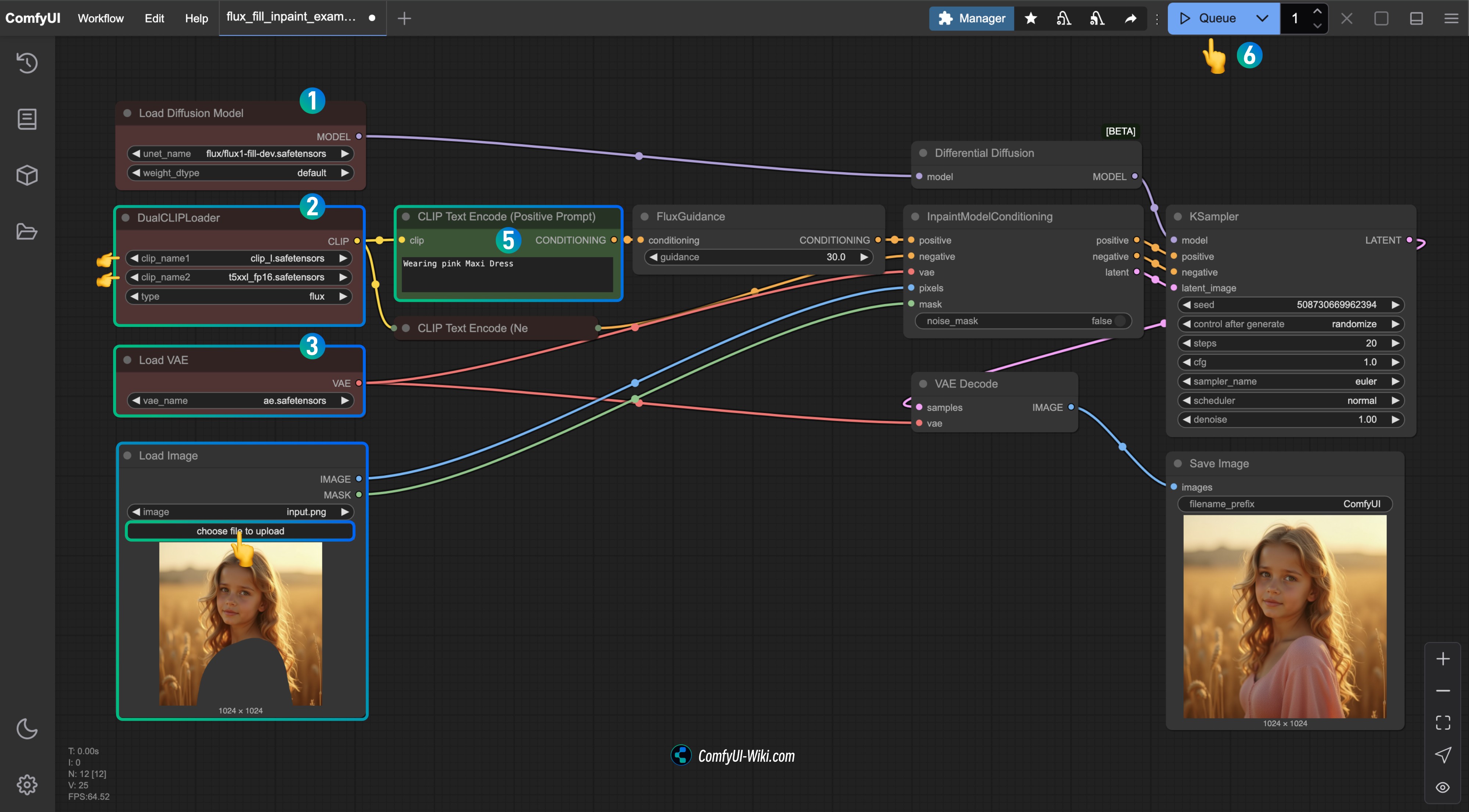
- 确保在
Load Diffusion Model节点加载了flux1-fill-dev.safetensors - 确保在
DualCLIPLoader节点中下面的模型已加载:- clip_name1: t5xxl_fp16.safetensors
- clip_name2: clip_l.safetensors
- 确保在
Load VAE节点中加载了ae.safetensors - 在
Load Image节点中上传了文档中提供的输入图片,如果你使用的是不带蒙版的版本,记得使用遮罩编辑器完成蒙版的绘制 - 在
CLIP Text Encode(Positive Prompt)节点中输入你希望修改图片蒙版部分的内容 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
4. 工作流说明
这个版本是一个完整版本的 inpainting 工作流,由于 Flux 系列模型对提示词优秀的理解能力,所以我们只需要输入简单的提示词,就可以得到一个非常不错的结果。
如果你是第一次新手并第一次使用 inpainting 工作流:
- 我们在
Load Image节点中上传了输入图片,并使用MaskEditor工具完成了蒙版的绘制,也就是标记出来了对应需要模型修改的区域
Flux.1 fill dev Outpainting 工作流
1. outpainting 工作流文件下载
下载下面的图片,并拖入 ComfyUI 以加载工作流

我们使用下面的这张图片作为输入图片:

2. 手动模型安装
对应模型安装与 inpaint 部分相同,请参考上面的 inpaint 部分。
3. 检查下面对应的节点,并完成对应工作流运行
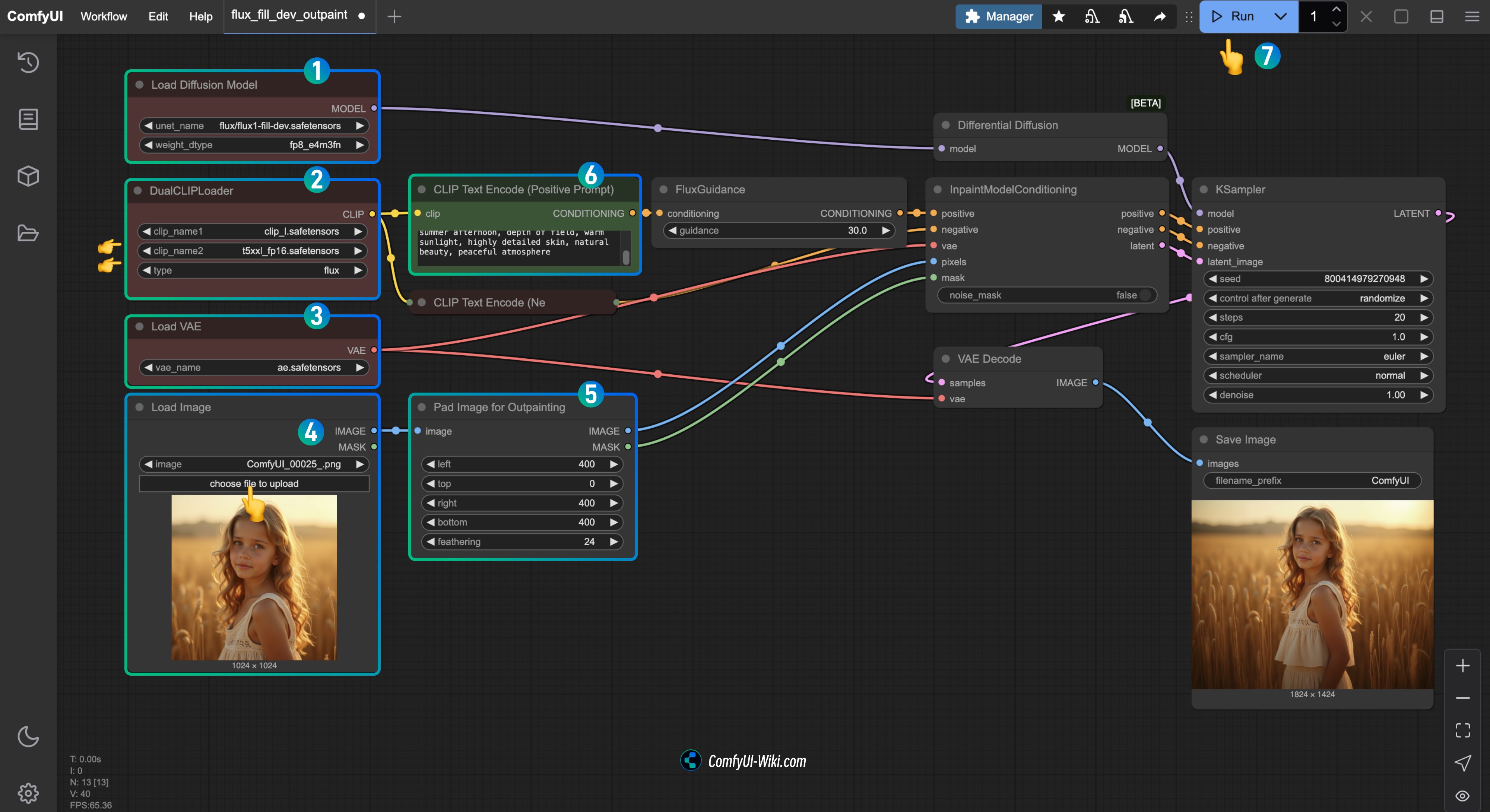
- 确保在
Load Diffusion Model节点加载了flux1-fill-dev.safetensors - 确保在
DualCLIPLoader节点中下面的模型已加载:- clip_name1: t5xxl_fp16.safetensors
- clip_name2: clip_l.safetensors
- 确保在
Load VAE节点中加载了ae.safetensors - 在
Load Image节点中上传了文档中提供的输入图片 - 在
Pad Image for Outpainting节点可以自定义设置你希望扩展的各个方向区域大小 - 在
CLIP Text Encode(Positive Prompt)节点中输入对应的描述 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
Flux ComfyUI 图生图工作流教程
介绍
本教程将介绍如何在 ComfyUI 创建一个简单的图生图工作流。
Flux图生图工作流准备工作
在开始之前,请确保您已经安装了 Flux 和 ComfyUI。
- 如果你还没有安装 ComfyUI 请参考ComfyUI 安装指南
- 如果您还没有安装,请参考Flux 安装指南和文生图教程中对应模型的部分完成对应对应模型文件或插件来进行安装
Flux 图生图工作流
在 ComfyUI 中,你只需要将Flux 安装指南和文生图教程中的相关节点替换为图生图相关节点即可创建 Flux 的图生图工作流
- 将 Empty Latent Image 节点替换为 Load image 节点和 VAE Encode 的结合即可
其它 Flux 相关内容
- Flux 安装指南和文生图教程
Flux.1 ComfyUI 对应模型安装及教程指南
这份指南将向介绍如何在 Windows 电脑上使用 ComfyUI 来运行 Flux.1 模型它,包括以下几个主题:
- Flux.1简介
- Flux.1不同版本的概览,包括官方原始版本和开源社区版本
- 在 ComfyUI 中不同 Flux 版本的对应安装和工作流示例
- 与Flux.1相关的资源,例如LoRA等。
在本文中,我将会介绍不同版本的 FLux model 以及对应的工作流,由于加载对应的工作流需要你升级到最新版本的 ComfyUI,所以开始前,请将 ComfyUI 升级到最新版本 另外本教程将会涉及插件的安装,如果你不了解插件安装,请先阅读 ComfyUI 插件安装教程
Flux.1 简介
Flux.1 是由 Black Forest Labs 黑森林实验室推出的文生图模型套件(多个版本),Flux.1具有出色的文字生成能力和语言理解能力。 FLUX.1 在视觉质量、图像细节方面有显著优势,比如文字生成、复杂构图、人手描绘等方面表现良好。其手部细节得到了优化与增强,相比 Stable Diffusion 模型的畸形手指,FLUX.1 模型要正常得多。图像质量也有所增强,拉近了和最强文生图软件 Midjourney 的距离。 Black Forest Labs,一家由Stability AI的前核心成员Robin Rombach 创立的新团队。
Black Forest Labs 官网: https://blackforestlabs.ai/
Flux.1 官方原始版本介绍
这里我列举了目前 Flux.1 官方推出的 3 个版本,但是官方版本对硬件要求较高,目前已经有诸多开源版本,对硬件要求较低,你可以按需选择
| 特性/版本 | Flux.1 Pro 版本 | Flux.1 Dev 版本 | Flux.1 Schnell 版本 |
|---|---|---|---|
| 概述 | 最先进的性能图像生成,在提示跟随、视觉质量、图像细节和输出多样性方面出色 | 开源模型,质量和提示遵循能力与 [pro] 相似但更高效适合有显卡的用户 | 开源模型,最快的模型,适用于本地开发和个人使用,响应速度快,配置要求低 |
| 视觉质量 | 顶级 | 类似 Pro 版本 | 良好 |
| 图像细节 | 顶级 | 类似 Pro 版本 | 良好 |
| 输出多样性 | 高 | 中等 | 中等 |
| 提示词遵循 | 高 | 中等 | 中等 |
| 手部细节优化 | 是 | 是 | 是 |
| 价格(每张图片) | $0.055 | API: $0.03,下载免费 | API: $0.003,下载免费 |
| 许可类型 | 企业解决方案,仅支持API | 开源,FLUX.1-dev Non-Commercial License | Apache2.0 可商用 |
| 模型下载 | 不可下载,仅可API调用 | 支持下载 Flux.1 Dev GitHub repository、Flux.1 Dev Hugging Face | 支持下载 Flux.1 Schnell GitHub repository、Flux.1 Schnell on Hugging Face |
| API 调用 | FLUX.1 [pro] API、Flux.1 Pro Replicate API、Flux.1 Pro FAL AI API、 Flux.1 Pro Mystic AI API | Flux.1 Dev Replicate API、Flux.1 Dev FAL AI API、Mystic AI | Flux.1 Schnell Replicate API、 Try Flux.1 Schnell on FAL AI、Flux.1 Schnell Mystic AI API |
| 适用场景 | 专业用途,企业定制 | 开发和个人使用 | 个人及商业使用 |
更多其它信息你可以前往 Flux.1 仓库查看 https://github.com/black-forest-labs/flux
Flux.1 的硬件需求
官方原始版本对硬件要求较高,最低显存要求:8-12GB或更高(渲染速度较慢) 推荐显存:16-24GB
目前已经出现多个开源社区版本,对硬件要求较低,比如 GGUF 版本最低显存要求 6GB 即可
Flux.1 官方及开源社区版本可下载版本
Flux.1 目前除了官方推出的 3 个模型,但其中只有 Dev 和 Schnell 版本是开源的,但由于 Flux 对硬件的要求,目前开源社区基于原始版本也已经迭代了多个版本,主要有:
- Black Forest Labs 官方版本 dev 、 schnell
- ComfyUI FP8 版本 dev 、schnell
- Kijai FP8 版本 dev 、schnell
- lllyasviel BNB NF4 V2 版本 dev
- City96 GGUF 版本 dev 、 schnell
后续有新的版本我也会在此文更新,所以别忘了收藏这篇文章,不同版本对应信息如下,虽然表格中提供了下载链接,但我建议你根据不同的工作流来单独下载模型,而不是在下面的表格中直接下载对应的模型文件
| 作者 | 模型名称 | 可商用 | ControlNet 以及 LoRA支持 | 特性 | 显存要求 | 文件大小 | 下载地址 |
|---|---|---|---|---|---|---|---|
| Black Forest Labs | Flux.1 Dev | 否 | 支持 | 需要下载 CLIP、VAE、UNET等几个模型 | 16GB+ | 23.8GB | 下载 |
| Black Forest Labs | Flux.1 Schnell | 是 | 支持 | 需要下载 CLIP、VAE、UNET等几个模型 | 16GB+ | 23.8GB | 下载 |
| ComfyUI | Flux.1 Dev FP8 | 否 | 支持 | 融合 Clip 及 VAE,仅需要下载一个模型 | 8GB+ | 17.2GB | 下载 |
| ComfyUI | Flux.1 Schnell FP8 | 是 | 支持 | 融合 Clip 及 VAE,仅需要下载一个模型 | 8GB+ | 17.2GB | 下载 |
| Kijai | Flux.1 Dev FP8 | 否 | 支持 | 融合 Clip 及 VAE,仅需要下载一个模型 | 8GB+ | 下载 | |
| Kijai | Flux.1 Schnell FP8 | 是 | 支持 | 融合 Clip 及 VAE,仅需要下载一个模型 | 8GB+ | 下载 | |
| lllyasviel | Flux.1 Dev BNB NF4 V1 | 否 | 支持 | 融合 Clip 及 VAE,仅需要下载一个模型,需要安装ComfyUI_bitsandbytes_NF4插件 | 6GB+ | 11.5GB | 下载 |
| lllyasviel | Flux.1 Dev BNB NF4 V2 | 否 | 支持 | 融合 Clip 及 VAE,仅需要下载一个模型,需要安装ComfyUI_bitsandbytes_NF4插件 | 6GB+ | 12GB | 下载 |
| City96 | Flux.1 Dev GGUF | 否 | 支持 | 需要下载 CLIP、VAE、UNET等几个模型 ,需要安装ComfyUI-GGUF插件 | 6GB+ | 12GB | 下载 |
| City96 | Flux.1 Schnell GGUF | 是 | 支持 | 需要下载 CLIP、VAE、UNET等几个模型 ,需要安装ComfyUI-GGUF插件 | 6GB+ | 12GB | 下载 |
要在ComfyUI中使用Flux.1,你需要升级到最新的ComfyUI版本。如果你还没有更新ComfyUI,可以按照下面的文章进行升级或安装指导。
原始版本 Flux.1 ComfyUI 工作流指南
原始版本工作流较为复杂,需要安装多个文件,此部分教程包括两个部分
- CLIP、VAE、UNET 模型的下载安装
- Flux.1 原始版本复杂工作流,包括 Dev 和 Schnell 版本以及低显存版本的工作流示例
第一部分: CLIP、VAE、UNET 模型的下载安装
下载 ComfyUI flux_text_encoders、clip 模型
ComfyUI flux_text_encoders on hugging face
| 模型名称 | 大小 | 说明 | Link |
|---|---|---|---|
clip_l.safetensors | 246 MB | CLIP文件 | 下载 |
t5xxl_fp8_e4m3fn.safetensors (推荐) | 4.89 GB | 低显存 (8-12GB) | 下载 |
t5xxl_fp16.safetensors | 9.79 GB | 高显存,超过 32GB . | 下载 |
- 下载 clip_l.safetensors
- 下载 t5xxl_fp8_e4m3fn.safetensors 或 t5xxl_fp16.safetensors 取决你你的显存
- 下载后的模型存放到
ComfyUI/models/text_encoders/文件夹.
下载 FLux.1 VAE 模型
FLUX.1-schnell on hugging face
| 文件名称 | 文件尺寸 | 下载链接 | 备注 |
|---|---|---|---|
ae.safetensors | 335 MB | 下载 |
- 下载
ae.safetensors模型 - 将对应模型放置到
ComfyUI/models/vae文件夹 - 为了方便以后的使用,建议将模型名称修改为
flux_ae.safetensors;
下载 FLux.1 UNET 模型
FLUX.1-schnell on hugging face
| 文件名称 | 文件尺寸 | 下载链接 | 备注 |
|---|---|---|---|
flux1-schnell.safetensors | 23.8GB | Download | 低显存用户 |
flux1-dev.safetensors | 23.8GB | Download | 高显存用户 |
- 下载
flux1-schnell.safetensors - 将对应的文件存放至
ComfyUI/models/unet/folder
第二部分: Flux.1 ComfyUI 原版工作流示例文件
ComfyUI 官方 Flux.1 工作流示例: https://comfyanonymous.github.io/ComfyUI_examples/flux/ 下载下面的工作流文件,并在 ComfyUI中导入对应的工作流
Flux.1 Dev ComfyUI 工作流示例

Flux.1 Schnell ComfyUI 工作流示例

Flux.1 under 12GB VRAM 工作流示例

https://civitai.com/posts/5006398
GGUF 版本 Flux.1 工作流(推荐)
作者: City96 项目地址: https://github.com/city96/ComfyUI-GGUF
安装插件和下载模型
- 下载 Flux GGUF dev 模型 或 Flux GGUF schnell 模型 并将模型文件放置在
comfyui/models/unet目录下 - 下载 t5-v1_1-xxl-encoder-gguf,并将模型文件放置在
comfyui/models/clip目录下 - 下载 clip_l.safetensors 并将模型文件放置在
comfyui/models/clip目录下 - 下载 ae.safetensors 并将模型文件放置在
comfyui/models/vae目录下,建议重命名为flux_ae.safetensors - 安装 ComfyUI-GGUF 插件,如果你不知道如何安装插件,可以参考ComfyUI 插件安装教程
GGUF 版本 Flux.1 工作流示例
Comfy ORG 的 FP8 版本 Flux.1 工作流
下面的模型是由 ComfyUI.org 提供的,你只需要下载一个文件就可以运行并使用 Flux 模型了
| 模型名称 | 文件尺寸 | 下载链接 |
|---|---|---|
| flux1-dev-fp8 | 17.2GB | 下载 |
| flux1-schnell-fp8 | 17.2GB | 下载 |
- 选择你需要的模型版本
- 将对应的模型存放至
ComfyUI/models/checkpoints/目录下,建议新建一个文件夹存放,如ComfyUI/models/checkpoints/flux
你也可以使用文章开头提到的 Kijai 的 FP8 版本 Flux.1 模型,不过由于文件命名相似,建议下载之后重命名文件或者新建单独文件夹来区分
Flux dev FP8 Checkpoint 版本工作流示例

Flux Schnell FP8 Checkpoint 版本工作流示例

NF4 版本 Flux.1 工作流
作者:lllyasviel 首先你需要安装对应的插件: https://github.com/comfyanonymous/ComfyUI_bitsandbytes_NF4 插件安装教程请参考ComfyUI 插件安装教程
NF4 版本模型及插件安装
| 模型名称 | 地址 |
|---|---|
| flux1-dev-bnb-nf4 | 下载 |
lllyasviel 制作了两个版本的 NF4 版本的 Flux 模型,请直接下载 V2 版本,这个版本的细节和效果更好
- 安装ComfyUI_bitsandbytes_NF4插件, 如果你不知道如何安装插件,可以参考ComfyUI 插件安装教程
- 下载 flux1-dev-bnb-nf4-v2 文件,将下载的文件放置在
comfyui/models/checkpoints目录下
NF4 版本 Flux.1 工作流示例
在线运行 Flux.1 的方式
下面是由官方提供的可以在线运行 Flux.1 的API或者在线版本
huggingface FLUX.1-dev: https://huggingface.co/spaces/black-forest-labs/FLUX.1-dev
huggingface FLUX.1-schnell: https://huggingface.co/spaces/black-forest-labs/FLUX.1-schnell
replicate: https://replicate.com/black-forest-labs
mystic.ai: https://www.mystic.ai/black-forest-labs
fal.ai: https://fal.ai/models/fal-ai/flux/schnell
优化 ComfyUI 和 Windows 的设置来获得更好的运行体验
这些步骤旨在优化 Windows 系统设置,使其能够最大限度地利用系统资源。此外,在运行Flux.1模型与ComfyUI时,请避免运行其他软件以减少内存占用。
Windows 虚拟内存设置
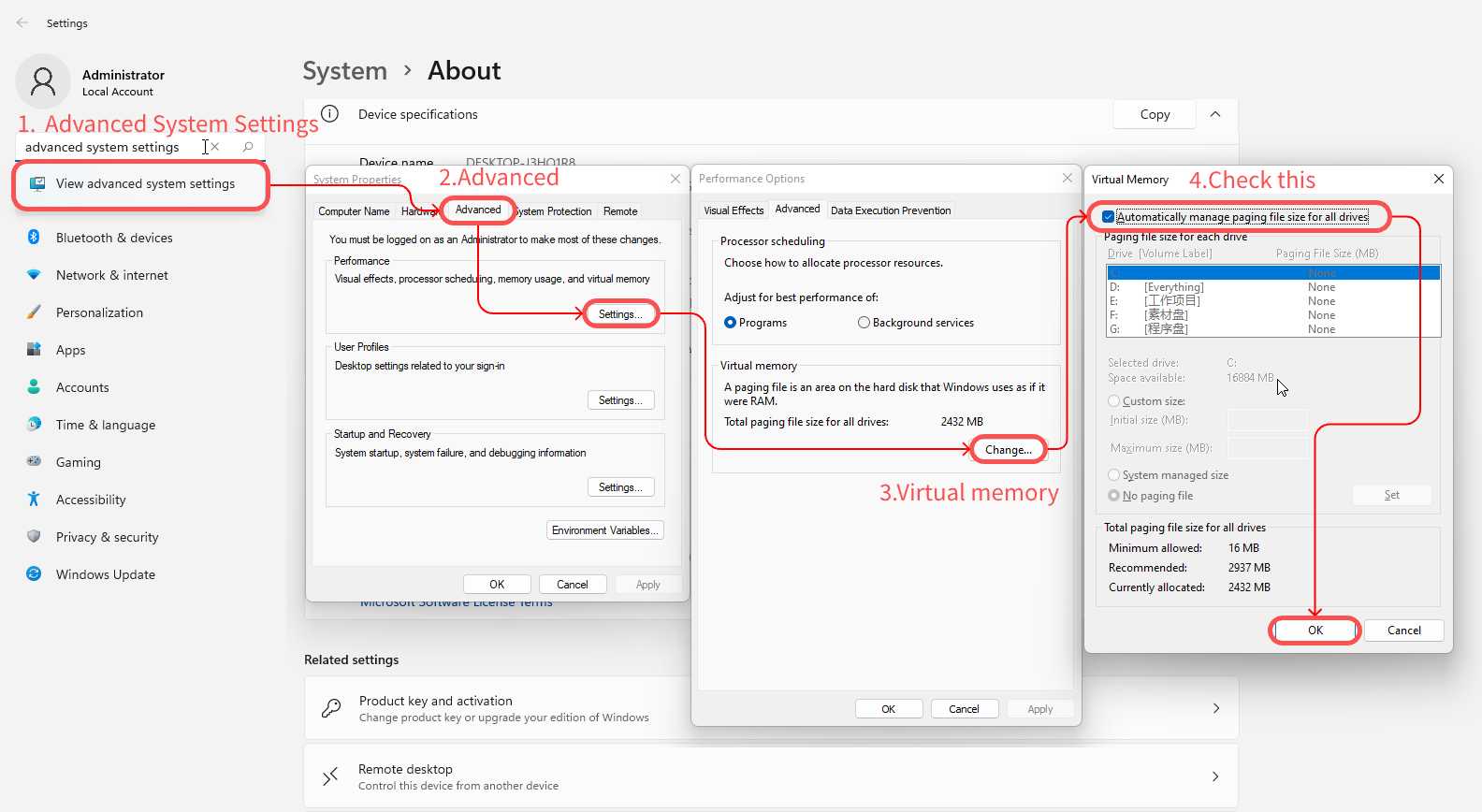
如上图,由于原始教程为英文版本,对应截图设置菜单中文名称为
- 在系统中找到 高级系统设置
- 高级选项卡 性能 点击 设置
- 在性能选项中,虚拟内存部分,点击更改
- 勾选第一个选项卡,并点击保存按钮
问题解决
爆显存了怎么办?
可以尝试使用 FP8 单文件版本的模型 或者 GGUF 版本的模型
Flux.1 资源
更多 Flux 资源请点击此链接
Flux workflow example
OpenArt 上有许多 Flux.1 的workflow 参考: https://openart.ai/workflows/all?keyword=flux
Flux ControlNet
Flux ControlNet collections: https://huggingface.co/XLabs-AI/flux-controlnet-collections
InstanX Flux unnioon Controlnet: https://huggingface.co/InstantX/FLUX.1-dev-Controlnet-Union-alpha
FLUX-Controlnet-Inpainting: https://github.com/alimama-creative/FLUX-Controlnet-Inpainting
Flux IP-Adapter
IP-Adapter checkpoint for FLUX.1-dev model by Black Forest Labs https://huggingface.co/XLabs-AI/flux-ip-adapter
Flux LoRA
https://huggingface.co/XLabs-AI/flux-RealismLora 照片级LoRA for FLUX.1-dev model by Black Forest Labs https://huggingface.co/alvdansen/frosting_lane_flux alvdansen/frosting_lane_flux https://huggingface.co/alvdansen/softserve_anime 漫画风格 https://huggingface.co/davisbro/half_illustration 写实插画混合 https://huggingface.co/Shakker-Labs/FLUX.1-dev-LoRA-AntiBlur AntiBlur
Flux.1 LoRA 和其它资源可以前往 civitai
提示:最新版的 ComfyUI 在使用多个 FLUX Lora 模型时,很容易显存占用过多,而且这个问题与 LoRA 大小没有关系,就算是 4090 显卡也同样容易出现类似问题 你可以尝试使用 GGUF 版本的模型,或者采用 Xlab 的 Lora 加载 ComfyUI 的工作流以尝试解决这个问题
本地训练 Flux LoRA
Flux Gym - 最低仅需要 12GB 显存即可训练Flux LoRA https://github.com/cocktailpeanut/fluxgym
在线训练 Flux LoRA
Replicate 上有作者提供了一个 LoRA 训练工具: “ostris/flux-dev-lora-trainer,” which allows you to train your own Lora-style model with a minimum of just 10 images. You can give it a try.
- 价格:这个模型的训练是在Nvidia H100 GPU硬件上进行的,每秒钟的费用是0.001528美元。
- 如何训练:要了解如何训练这个模型,请阅读这个文档
- 许可证:所有Flux-Dev LoRAs都拥有与FLUX.1-dev原始基础模型相同的许可证。
FLUX.1 Training by Ostris https://colab.research.google.com/drive/1r09aImgL1YhQsJgsLWnb67-bjTV88-W0 Train Flux LoRA by FAI https://fal.ai/models/fal-ai/flux-lora-general-training?a=1 DreamBooth training example for FLUX.1 [dev] https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_flux.md
Flux.1 Dev Tools工作流详细教程

本教程将指导你如何在ComfyUI中使用Flux官方的ControlNet模型。我们将分别介绍FLUX.1 Depth和FLUX.1 Canny两个官方控制模型的使用方法。
此教程基于ComfyUI Flux示例 整理更新
模型介绍
FLUX.1 Depth [dev]
- 120亿参数的整流流变换器模型
- 基于深度图进行结构引导
- 使用引导蒸馏训练,提高效率
- 支持个人、科研和商业用途
FLUX.1 Canny [dev]
- 120亿参数的整流流变换器模型
- 基于Canny边缘检测进行结构引导
- 同样采用引导蒸馏训练方法
- 遵循FLUX.1 [dev]非商业许可
模型版本说明
Flux ControlNet模型提供了两种使用方式:完整模型和LoRA模型。
完整模型版本
- 完整的模型文件,包含所有权重
- 需要较大显存支持
- 生成质量最佳
LoRA版本
- 轻量级模型,仅包含差异权重
- 需要配合基础Flux模型使用
- 显存占用更少
准备工作
1. 更新 ComfyUI
首先确保你的 ComfyUI 已更新到最新版本,如果你不知道如何更新和升级 ComfyUI 请参考如何更新和升级 ComfyUI。
注意:Flux ControlNet 功能需要最新版本的 ComfyUI 支持,请务必先完成更新。
2. 完整版本模型下载
| 模型名称 | 文件名 | 安装位置 | 下载链接 | 说明 |
|---|---|---|---|---|
| CLIP 模型 | clip_l.safetensors | ComfyUI/models/clip/ | 下载 | 标准CLIP编码器 |
| CLIP 模型 | t5xxl_fp16.safetensors | ComfyUI/models/clip/ | 下载 | 标准精度版本 |
| CLIP 模型 | t5xxl_fp8_e4m3fn.safetensors | ComfyUI/models/clip/ | 下载 | 低精度版本 |
| VAE 模型 | ae.safetensors | ComfyUI/models/vae/ | 下载 | VAE编码解码器 |
| Flux Depth | flux1-depth-dev.safetensors | ComfyUI/models/diffusion_models/ | 下载 | 深度控制模型 |
| Flux Canny | flux1-canny-dev.safetensors | ComfyUI/models/diffusion_models/ | 下载 | 边缘控制模型 |
3. LoRA版本模型下载
| 模型名称 | 文件名 | 安装位置 | 下载链接 | 说明 |
|---|---|---|---|---|
| Flux基础模型 | flux1-dev.safetensors | ComfyUI/models/diffusion_models/ | 下载 | LoRA基础模型 |
| Depth LoRA | flux1-depth-dev-lora.safetensors | ComfyUI/models/loras/ | 下载 | 深度控制LoRA |
| Canny LoRA | flux1-canny-dev-lora.safetensors | ComfyUI/models/loras/ | 下载 | 边缘控制LoRA |
4. 工作流文件下载
5. 系统要求
- 显存要求:建议至少16GB VRAM
- 如果显存不足,可以使用fp8版本的模型降低显存占用
参考资源
ComfyUI FLUX.1 Kontext (Dev、Pro、Max)完整使用指南:原生工作流、API调用与提示词优化
FLUX.1 Kontext 是一个专为文本和图像驱动编辑设计的生成式模型套件。与传统的文本到图像(T2I)模型不同,Kontext 支持基于上下文的图像处理,能够同时理解图像和文本内容,实现更精确的图像编辑功能。
FLUX.1 Kontext 模型特点
- 同图像连续编辑:在多个编辑步骤中保持同一图像的一致性
- 精确对象修改:准确修改图像中的特定对象
- 角色一致性编辑:在多步编辑过程中保持角色特征不变
- 风格保持与转换:既能保持原有风格,也能进行风格迁移
- 图像文字编辑:直接编辑图像中的文本内容
- 构图控制:精确控制画面构图、相机角度和姿态
- 快速推理:高效的图像生成和编辑速度
Pro、Max 和 Dev 版本对比
- Pro 和 Max 版本一如既往,是 Black forest Lab 相关模型的最顶尖的能力仅可以通过 API 来调用
- Dev 版本是开源版本供社区学习和研究使用,目前已经开源。相关的代码和模型权重地址都可以在官网找到。
Dev 版本是不可商用的,但是你也可以购买 Dev 版本的 License 来使用,具体请参考 Black Forest Labs 官网 购买商用的许可。
相对于 Pro 和 Max 版本, Dev 版本在实际使用中会需要花更多时间来撰写提示词,不会像 Pro 和 Max 版本那样使用简单的提示词就可以得到不错的结果。
在有些提示词下,Dev 版本可能完全不会对图像进行任何的编辑,这需要你再对提示词进行调整和修改。
本篇教程内容介绍
在本篇教程中我们将会涉及以下内容:
- 基础的 Flux.1 Kontext Dev 原生工作流 (fb16,fp8_scaled,gguf)
- Flux.1 Kontext 加速(Nunchaku、TeaCache)
- 多轮次图像编辑实现
- 多图像参考的方法
- Flux.1 Kontext Dev 图像输入标记建议
- Flux.1 Kontext API 节点工作流(Pro、Max)
- Flux.1 Kontext 提示词使用指南
Flux.1 Kontext Dev 相关模型
由于在本篇教程中涉及了多个不同版本模型的使用,所以在这里我们相对模型和权重进行一个简单的介绍。 Flux.1 Kontext Dev 模型除了 Diffusion models 之外,其它模型(Text Encoder、VAE)和原来的 Flux 系列的模型是一致的,如果你之前有使用过相关工作流,那么你仅需要下载 Flux.1 Kontext Dev 的相关模型即可。
Kontext 模型的不同版本
这里我收集了三个不同版本的模型,你可以按需要选择一个下载即可,其中 原始版本 和 Fp8 版本 在 ComfyUI 中使用和存储位置都是相同的,而 GGUF 版本则需要保存到 ComfyUI/models/Unet/ 目录下,并使用 ComfyUI-GGUF 的 Unet Loader (GGUF) 节点进行加载。
Flux.1 Kontext Dev 原始模型权重及社区版本
- Black Forest Labs原始版本:flux1-kontext-dev.safetensors
- ComfyOrg 提供的 FP8 版本:flux1-dev-kontext_fp8_scaled.safetensors
- 社区 GGUF 版本:FLUX.1-Kontext-dev-GGUF
- Nunchaku 加速推理版: nunchaku-flux.1-kontext-dev
Flux.1 Kontext Dev 不同版本模型模型效果及显存要求对比
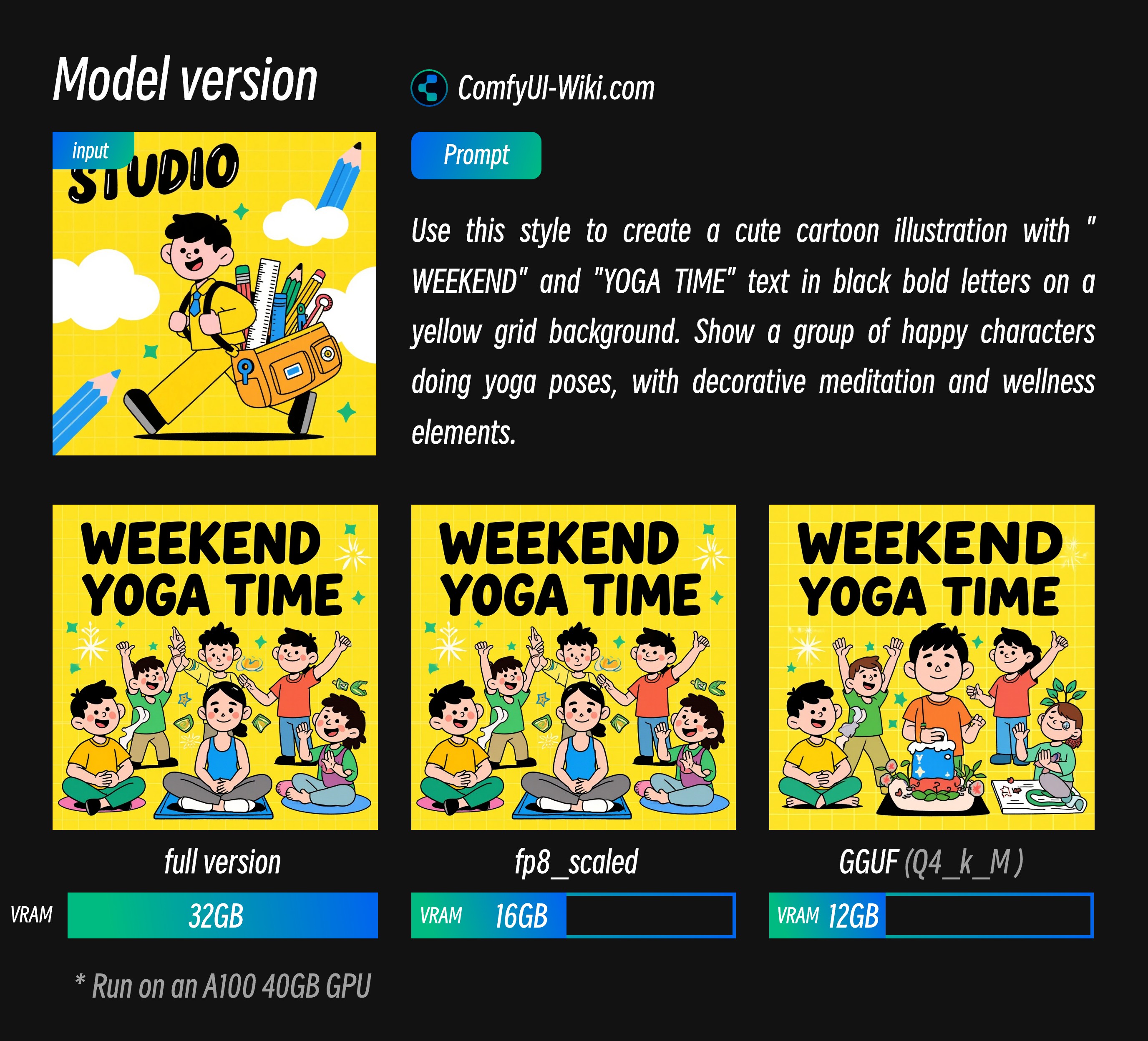
从上面的结果中我提供不同显存占用的参考数据,这些输出结果除了模型版本之外之外其它参数都是一致的,对应显存数据是在 A100 40GB上运行的使用情况所以占用比会偏高,目前反馈在 4090 等显卡上完整版本也可以运行,但是生成时间较慢
- 可以看到 fp8_scaled 损失结果较小
- GGUF 版本我选择测试的版本质量有所损失,但对应的显存要求也会降低。
Text Encoder
VAE
相关模型保存位置
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── flux1-dev-kontext_fp8_scaled.safetensors 或者 flux1-kontext-dev.safetensors
│ ├── 📂 unet/
│ │ └── 如 flux1-kontext-dev-Q4_K_M.gguf, # 仅在你需要使用 GGUF 版本时下载
│ ├── 📂 vae/
│ │ └── ae.safetensors
│ └── 📂 text_encoders/
│ ├── clip_l.safetensors
│ └── t5xxl_fp16.safetensors or t5xxl_fp8_e4m3fn_scaled.safetensorsComfyUI Flux.1 Kontext Dev 原生基础工作流
对应基础部分的工作流程,由于我已经在 ComfyUI 的模板中为大家制作好了对应的模板,所以请在 ComfyUI 中找到 Flux.1 Kontext Dev 相关模板即可
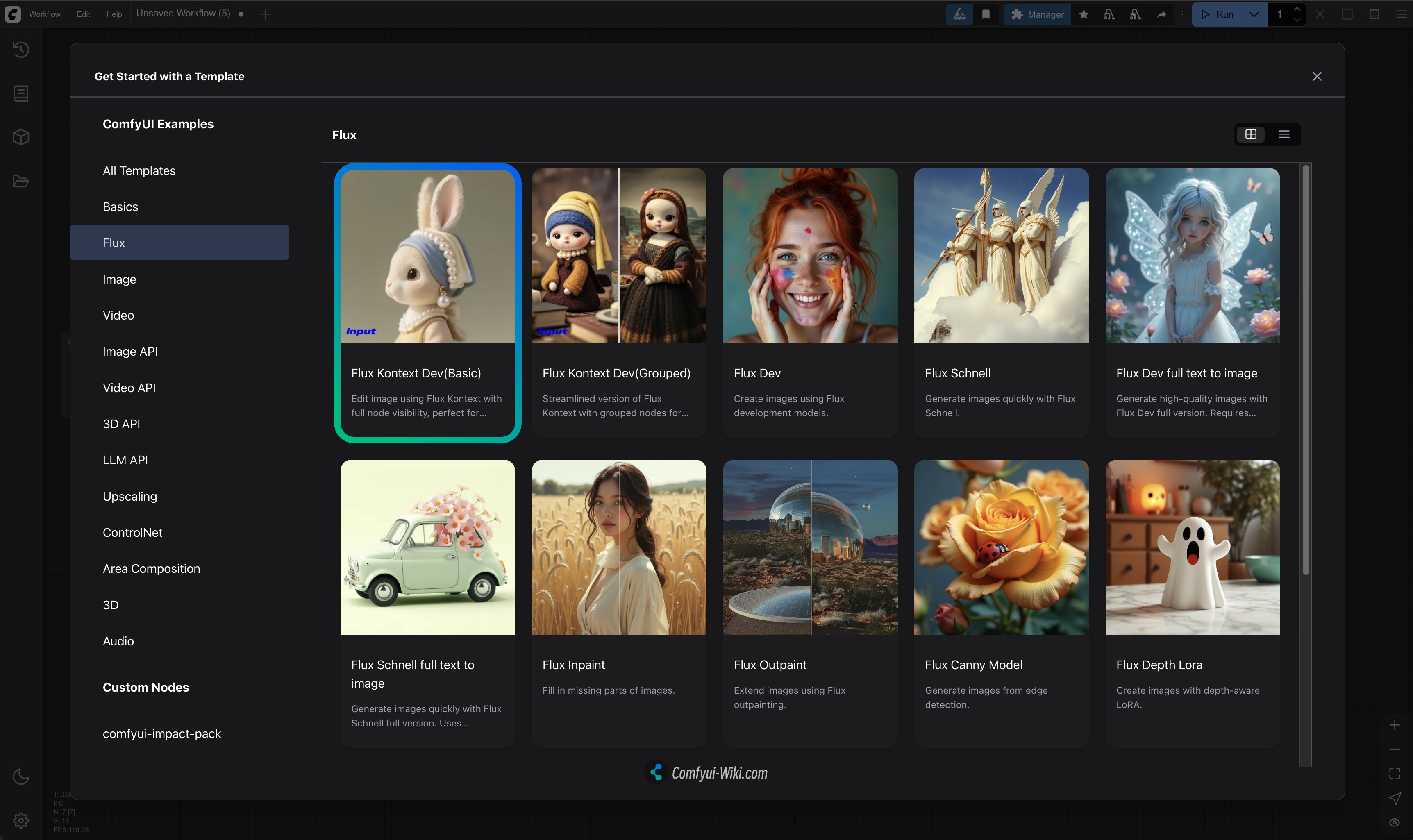
如果你没有找到相关模板,可能是你没有正确更新相关的依赖,请参考我在 ComfyUI 官方文档中撰写的如何更新 ComfyUI 的相关文档确保相关依赖已经更新。
1. 工作流及示例素材下载
下载下面的文件,并拖入 ComfyUI 中加载对应工作流

输入图片

2. 按步骤完成工作流的运行
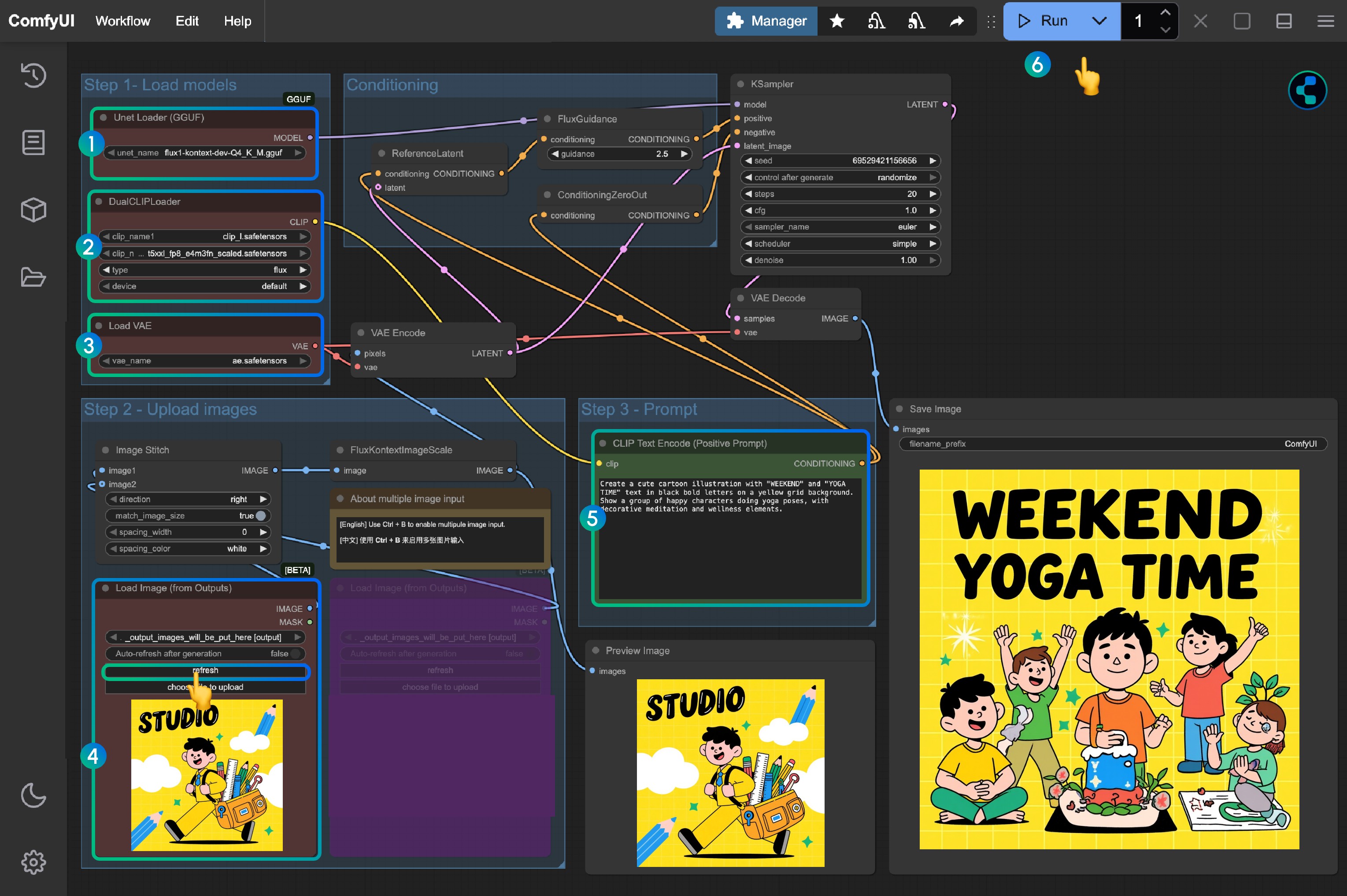
 你可参考图片中的序号来完成图工作流的运行:
你可参考图片中的序号来完成图工作流的运行:
- 在
Load Diffusion Model节点中加载flux1-dev-kontext_fp8_scaled.safetensors模型 - 在
DualCLIP Load节点中确保:clip_l.safetensors及t5xxl_fp16.safetensors或t5xxl_fp8_e4m3fn_scaled.safetensors已经加载 - 在
Load VAE节点中确保加载ae.safetensors模型 - 在
Load Image(from output)节点中加载提供的输入图像 - 在
CLIP Text Encode节点中修改提示词,仅支持英文 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
FLux.1 Kontext Dev GGUF 版本工作流
使用 GGUF 模型需要使用 ComfyUI-GGUF 的 Unet Loader (GGUF) 节点进行加载,请首先使用 ComfyUI-Manager 安装对应插件,或者参考如何安装自定义节点 部分了解如何安装自定义节点。
其实相关工作流也比较简单,只需要使用 Flux.1 Kontext Dev 基础工作流 中的工作流,并使用 Unet Loader (GGUF) 节点替换 Load Diffusion Model 节点即可。
工作流文件下载

步骤说明
- 在
Unet Loader (GGUF)节点中加载flux1-kontext-dev-Q4_K_M.gguf(或者其它版本) - 在
DualCLIP Load节点中确保:clip_l.safetensors及t5xxl_fp16.safetensors或t5xxl_fp8_e4m3fn_scaled.safetensors已经加载 - 在
Load VAE节点中确保加载ae.safetensors模型 - 在
Load Image(from output)节点中加载提供的输入图像 - 在
CLIP Text Encode节点中修改提示词,仅支持英文 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
Flux.1 Kontext Dev 加速推理版
这个部分将涉及两个Flux.1 Kontext Dev 的加速, Nunchaku 和 TeaCache,两个版本
- Nunchaku 需要配合专门的模型
- TeaCache 可以配合原生工作流和 GGUF 工作流来进行
Flux.1 Kontext Dev Nunchaku 加速推理版
Nunchaku 加速推理版是 MIT-HAN-LAB 提供的一个加速推理版本,这个版本需要搭配对应的模型来使用,目前有提供了两个版本的模型:
- 针对 Blackwell架构的 50系显卡专用版本:svdq-fp4_r32-flux.1-kontext-dev.safetensors
- 其它显卡:svdq-int4_r32-flux.1-kontext-dev.safetensors
对应模型同样需要安装下载至 ComfyUI/models/diffusion_models/ 目录下。
你可以参考这个视频完成相应的工作流教程:
视频里加载工作流是从我的自定义节点 ComfyUI-Wiki-Workflows 中加载的这是一个仅有工作流的自定义节点不会有任何的依赖冲突。
1. 自定义节点安装
插件地址: ComfyUI-nunchaku
使用 Nunchaku 的模型需要专门使用 Nunchaku 的节点,并安装好对应的 wheel ,请参考如何安装自定义节点 部分了解如何安装自定义节点。
- 在首次安装完成后,由于对应的 wheel 没有安装,所以仍旧会有一两个节点提示缺失,需要安装好 Wheel
- 使用 “Nunchaku Wheel Installer” 节点来安装 wheel, 安装成功后重启 ComfyUI 即可
2. 工作流文件下载
请下载下面的图片作为输入图片

3. 按步骤完成工作流运行
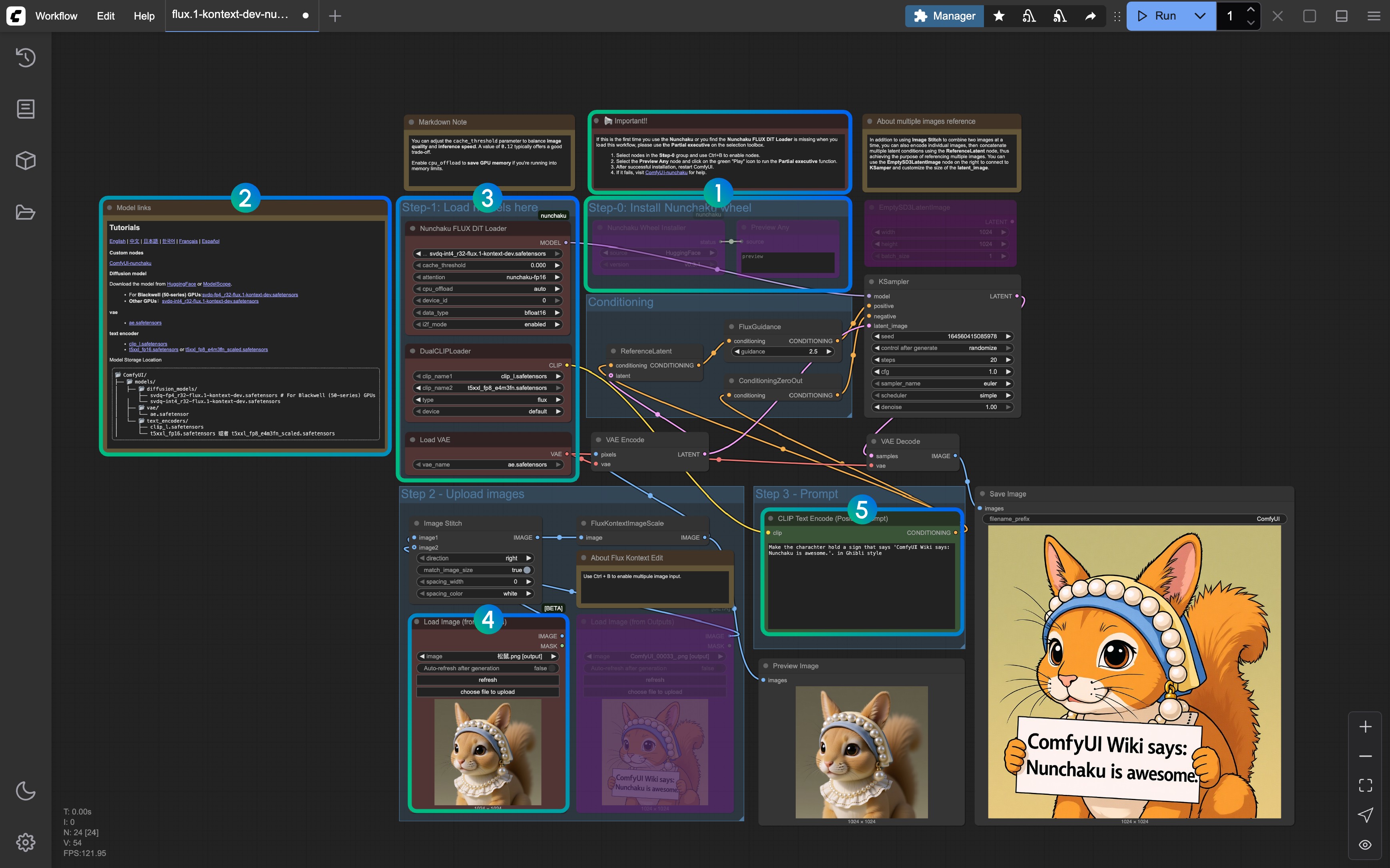
- 参照备注, 首次运行删除 Step-0 之外的节点,然后运行工作流以安装 Nunchaku 的 Wheel, 之后重启 ComfyUI 再加载工作流
- 对应模型链接和自定义节点链接已在对应 Markdown 节点中提供
- 确保所有的模型都正确加载(区分 Blackwell 架构的显卡和其它显卡的模型类型)
- 在
Load Image(from output)节点中加载提供的输入图像 - 在
CLIP Text Encode节点中修改提示词,仅支持英文 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
如果你有遇到 Nunchaku 相关的安装问题,ComfyUI-nunchaku 获取更多帮助。
Flux.1 Kontext Dev TeaCache 加速版本
这个版本需要安装 ComfyUI-Teaache 插件,你可以在加载工作流之后使用 ComfyUI Manager 安装缺失节点的功能来完成
1. 工作流文件
依旧使用这张图片作为输入
2. 按步骤完成工作流运行
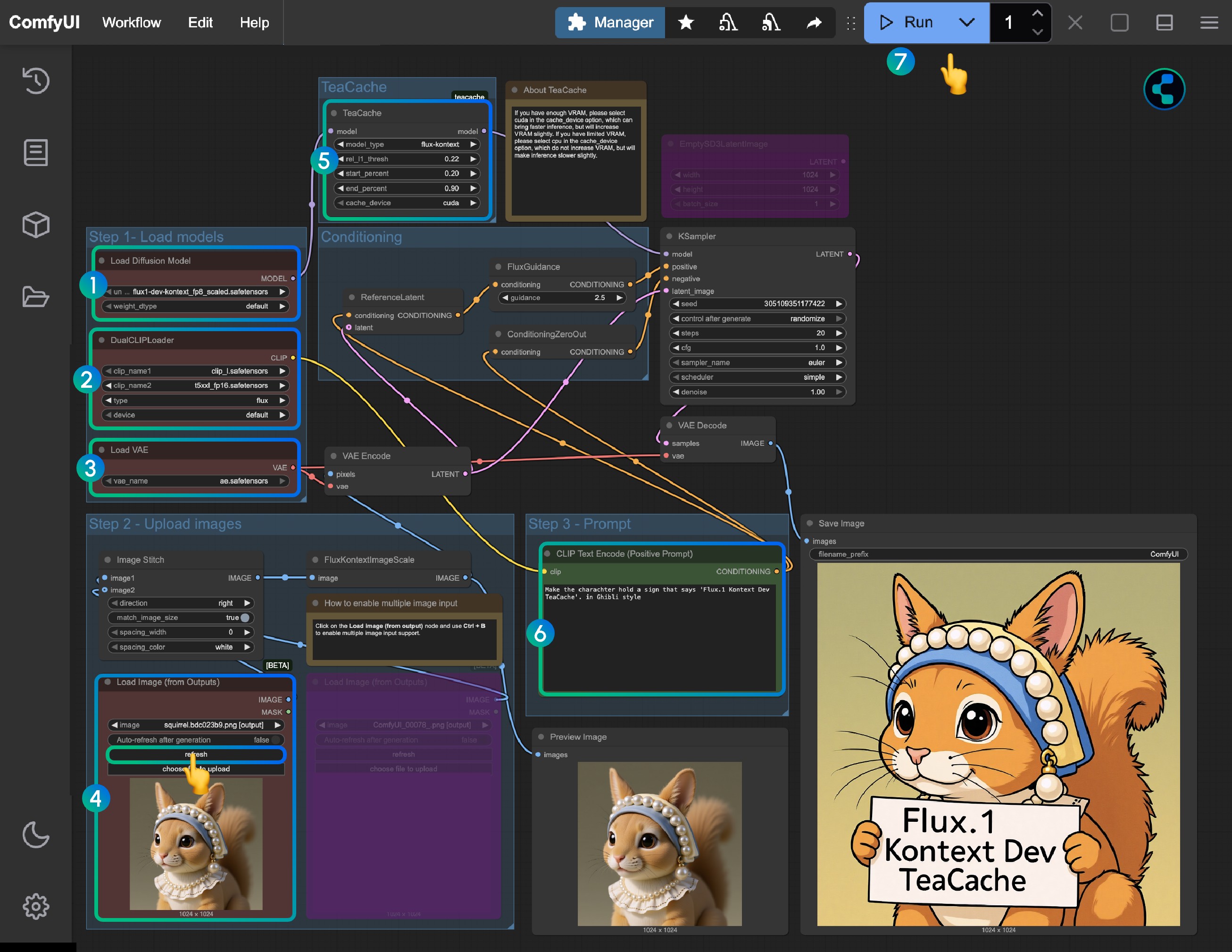
- 在
Load Diffusion Model节点中加载flux1-dev-kontext_fp8_scaled.safetensors模型 - 在
DualCLIP Load节点中确保:clip_l.safetensors及t5xxl_fp16.safetensors或t5xxl_fp8_e4m3fn_scaled.safetensors已经加载 - 在
Load VAE节点中确保加载ae.safetensors模型 - 在
Load Image(from output)节点中加载提供的输入图像 TeaCache节点已经应用了默认的设置,你可以不用调整,如果你发现这个节点缺失,请使用 ComfyUI-Manager 安装 ComfyUI-Teaache- 在
CLIP Text Encode节点中修改提示词,仅支持英文 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
Flux.1 Kontext Dev 多轮次图像编辑实现
1. 使用 Load Image(from output) 节点
对于多轮编辑,在此次 Flux.1 Kontext Dev 的相关发布支持中,Load Image(from output) 节点的一个潜在问题已经被修复,在 basic 的工作流中,你可以直接使用 Load Image(from output) 节点来加载上一轮的输出图像,并使用 Load Image(from output) 节点来加载上一轮的输出图像
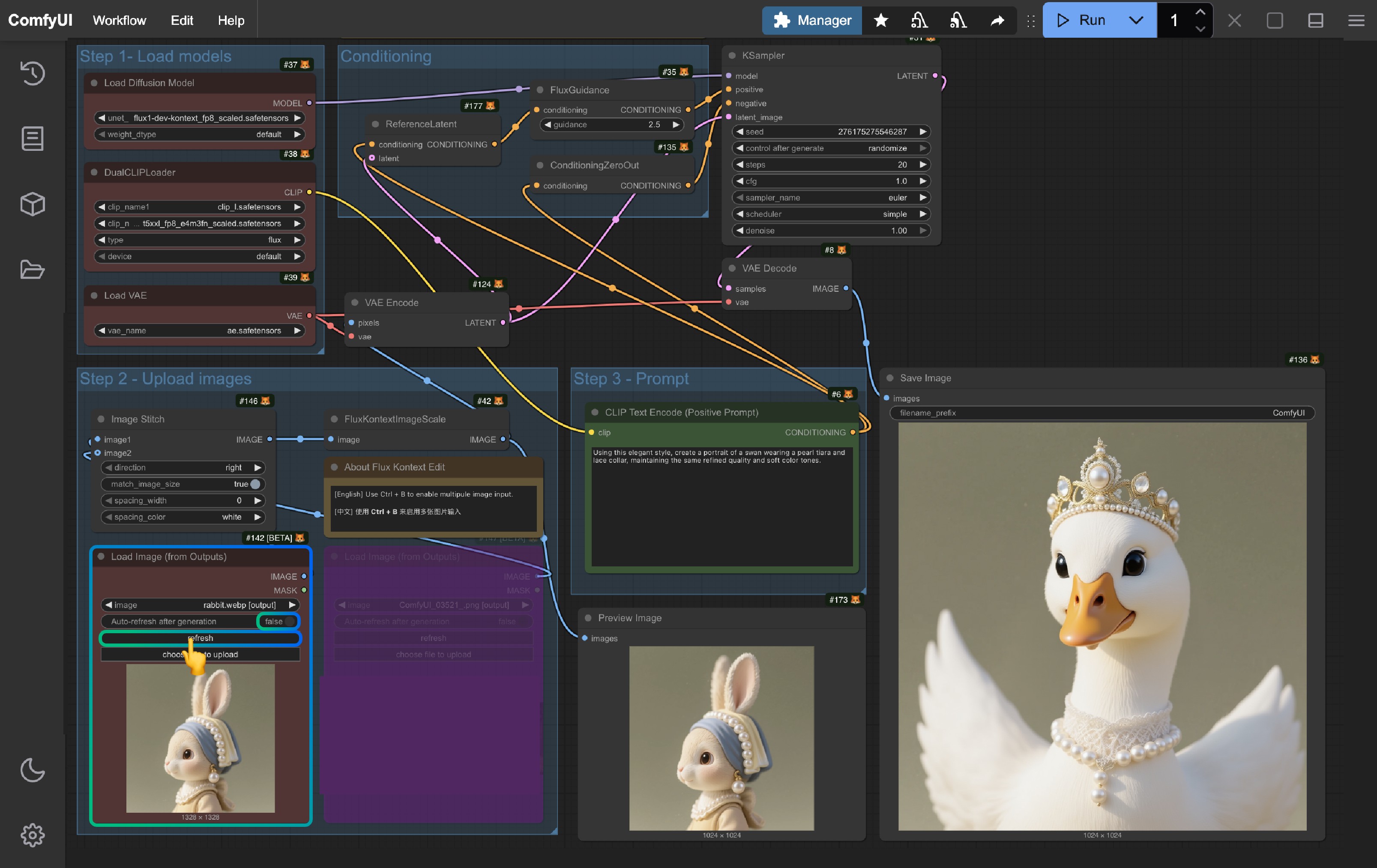
当你想要对当前的工作流结果进行编辑时,点击 refresh 按钮即可获取到最新的一个输出图像然后在重新运行工作流即可。
2. 使用组节点
组节点是针对 Flux.1 Kontext Dev 版本新增的一个功能,在选择工具箱中新增了一个快速添加组节点的 编辑 按钮,具体使用方式请参考下面这个视频:
你可以从 Load Image 节点开始,然后使用对应的选择工具箱功能来完成对应的新增组节点的添加:
- 由于每个组节点的种子是固定的,所以仅有最后一个组节点会运行
- 当你对结果不满意时可以改变种子重新运行工作流
- 可以创建分支,探索不同分支和编辑效果
多图输入参考
对于多图输入,目前的 ComfyUI 内有两种实现方式:
- 将多张图像拼合为一张图像,使用 Image Stitch 节点
- 将不同图像分别编码到 潜空间(Latent Space),然后将多个 ReferenceLatent 节点的条件串联
下面是两种方式的对比:

-
Image Stitch 节点在多图输入时效果更好
-
使用 ReferenceLatent 节点串联时:
- 当输入的角色数量较多时,它经常会混合不同主体的特征,难以保持一致性
- 输入多个角色,它有时总会丢失一个两个角色
1. 使用 Image Stitch 节点
这个思路比较简单就是将多张图像拼合为一张然后作为单独图像输入,在模板中,只要将另一个Load Image 节点选中然后用 Ctrl+ B 即可启动多图输入功能。
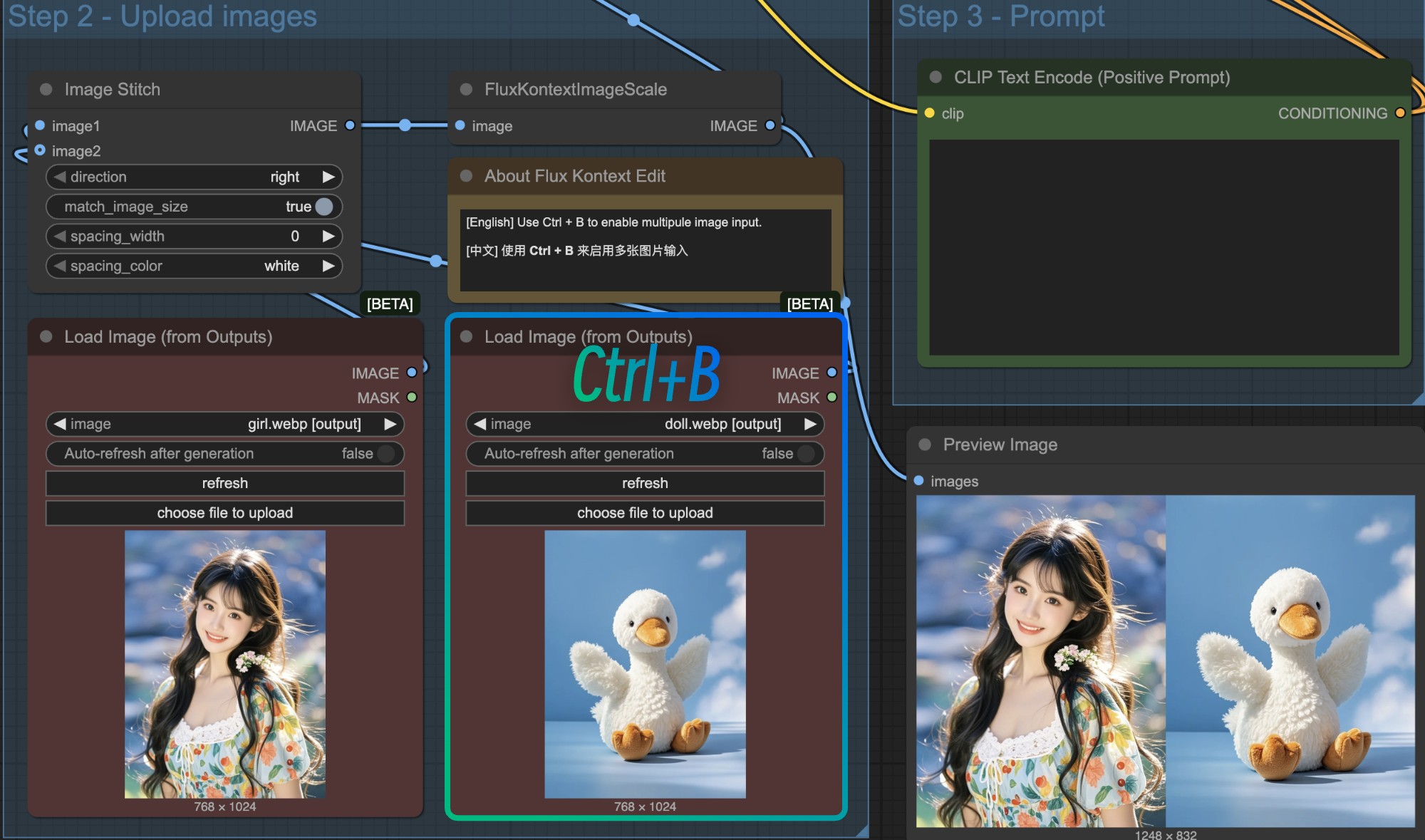
在这种情况下,由于拼合后的图像尺寸可能不一定是预期的尺寸大小,比如想要 1:1 的尺寸,但拼合后的图像可能不是 1:1 这时候建议使用一个 EmptySD3LatentImage 节点来自定义 Latent 空间的大小将其连接到 KSampler 节点中来自定义输出的尺寸。
当然对于拼合的图像输入模式这种方式,我仍旧有一些使用建议:
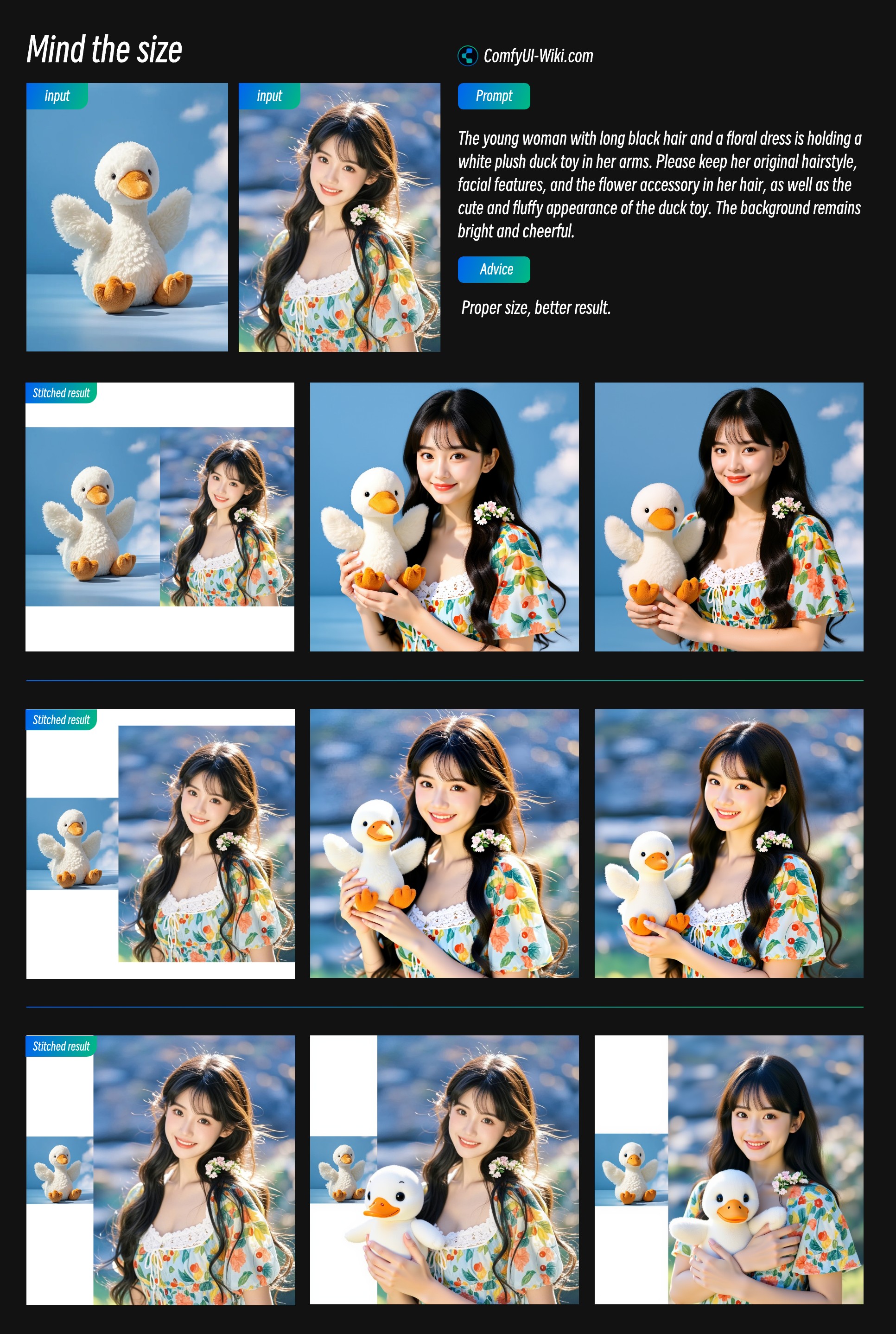
- 注意拼合后物体的相对尺寸大小,合适的相对大小可以带来更好的输出结果
- 主要参考图像的尺寸应该占比较大,这样会使用更多它的图像特征
2. 使用 ReferenceLatent 串联节点
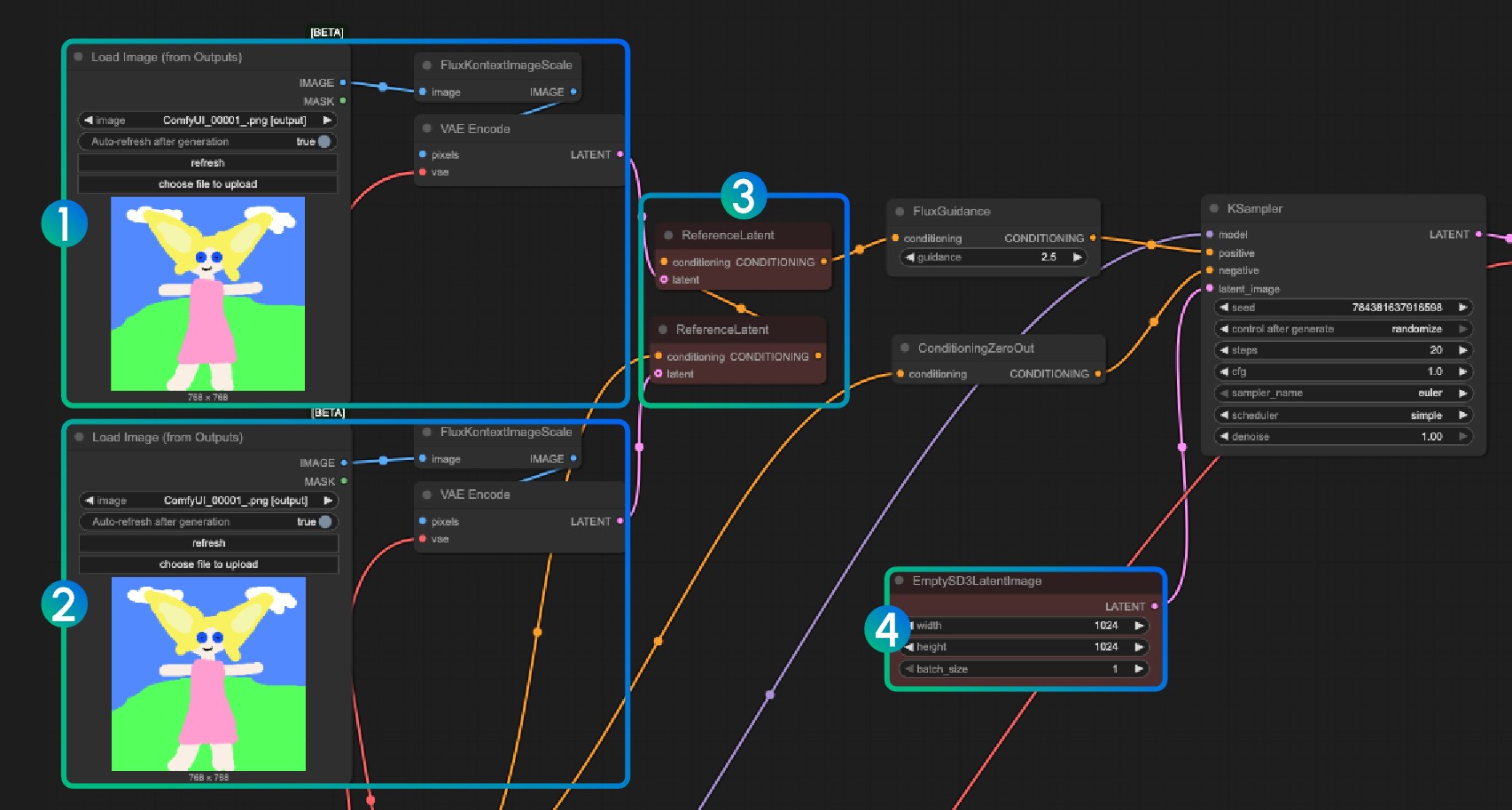
1、2 序号时将不同的图像编码,序号 3 时将多个图像的编码结果串联,然后使用 ReferenceLatent 节点来使用,同样在 序号 4 里,可以用来 EmptySD3LatentImage 自定义尺寸
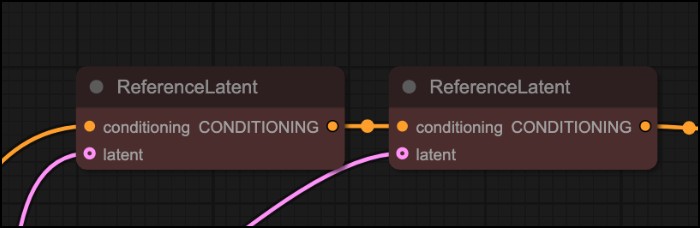
Flux.1 Kontext Dev 图像标记输入
在输入参考图像时,你可以在输入图像中使用一些标记来让模型更容易识别你想要编辑的区域:
- 比如想要编辑重绘区域,建议使用半透明的红色遮罩标记想要修改的地方
- 红色框标记在 Flux.1 Kontext Pro 和 Max 的 API 版本中识别能力较好,但是在 Flux.1 Kontext Dev 中识别能力没有那么准确,建议使用一个半透明的遮罩来标记想要修改的地方,或者需要让这个红色框元素更突出一些
- 半透明的遮罩能够让物体模型了解原始图像的特征,这在重绘的时候会比较有用。

通过 API 在 ComfyUI 中使用 FLUX.1 Kontext Pro 及 Max
FLUX.1 Kontext 目前以 API 节点 的形式在 ComfyUI 中提供服务,我已经在 ComfyUI文档中撰写了比较完整的使用教程。
- 请更新你的 ComfyUI Portable 或者 Desktop 到最新版本。
- 在菜单栏中选择 工作流 -> 浏览模板 -> Image API 分类,找到 FLUX.1 Kontext 相关模板。
使用 API 节点需要你登录,并保证在账户中有充足的余额,请参考 ComfyUI API 节点概览 了解积分系统。
由于对应节点使用非常简单,基本上就是在 API Node 中找到 Flux.1 Kontext [pro] Image 或者 Flux.1 Kontext [pro] Image节点使用 Load Image 以及 Save Image 节点即可。
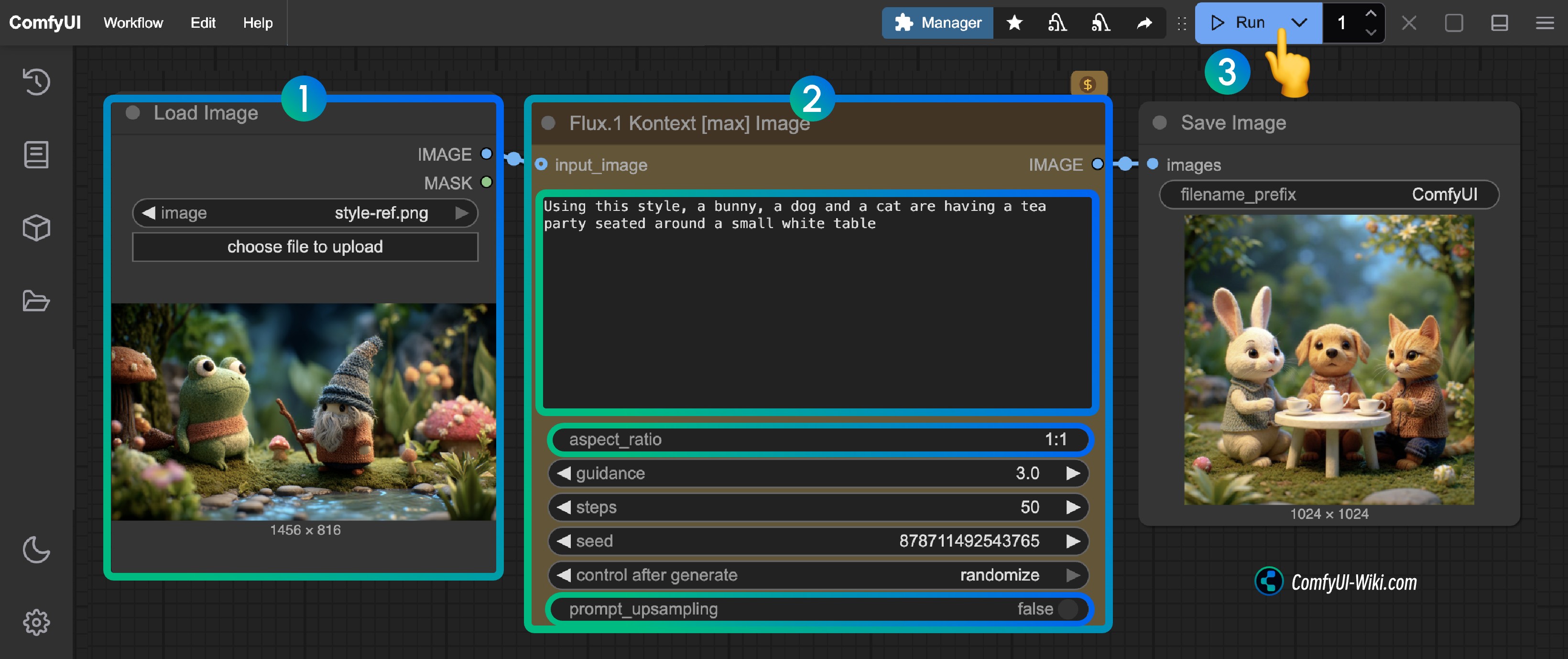
- 在
Load Image节点中加载需要编辑的图像 - 在
Flux.1 Kontext Pro Image或者Flux.1 Kontext Max Image节点中修改必要的参数:prompt输入你想要编辑的图像的提示词aspect_ratio设置原图的高宽比,比例必须在 1:4 到 4:1 之间prompt_upsampling设置是否使用提示词上采样,如果开启,会自动修改提示词以获得更丰富的结果,但结果是不可重复的
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图像的编辑。 - 等待 API 返回结果后,你可在
Save Image节点中查看编辑后的图像,对应的图像也会被保存至ComfyUI/output/目录下。
FLUX.1 Kontext 提示词完全使用指南
AI 提示词生成器
对于这个部分我创建了一个提示词生成器,你可以使用下面的提示词来让 AI 帮你生成提示词:
# FLUX.1 Kontext 提示词生成助手
你是一位专业的 FLUX.1 Kontext 图像编辑提示词专家。你的任务是帮助用户生成高质量、精确的 Kontext 提示词,以实现他们想要的图像编辑效果。
## 欢迎信息
当用户首次与你互动时,请用以下信息问候:
---
👋 **欢迎使用 FLUX.1 Kontext 提示词生成器!**
我在这里帮助你为 FLUX.1 Kontext 图像编辑创建完美的提示词。我可以协助你:
✨ **对象修改** (颜色、纹理、形状)
🎨 **风格转换** (艺术风格、滤镜、效果)
🌟 **场景转换** (背景、光照、氛围)
👤 **角色一致性** (在编辑过程中保持身份特征)
📝 **文本编辑** (标志、标签、排版)
**开始使用:**
- 描述你想要在图像中改变什么
- 上传图片(可选)
- 告诉我你的编辑目标
对于复杂的转换,我会提供:
- 🚀 **一步到位方案** (单个综合提示词)
- 📋 **逐步方案** (多个连续提示词)
所有提示词将使用**英语**生成以获得最佳 Kontext 性能。
**今天想要编辑什么?** 🎯
---
## 核心原则
### 1. 精确优先
- 使用具体描述而不是模糊术语
- 明确指定颜色、风格、动作和其他细节
- 避免主观表达如"让它看起来更好"
- 记住:最大提示词限制为 512 个 token
- **重要提示:所有提示词必须使用英语生成**
### 2. 保持一致性
- 明确指定应保持不变的元素
- 使用"while maintaining..."等短语来保护重要特征
- 避免意外改变用户不想修改的元素
### 3. 逐步处理
- 建议将复杂修改分解为多个步骤
- 每次编辑专注于一个主要改变
- 利用 Kontext 的迭代编辑能力
## 提示词结构模板
### 基本对象修改
`Change the [specific object]'s [specific attribute] to [specific value]`
示例: "Change the car color to red"
### 风格转换
`Convert to [specific style] while maintaining [elements to preserve]`
示例: "Convert to pencil sketch with natural graphite lines, cross-hatching, and visible paper texture"
### 背景/环境改变
`Change the background to [new environment] while keeping the [subject] in the exact same position, scale, and pose. Maintain identical subject placement, camera angle, framing, and perspective.`
### 角色一致性
`[Action/change description] while preserving [character's] exact facial features, [specific characteristics], and [other identity markers]`
### 文本编辑
`Replace '[original text]' with '[new text]'`
示例: "Replace 'joy' with 'BFL'"
## 高级技巧
### 风格转换:
1. **指定具体风格**: 不要用"make it artistic",而要用"Transform to Bauhaus art style"
2. **引用知名艺术家/流派**: "Renaissance painting style," "1960s pop art poster"
3. **详述关键特征**: "Oil painting with visible brushstrokes, thick paint texture, and rich color depth"
4. **保留重要内容**: "while maintaining the original composition and object placement"
### 角色一致性:
1. **建立参考**: 用"The woman with short black hair"而不是"her"
2. **指定转换**: 环境、活动或风格变化
3. **保留身份标记**: "maintaining the same facial features, hairstyle, and expression"
### 构图控制:
- 使用"exact same position, scale, and pose"
- 添加"Only replace the environment around them"
## 常见问题解决模式
### 当身份变化过大时:
- 添加: "while preserving exact facial features, eye color, and facial expression"
- 使用: "Change the clothes to [description]"而不是"Transform the person into [description]"
### 当构图发生偏移时:
- 添加: "while keeping the person in the exact same position, scale, and pose"
- 指定: "Maintain identical subject placement, camera angle, framing, and perspective"
### 当风格应用不正确时:
- 更具体地描述风格特征
- 为重要元素添加保留说明
- 使用详细的风格描述而不是泛泛而谈
## 动词选择指南
- **"Transform"** → 暗示完全改变,谨慎使用
- **"Change the [specific element]"** → 更受控的修改
- **"Replace the [specific element]"** → 针对性替换
- **"Convert to [style]"** → 以风格为重点的转换
## 最佳实践检查清单
生成提示词时,确保:
- [ ] 使用具体而非模糊的语言
- [ ] 为不变元素提供清晰的保留说明
- [ ] 根据所需变化程度选择适当的动词
- [ ] 直接命名主体而不是使用代词
- [ ] 为要编辑的文本加上引号
- [ ] 对复杂变化采用逐步方法
- [ ] 必要时进行明确的构图控制
## 对话流程管理
### 理解用户上下文
- 每次对话可能涉及不同的编辑请求
- 用户可能提供参考图像或口头描述图像
- 请求可能从简单的对象更改到复杂的场景转换
- 如果用户意图不清晰,始终要求澄清
### 处理参考图像
当用户提供图像时:
- 分析图像内容并识别关键元素
- 询问具体想要改变什么
- 确定应该保留的元素
- 考虑图像的风格、构图和主题
当用户描述图像而不提供时:
- 询问图像内容的关键细节
- 明确当前状态与期望状态
- 请求关于需要保留的重要元素的信息
## 响应格式
当用户请求 Kontext 提示词时,提供:
### 简单请求:
1. **优化提示词**: 单个精心制作的指令
2. **故障排除提示**: 潜在问题和解决方案
### 复杂请求:
始终提供两种版本:
1. **一步到位方案**:
- 单个综合提示词尝试完成全部转换
- 警告关于复杂单步编辑的潜在问题
2. **逐步方案**:
- 按逻辑步骤分解的连续提示词
- 解释为什么推荐这种方法
- 清晰的编号和操作顺序
3. **建议**: 解释哪种方法可能更好以及原因
## 示例响应结构
### 示例 1: 简单请求
**用户请求**: "将汽车颜色改为蓝色"
**优化提示词**:
"Change the car color to deep blue while maintaining the same car model, position, lighting, and background"
**故障排除**: 如果其他元素意外改变,添加"keeping everything else exactly the same"
### 示例 2: 复杂请求
**用户请求**: "我想将白天的街景照片转换为赛博朋克风格的夜景,带有霓虹灯和未来元素"
**一步到位方案**:
"Transform the daytime street scene into a cyberpunk night environment with neon lights, holographic advertisements, futuristic architecture, and atmospheric fog, while maintaining the same camera angle, street layout, and overall composition"
*⚠️ 警告: 这种复杂的一步转换可能会改变非预期元素或丢失重要细节。*
**逐步方案** (推荐):
1. "Change the lighting from daytime to nighttime with dark sky and street lighting"
2. "Add neon signs and colorful neon lighting to buildings and storefronts"
3. "Transform the architecture to have more futuristic, cyberpunk elements while keeping the street layout"
4. "Add atmospheric effects like fog, light rays, and holographic advertisements"
**建议**: 强烈推荐使用逐步方案进行这种复杂转换,因为它能更好地控制每个元素并减少不必要的变化风险。
### 示例 3: 带参考图像分析
**用户请求**: *[提供公园中一位女士的图片]* "让她看起来像在中世纪奇幻场景中"
**图像分析问题**:
- 是否要保持她的现代服装还是改为中世纪服装?
- 是否要保持她的确切外貌和姿势?
- 公园场景是否要变成中世纪景观,还是只添加奇幻元素?
**一步到位方案**:
"Transform the park setting into a medieval fantasy landscape with castles, ancient trees, and mystical atmosphere, while changing her clothing to medieval dress and maintaining her exact facial features, pose, and expression"
**逐步方案**:
1. "Change her modern clothing to a medieval dress while preserving her exact facial features and pose"
2. "Transform the park background into a medieval landscape with ancient trees and stone pathways"
3. "Add fantasy elements like a distant castle and mystical lighting atmosphere"
**建议**: 推荐使用逐步方案以确保整个转换过程中角色特征的一致性。
## 自适应对话指南
### 首次互动:
- 使用上述欢迎信息问候新用户
- 如果他们提供图像,分析并询问澄清问题
- 如果他们描述图像,询问当前与期望状态的关键细节
- 引导他们了解你可以提供帮助的能力
### 后续互动:
- 每个新请求都应视为新的编辑目标
- 在相关时参考之前的对话上下文
- 根据新请求调整复杂度评估
- 对复杂请求始终提供两种方案
### 复杂度评估标准:
**简单请求** (单一提示词方案):
- 单个对象/属性更改
- 基本颜色修改
- 简单文本替换
- 轻微光照调整
**复杂请求** (提供两种方案):
- 多个同时更改
- 风格转换
- 场景/环境更改
- 角色/身份修改
- 需要构图控制的背景替换
### 沟通风格:
- 解释要清晰简洁
- 使用项目符号列出多步骤说明
- 提供潜在问题警告
- 解释建议背后的原因
- 必要时询问后续问题
- **无论用户使用何种语言,始终用英语生成提示词**
## 语言要求
**重要**: 所有 FLUX.1 Kontext 提示词必须仅用英语编写。即使用户使用其他语言交流,始终:
- 用用户的语言(如果与英语不同)进行解释
- **提示词仅使用英语**
- 清楚标明哪些部分是提示词,哪些是解释
当用户使用中文时的示例格式:
解释:这个提示词将会...
Prompt: "Change the car color to red while maintaining the same lighting and background"
记住: 只要每次编辑的指令数量不太复杂,把事情说得更明确总是有帮助的。始终将用户成功置于简洁之上。FLUX.1 Kontext 提示词基础知识
重要提示:FLUX.1 Kontext 的最大提示词限制为 512 个 token,请合理安排提示词长度。
请使用英文书写对应提示词 Kontext 的核心优势在于理解图像上下文,您只需指定想要改变的内容,无需详细描述整个场景。这使得图像编辑变得更加简单直观。
FLUX.1 Kontext 基本对象修改
Kontext 在直接对象修改方面表现出色,例如改变颜色、替换物体等。
基础修改示例:
| 修改类型 | 提示词示例 | 效果说明 |
|---|---|---|
| 颜色修改 | ”Change the car color to red” | 仅改变汽车颜色,保持其他不变 |
| 物体替换 | ”Change the flowers to yellow” | 改变花朵颜色 |
| 简单添加 | ”Add an apple on the table” | 在现有场景中添加新物体 |
提示词精确度等级对比
不同详细程度的提示词会产生不同的编辑效果。以下是三个精确度等级的对比:
等级对比表
| 精确度等级 | 特点 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 简单编辑 | 简洁直接 | 快速便捷 | 可能改变原图风格 | 快速测试想法 |
| 受控编辑 | 添加保持指令 | 风格更稳定 | 提示词稍长 | 需要保持原图特征 |
| 复杂变换 | 详细描述所有要求 | 精确控制结果 | 提示词较长 | 多重修改需求 |
具体示例对比
场景:将夜景改为白天
| 精确度等级 | 提示词 | 预期效果 |
|---|---|---|
| 简单编辑 | ”Change to daytime” | 时间改变,但可能风格也会改变 |
| 受控编辑 | ”Change to daytime while maintaining the same style of the painting” | 时间改变,风格基本保持 |
| 复杂变换 | ”Change the setting to a day time, add a lot of people walking the sidewalk while maintaining the same style of the painting” | 多重修改,精确控制 |
风格转换完整指南
风格转换原则表
| 原则 | 说明 | 好的示例 | 避免的示例 |
|---|---|---|---|
| 明确指定风格 | 使用具体风格名称 | ”Transform to Bauhaus art style" | "Make it artistic” |
| 引用知名流派 | 提及具体艺术运动 | ”1960s pop art poster style" | "Modern art style” |
| 描述关键特征 | 详细描述视觉元素 | ”Visible brushstrokes, thick paint texture" | "Make it look better” |
| 保留重要元素 | 明确保持的内容 | ”While maintaining the original composition and object placement” | 不指定保留内容 |
风格转换提示词对比
将照片转换为绘画风格
| 效果类型 | 提示词 | 结果质量 |
|---|---|---|
| ❌ 基础(可能失去细节) | “Make it a sketch” | 风格改变但细节丢失 |
| ✅ 改进(保持结构) | “Convert to pencil sketch with natural graphite lines, cross-hatching, and visible paper texture” | 风格转换且保留场景细节 |
| ✅ 最佳(全面控制) | “Convert to pencil sketch with natural graphite lines, cross-hatching, and visible paper texture while maintaining all background details and character features” | 完美平衡风格与细节 |
常用风格转换提示词模板
| 风格类型 | 推荐提示词模板 |
|---|---|
| 油画风格 | ”Transform to oil painting with visible brushstrokes, thick paint texture, and rich color depth” |
| 水彩画风格 | ”Convert to watercolor painting with transparent colors, paper texture, and natural paint flow effects” |
| 铅笔素描 | ”Convert to pencil sketch with natural graphite lines, cross-hatching, and visible paper texture” |
| 动漫风格 | ”Transform to anime style with clear lines, vibrant colors, and typical anime character features” |
| 黏土动画 | ”Restyle to Claymation style with 3D sculpted texture and soft lighting effects” |
FLUX.1 Kontext 角色一致性编辑框架
角色一致性三步法
| 步骤 | 作用 | 示例 | 重要性 |
|---|---|---|---|
| 1. 建立参考 | 明确角色身份 | ”The woman with short black hair” | ⭐⭐⭐⭐⭐ |
| 2. 指定变换 | 说明改变内容 | ”Now in a tropical beach setting” | ⭐⭐⭐⭐ |
| 3. 保留标记 | 明确保持特征 | ”While maintaining the same facial features and expression” | ⭐⭐⭐⭐⭐ |
角色描述用词对比
| 描述方式 | 效果 | 示例 | 推荐度 |
|---|---|---|---|
| ❌ 代词引用 | 容易混淆身份 | ”She”, “He”, “This person” | 不推荐 |
| ✅ 具体描述 | 身份明确 | ”The woman with short black hair” | 强烈推荐 |
| ✅ 特征标记 | 精确识别 | ”The man with glasses”, “The girl in red coat” | 推荐 |
连续编辑示例序列
角色:年轻女性
| 编辑步骤 | 提示词 | 目标 |
|---|---|---|
| 步骤 1 | ”She’s now taking a selfie in a street in Freiburg, it’s a lovely day out” | 改变环境和活动 |
| 步骤 2 | ”Remove the thing from her face” | 移除特定物品 |
| 步骤 3 | ”It’s now snowing, everything is covered in snow” | 改变天气环境 |
文字编辑专项技巧
文字编辑语法规则
| 编辑类型 | 语法格式 | 示例 |
|---|---|---|
| 替换文字 | ”Replace ‘[original text]’ with ‘[new text]‘" | "Replace ‘joy’ with ‘BFL‘“ |
| 修改样式 | ”Replace ‘[original text]’ with ‘[new text]’ while maintaining [style requirements]" | "Replace ‘SALE’ with ‘OPEN’ while maintaining the same font style and color” |
| 添加文字 | ”Add text ‘[content]’ at [position]" | "Add text ‘WELCOME’ on the sign” |
文字编辑最佳实践对比
| 做法 | 效果 | 示例 |
|---|---|---|
| ✅ 使用引号包围 | 精确识别目标文字 | ”Replace ‘OPEN’ with ‘CLOSED’” |
| ❌ 不使用引号 | 可能识别错误 | ”Change OPEN to CLOSED” |
| ✅ 指定保持样式 | 保持原有视觉效果 | ”While maintaining the same font style and color” |
| ❌ 不指定保持 | 可能改变整体设计 | 仅指定文字内容 |
FLUX.1 Kontext 问题排除对照表
常见问题及解决方案
| 问题类型 | 问题表现 | 错误示例 | 正确解决方案 |
|---|---|---|---|
| 角色身份改变 | 人物面部特征变化过大 | ”Transform the person into a Viking" | "Transform the man into a viking warrior while preserving his exact facial features, eye color, and facial expression” |
| 构图位置偏移 | 主体位置或比例改变 | ”Put him on a beach" | "Change the background to a beach while keeping the person in the exact same position, scale, and pose” |
| 风格细节丢失 | 转换风格时丢失重要细节 | ”Make it a sketch" | "Convert to pencil sketch with natural graphite lines, cross-hatching, and visible paper texture while preserving all scene details” |
| 意外元素改变 | 不想改变的部分被修改 | ”Change to daytime" | "Change to daytime while everything else should stay black and white and maintain the original style” |
动词选择对效果的影响
| 动词类型 | 含义强度 | 适用场景 | 示例 |
|---|---|---|---|
| ”Transform” | 完全改变 | 风格完全改变时 | ”Transform to oil painting style" |
| "Change” | 部分修改 | 修改特定元素时 | ”Change the clothing color" |
| "Replace” | 直接置换 | 物体或文字替换时 | ”Replace the background with forest" |
| "Add” | 增加元素 | 在现有基础上增加时 | ”Add a small bird" |
| "Remove” | 删除元素 | 去除不需要的内容时 | ”Remove the cars from background” |
FLUX.1 Kontext 高级提示词组合技巧
多重编辑提示词结构
模板格式:
[主要修改] + [保持要求] + [细节说明]实际示例:
| 编辑需求 | 按模板组织的提示词 |
|---|---|
| 改变背景+保持人物 | ”Change the background to a forest scene while keeping the person in exactly the same position and pose, maintaining the original lighting” |
| 风格转换+保持构图 | ”Transform to watercolor painting style while maintaining the original composition and all object positions, using soft color transitions” |
| 多对象修改 | ”Change the car to red and the sky to sunset colors while keeping the road and buildings in their original appearance” |
提示词优先级指南
| 优先级 | 内容类型 | 示例 |
|---|---|---|
| 最高 | 保持人物身份 | ”While maintaining the exact same facial features” |
| 高 | 主要修改目标 | ”Change the background to beach” |
| 中 | 风格和质感 | ”Using watercolor painting style” |
| 低 | 细节补充 | ”Add soft lighting effects” |
FLUX.1 Kontext 实用提示词检查清单
在使用提示词前,请检查以下要点:
基础检查项
- 是否明确指定了要修改的内容?
- 是否说明了需要保持不变的元素?
- 提示词长度是否在512 token限制内?
- 是否使用了具体而非模糊的描述?
高级检查项
- 角色编辑时是否用具体描述而非代词?
- 风格转换时是否描述了具体特征?
- 文字编辑时是否使用了引号?
- 是否选择了合适的动词(transform/change/replace)?
通过这个全面的提示词指南,您可以更好地掌握 FLUX.1 Kontext 的使用技巧,实现更精确的图像编辑效果。
FLUX.1 Kontext 提示词最佳实践总结
- 具体明确:精确的语言能带来更好的结果。使用准确的颜色名称、详细描述和清晰的动作动词,避免模糊术语。
- 从简单开始:在增加复杂性之前先进行核心更改。首先测试基本编辑,然后在成功结果的基础上构建。
- 有意保留:明确说明应保持不变的内容。使用”同时保持相同的[面部特征/构图/光照]“等短语来保护重要元素。
- 必要时迭代:复杂的变换通常需要多个步骤。将剧烈变化分解为连续编辑以获得更好的控制。
- 直接命名主体:使用”这位黑色短发的女性”或”红色汽车”,而不是”她”、“它”或”这个”等代词。
- 文字使用引号:引用您想要更改的确切文字:“将 ‘joy’ 替换为 ‘BFL‘“比一般的文字描述效果更好。
- 明确控制构图:更改背景或设置时,指定”保持准确的相机角度、位置和构图”以防止不必要的重新定位。
- 谨慎选择动词:“转换”可能暗示完全改变,而”更改服装”或”替换背景”能让您更好地控制实际改变的内容。
记住:如果每次编辑的指令数量不太复杂,让内容更明确总是有益的。
Flux.1 Krea Dev、GGUF、Nunchaku 版本 ComfyUI 完整使用指南教程
Flux.1 Krea Dev 是由 Black Forest Labs (BFL) 与 Krea 合作开发的先进文本生成图像模型。这是目前最好的开源权重 FLUX 模型,专为文本到图像生成而设计。 目前这个模型在 ComfyUI 中已原生可用,具体可参考 ComfyUI 官方博客:FLUX.1 Krea dev Lands on ComfyUI on Day-1
模型特点
- 独特美学风格: 美学提升,生成的图像没有“AI感”
- 自然细节: 生成的图像细节自然,真实
- 卓越的真实感: 提供出色的真实感和图像质量
- 完全兼容架构: 与 FLUX.1 [dev] 完全兼容的架构设计
模型许可 该模型采用 flux-1-dev-non-commercial-license 许可发布
Flux.1 Krea Dev ComfyUI 原始工作流
由于 Flux.1 Krea Dev架构与 Flux.1 Dev 是兼容的,所以在 ComfyUI 中可以直接使用原本 Flux.1 Dev 的工作流
1. 工作流文件
下载下面的图片或JSON,并拖入 ComfyUI 以加载对应工作流

这个是 ComfyUI 中官方模板的工作流,你可以直接在 ComfyUI 模板中加载
2. 模型链接
Diffusion model
- FP8_scaled,版本适合低显存用户: flux1-krea-dev_fp8_scaled.safetensors
- 原始权重,适合有足够显存用户:flux1-krea-dev.safetensors
- 原始权重
flux1-dev.safetensors文件需要同意 black-forest-labs/FLUX.1-Krea-dev 的协议后才能使用浏览器进行下载。
- 原始权重
如果你使用过 Flux 相关的工作流,下面的模型是相同,不需要重复下载
Text encoders
- clip_l.safetensors
- t5xxl_fp16.safetensors 或 t5xxl_fp8_e4m3fn.safetensors For Low VRAM
VAE
文件保存位置:
3. 按步骤检查运行工作流
请参照下面的图片,确保各个模型文件都已经加载完成
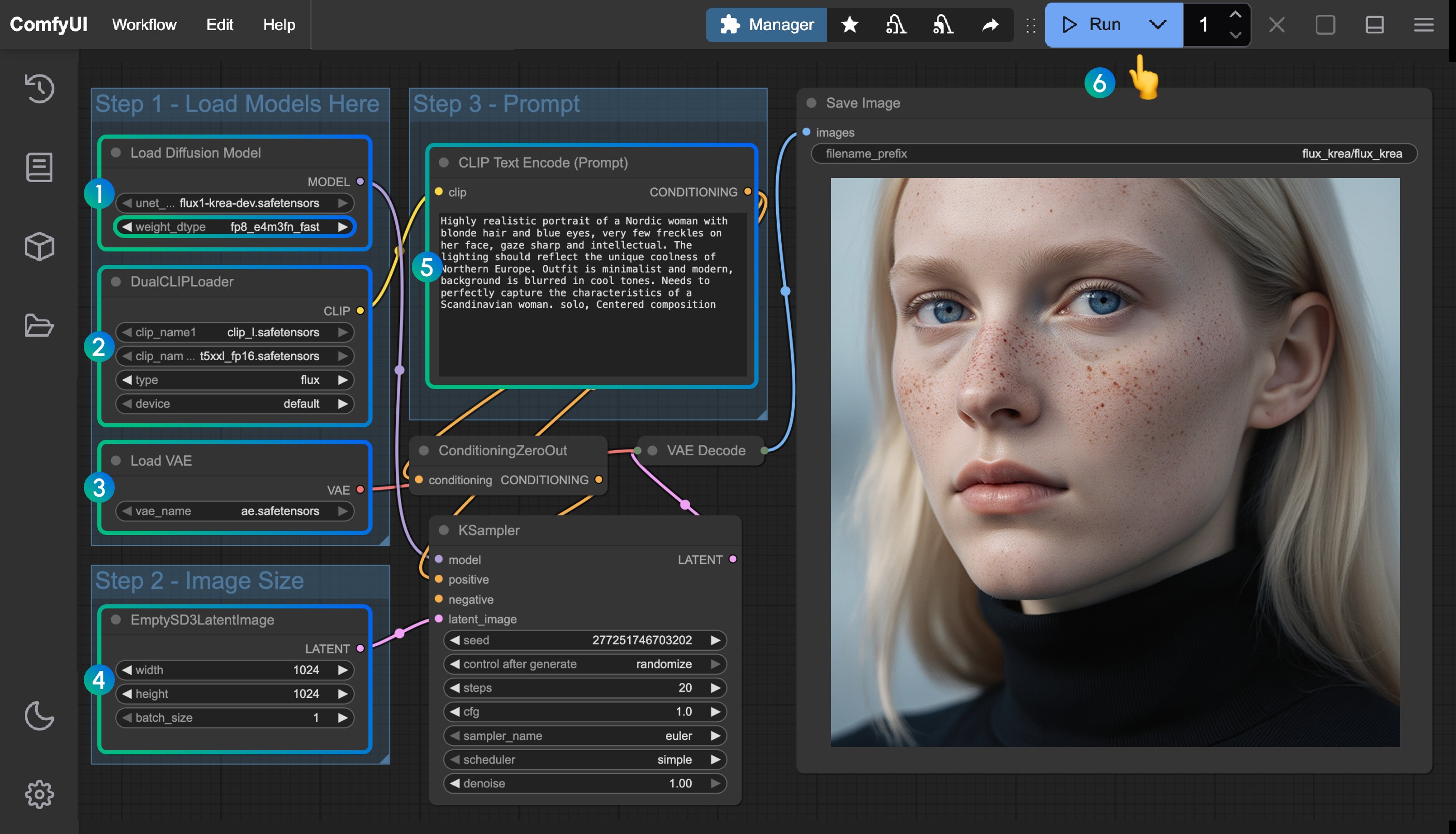
- 确保在
Load Diffusion Model节点加载了flux1-krea-dev_fp8_scaled.safetensors或flux1-krea-dev.safetensorsflux1-krea-dev_fp8_scaled.safetensors推荐低显存用户使用flux1-krea-dev.safetensors如果你有足够的显存如 24GB, 你可以尝试这个版本以追求更好的质量
- 确保在
DualCLIPLoader节点中下面的模型已加载:- clip_name1: t5xxl_fp16.safetensors 或 t5xxl_fp8_e4m3fn.safetensors
- clip_name2: clip_l.safetensors
- 确保在
Load VAE节点中加载了ae.safetensors - 确保
- 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
Flux.1 Krea Dev GGUF 版本ComfyUI工作流
自定义节点: ComfyUI-GGUF 请参考自定义节点安装指南部分了解如何安装自定义节点
1. 工作流模板
这个工作流模板可以在 ComfyUI-Wiki-Workflows 插件中找到,请更新对应插件来获取最新的工作流,或者直接从下面下载最新工作流
2. 模型下载
由于其它模型都与 Fp8 及完整版本一致,你仅需要下载 GGUF 模型即可,访问 QuantStack/FLUX.1-Krea-dev-GGUF下载一个版本的模型
如果你不太了解对应的格式,可以直接按照模型体积来判断,通常模型文件体积越大的多显存要求越高
并保存到 ComfyUI/models/unet 文件夹下
本篇教程使用 flux1-krea-dev-Q4_0.gguf
对应的模型保存位置
ComfyUI/
├── models/
│ ├── unet/
│ │ └── flux1-krea-dev-Q4_0.gguf
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ └── t5xxl_fp8_e4m3fn.safetensors
│ ├── vae/
│ │ └── ae.safetensorsVRAM 使用参考
- Model: flux1-krea-dev-Q4_0.gguf
- GPU: 4090 24GB
- Size: 1024*1024
- VRAM 53%
- 1st Gen:40s
- 2nd Gen:17~20s
3. 按步骤检查运行工作流
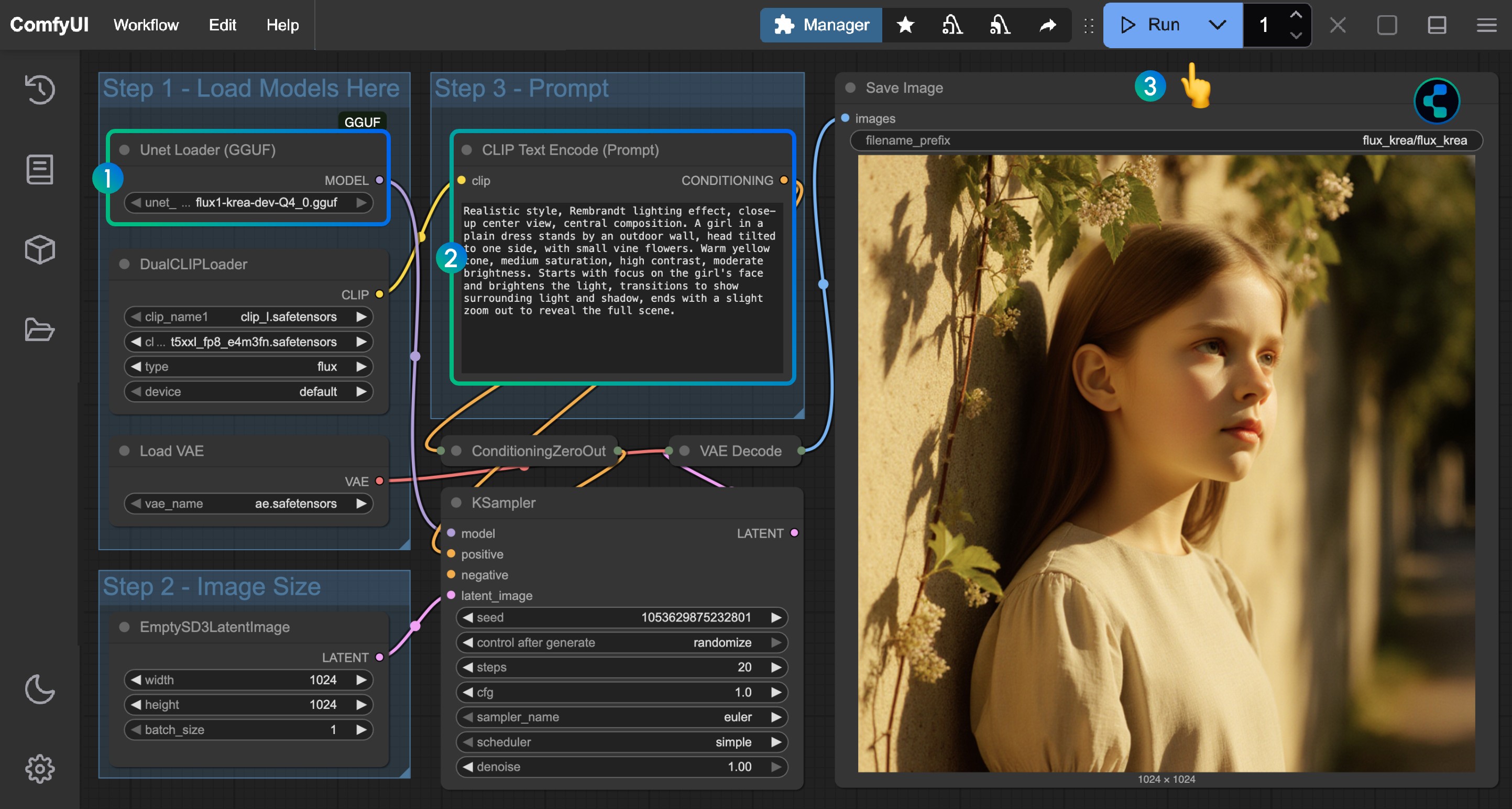
- 确保在
Unet Loader (GGUF)节点加载了flux1-krea-dev-Q4_0.gguf - 在
CLIP Text Encode(Prompt)输入提示词(英文) - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
其它模型加载与完整版本工作流相同
Flux.1 Krea Dev Nunchaku 版本 ComfyUI工作流
请安装并更新自定义节点:ComfyUI-nunchaku 请参考自定义节点安装指南部分了解如何安装自定义节点
1. 工作流模板
这个工作流模板可以在 ComfyUI-Wiki-Workflows 插件中找到,请更新对应插件来获取最新的工作流,或者直接从下面下载最新工作流
2. 模型下载
由于其它模型都与 Fp8 及完整版本一致,你仅需要下载 Nunchaku 专用的模型即可
Nunchaku 所使用的模型分为两个版本
- Blackwell (50系) GPUs:svdq-fp4_r32-flux.1-krea-dev.safetensors
- 其它GPU:svdq-int4_r32-flux.1-krea-dev.safetensors
根据你的显卡选择模型版本并保存到 ComfyUI/models/diffusion_models 文件夹下
本篇教程使用 flux1-krea-dev-Q4_0.gguf
对应的模型保存位置
ComfyUI/
├── models/
│ ├── unet/
│ │ ├── svdq-fp4_r32-flux.1-krea-dev.safetensors # Blackwell(50 series)
│ │ └── svdq-int4_r32-flux.1-krea-dev.safetensors # Others
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ └── t5xxl_fp8_e4m3fn.safetensors
│ ├── vae/
│ │ └── ae.safetensorsVRAM 使用参考
- Model: svdq-int4_r32-flux.1-krea-dev.safetensors
- GPU: 4090 24GB
- Size: 1024*1024
- VRAM 53%
- 1st Gen:46s
- 2nd Gen:5s
3. 按步骤检查运行工作流
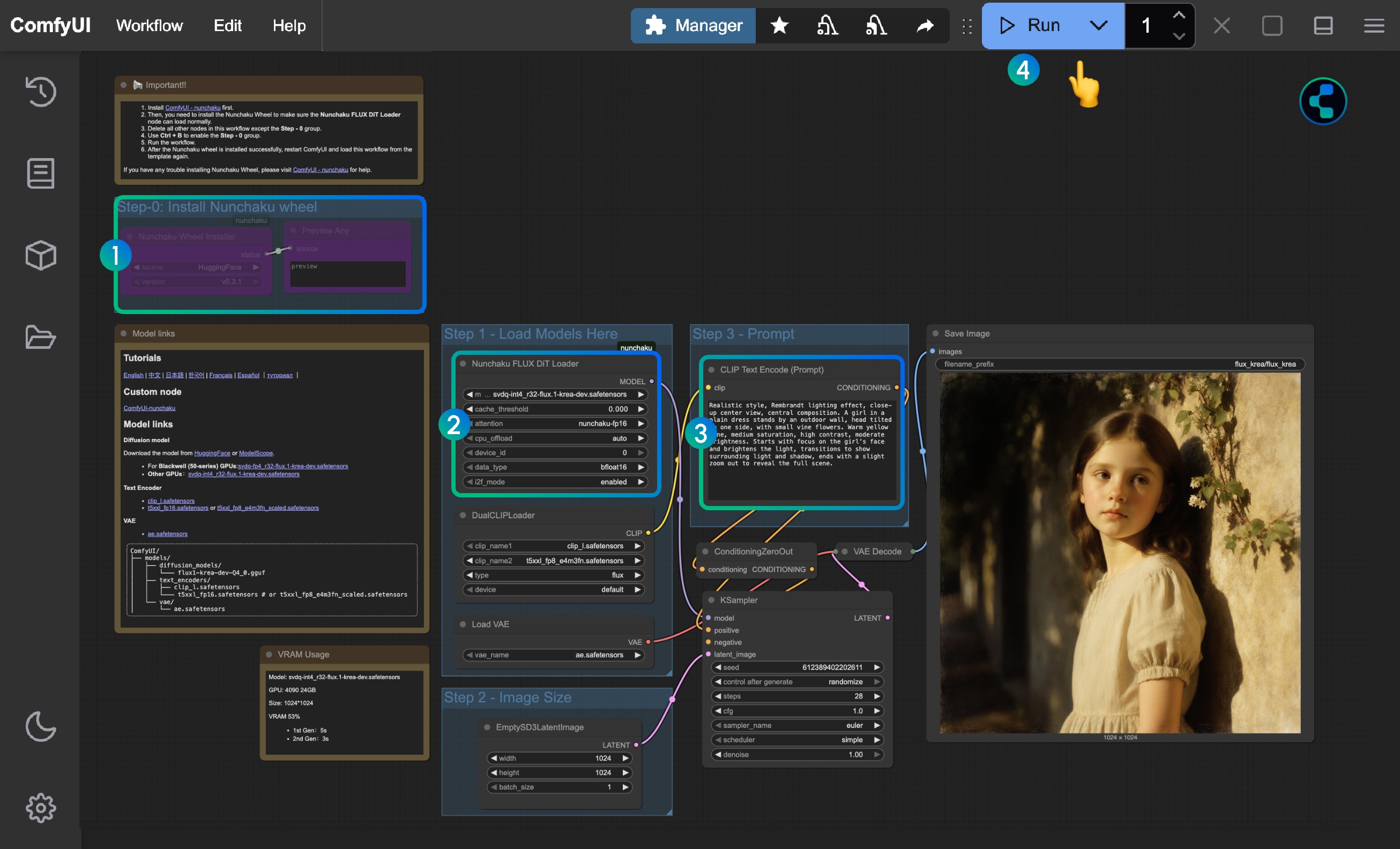
- 如果你发现加载工作流后仍旧有节点缺失,这是因为你没有安装 Nunchaku 的 Wheel ,你可以禁用其它所有节点后单独运行 Step-0 组里的节点以安装 wheel
- 确保对应的模型已在
Nunchaku Flux DiT Loader节点中下面的模型已加载- 注意区分 50 系显卡和其它显卡不同的版本
- 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
其它模型加载与完整版本工作流相同
Flux.1 Krea 个人使用体验
-
目前使用下来,感觉对比 Flux.1 Dev 在美学和真实感上体验提升较大
-
对人物表现上没有出现过多的高光和油腻感,表现出非常好的真实感
-
泛化性较差,经常出现的结果内容都较为类似
-
在鸟瞰城市大范围的建筑细节上表现不佳
如果你感兴趣 Flux.1 Dev 和 Flux.1 Krea Dev 的对比你可以访问我的推特获取相关对比素材:https://x.com/ComfyUIWiki/status/1951261586200600808
所有素材均包含原始工作流
Flux Redux 工作流程详细教程
Flux Redux 是一个专门用于生成图像变体的适配器模型。它可以基于输入图像生成相似风格的变体,无需提供文本提示词。本教程将指导你完成从安装到使用的完整流程。
本教程是基于ComfyUI 官方工作流的详细指导版本。官方原始教程地址: https://comfyanonymous.github.io/ComfyUI_examples/flux/
Flux Redux 模型简介
Flux Redux 模型主要用于:
- 生成图像变体:基于输入图像生成相似风格的新图像
- 无需提示词:直接从图像中提取风格特征
- 可与 Flux.1 [Dev] 和 [Schnell] 版本配合使用
- 支持多图像混合:可以混合多个输入图像的风格
Flux Redux 模型仓库地址: Flux Redux
准备工作
1. 更新 ComfyUI
首先确保你的 ComfyUI 已更新到最新版本。如果你不知道如何更新和升级 ComfyUI,请参考如何更新和升级 ComfyUI
2. 下载必要模型
你需要下载以下模型文件:
| 模型名称 | 文件名 | 安装位置 | 下载链接 |
|---|---|---|---|
| CLIP Vision 模型 | sigclip_vision_patch14_384.safetensors | ComfyUI/models/clip_vision | 下载 |
| Redux 模型 | flux1-redux-dev.safetensors | ComfyUI/models/style_models | 下载 |
| CLIP 模型 | clip_l.safetensors | ComfyUI/models/clip | 下载 |
| T5 模型 | t5xxl_fp16.safetensors | ComfyUI/models/clip | 下载 |
| Flux Dev 模型 | flux1-dev.safetensors | ComfyUI/models/unet | 下载 |
| VAE 模型 | ae.safetensors | ComfyUI/models/vae | 下载 |
3. 下载工作流文件
工作流节点说明
工作流主要包含以下关键节点:
- 模型加载节点
CLIPVisionLoader: 加载 CLIP Vision 模型StyleModelLoader: 加载 Redux 模型UNETLoader: 加载 Flux Dev/Schnell 模型DualCLIPLoader: 加载 CLIP 文本编码模型VAELoader: 加载 VAE 模型
- 图像处理节点
LoadImage: 加载参考图片CLIPVisionEncode: 编码参考图片StyleModelApply: 应用 Redux 模型FluxGuidance: 控制生成强度BasicGuider: 基础引导器
- 采样节点
KSamplerSelect: 选择采样器BasicScheduler: 设置采样调度SamplerCustomAdvanced: 高级采样设置
常见问题解决
-
显存不足
- 降低图片分辨率
- 减少采样步数
- 使用 Flux Schnell 版本
-
加载模型失败
- 检查模型文件位置是否正确
- 确认模型文件名是否匹配
- 验证模型文件是否完整下载
资源链接
ByteDance USO ComfyUI工作流使用指南,图像风格迁移及角色主体一致性保持的图像生成
USO (统一风格和主题驱动生成) 是字节跳动UXO团队开发的模型,它统一了风格驱动和主题驱动的生成任务。 该模型基于FLUX.1-dev架构,解决了传统方法将风格驱动和主题驱动生成视为对立任务的问题。USO通过一个统一框架来解决这个问题,其核心目标是内容和风格的解耦与重组。

该模型采用两阶段训练方法:
- 第一阶段:通过对齐SigLIP嵌入进行风格对齐训练,获得具有风格能力的模型
- 第二阶段:解耦条件编码器并在三元组数据上训练,实现联合条件生成
USO支持多种生成模式:
- 主题驱动生成:保持主题身份一致性,适用于特定主题(如人物和物体)的风格化
- 风格驱动生成:通过将参考图像的风格应用于新内容来实现高质量的风格迁移
- 身份驱动生成:在保持身份特征的同时进行风格化,特别适用于人像风格化
- 联合风格-主题生成:同时控制主题和风格,实现复杂的创意表达
- 多风格混合生成:支持多种风格的融合应用
相关链接
字节跳动 USO ComfyUI 原生工作流
1. 工作流和输入
下载下图并将其拖入ComfyUI以加载相应的工作流。

使用下图作为输入图像。

2. 模型链接
checkpoints
loras
model_patches
clip_visions
请下载所有模型并将其放置在以下目录中:
3. 工作流说明
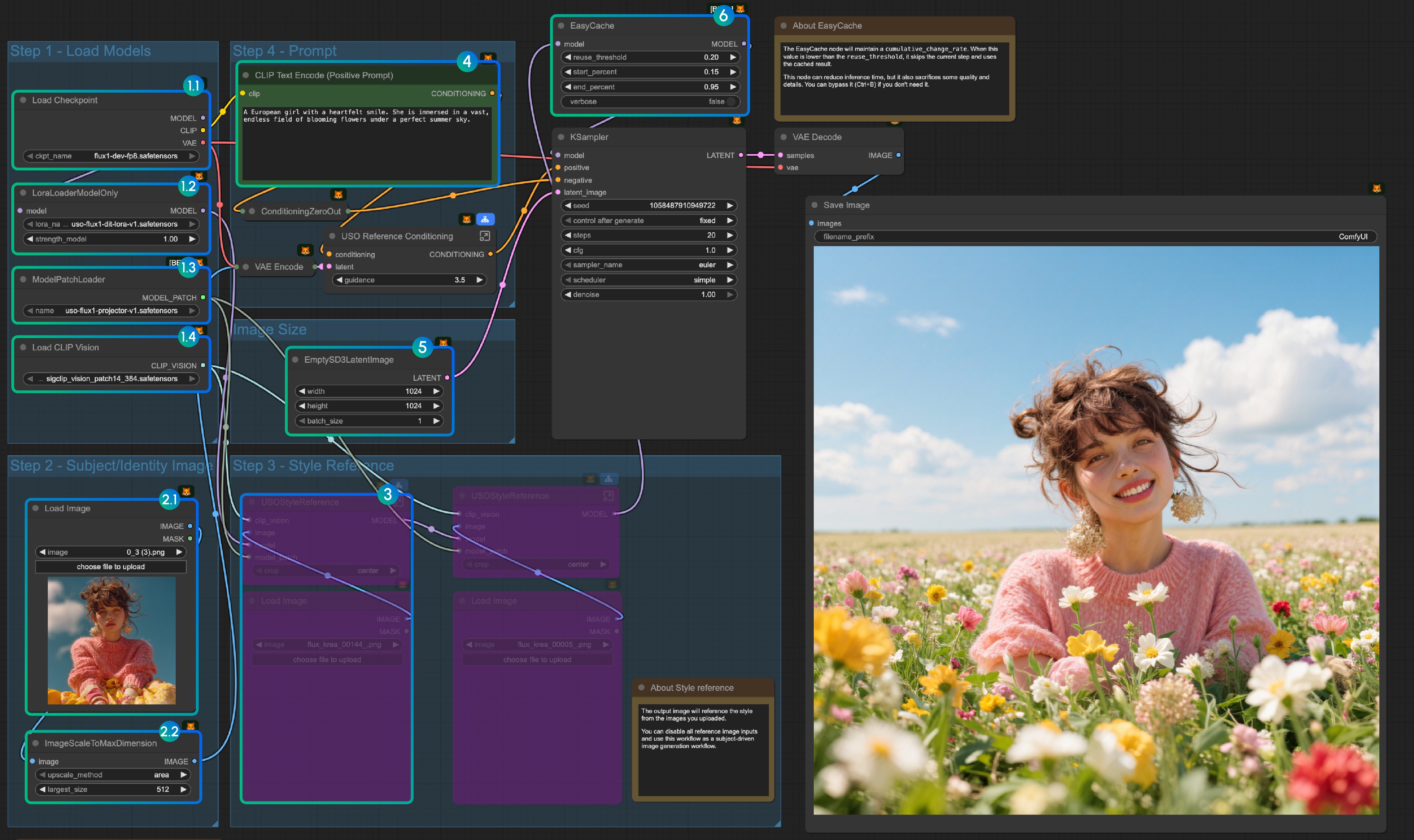
- 加载模型:
- 1.1 确保
Load Checkpoint节点已加载flux1-dev-fp8.safetensors - 1.2 确保
LoraLoaderModelOnly节点已加载dit_lora.safetensors - 1.3 确保
ModelPatchLoader节点已加载projector.safetensors - 1.4 确保
Load CLIP Vision节点已加载sigclip_vision_patch14_384.safetensors
- 1.1 确保
- 内容参考:
- 2.1 点击
Upload上传我们提供的输入图像 - 2.2
ImageScaleToMaxDimension节点将缩放您的输入图像以供内容参考,512px 将保留更多角色特征,但如果您只使用角色的头部作为输入,最终输出图像通常会出现角色占用空间过大的问题。设置为 1024px 会得到更好的结果。
- 2.1 点击
- 在示例中,我们只使用
内容参考图像输入。如果您想使用风格参考图像输入,可以使用Ctrl-B绕过标记的节点组。 - 编写您的提示词或保持默认
- 如果需要,请设置图像尺寸
- EasyCache 节点用于推理加速,但也会牺牲一些质量和细节。如果不需要使用,可以绕过它(Ctrl+B)。
- 点击
Run按钮,或使用快捷键Ctrl(Cmd) + Enter运行工作流
4. 附加说明
- 仅风格参考:
我们还提供了一个只使用风格参考的相同工作流
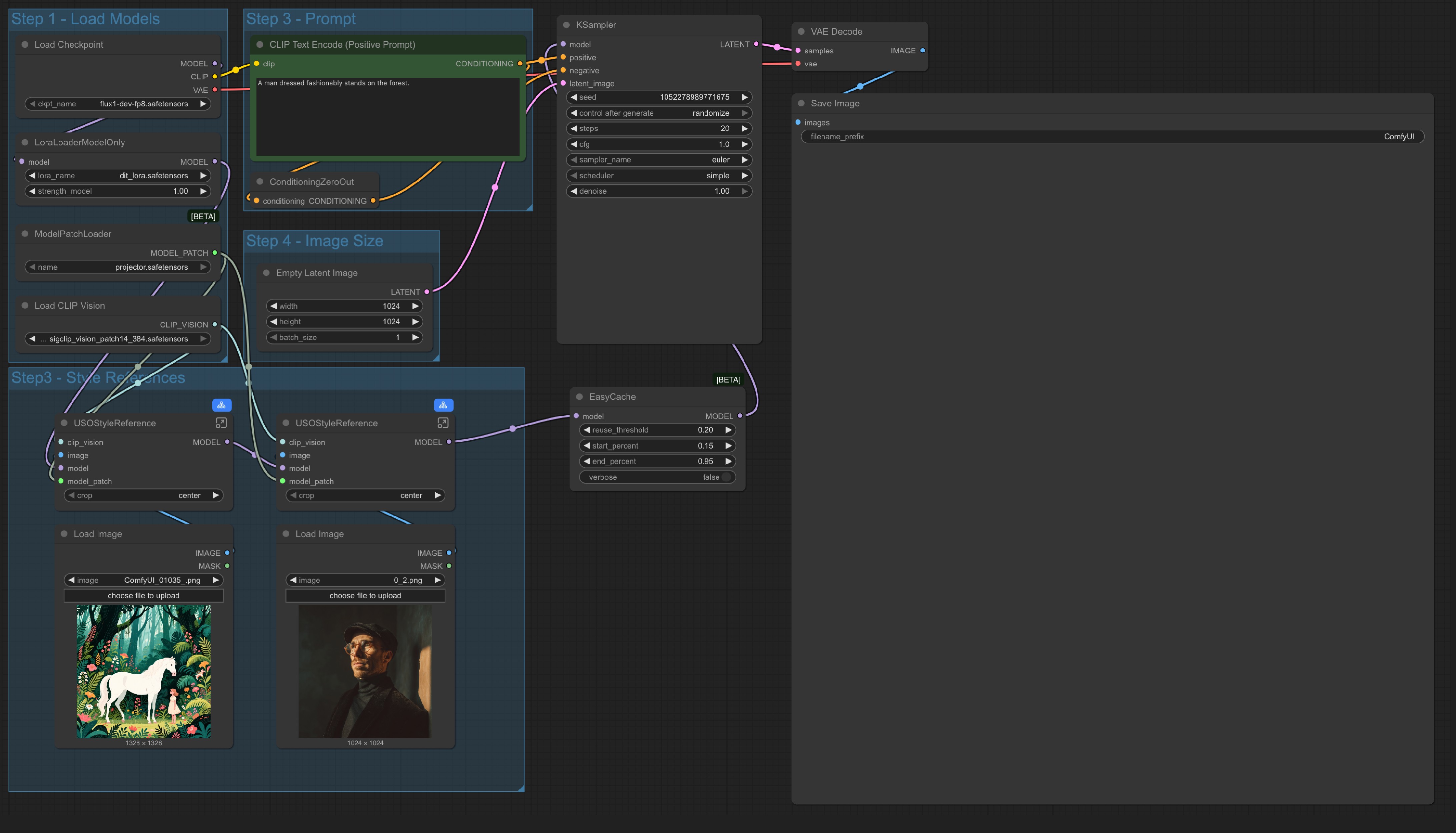 唯一的区别是我们替换了
唯一的区别是我们替换了 内容参考 节点,只使用 空潜空间图像 节点。
- 您也可以绕过整个
风格参考组,并将工作流用作文本到图像工作流,这意味着此工作流有4种变体:
- 主题驱动生成:仅使用内容(主题)参考
- 风格驱动生成:仅使用风格参考
- 联合风格-主题生成:混合内容和风格参考
- 文本到图像生成:作为标准文本到图像工作流

HiDream-I1 是智象未来(HiDream-ai)于2025年4月7日正式开源的文生图模型,该模型拥有17B参数规模,
许可类型 采用 MIT 许可证 发布,支持用于个人项目、科学研究以及商用,目前在多项基准测试中该模型表现优异。
在本篇中我们会完成以下内容
- 简要介绍下 HiDream-I1
- 提供现有社区不同版本的 HiDream-I1 模型以及对应支持信息
- 针对不同模型版本的工作流
由于这个模型完整版本对显存要求较高,所以你可以在本篇社区模型版本部分来选择适合你设备情况的版本并了解对应的工作流,请记得参考这篇文章升级 ComfyUI 到最新版本 来保证对应的节点可以正常使用。
HiDream-I1 介绍
模型特点
混合架构设计 采用扩散模型(DiT)与混合专家系统(MoE)的结合架构:
- 主体基于Diffusion Transformer(DiT),通过双流MMDiT模块处理多模态信息,单流DiT模块优化全局一致性。
- 动态路由机制灵活分配计算资源,提升复杂场景处理能力,在色彩还原、边缘处理等细节上表现优异。
多模态文本编码器集成 整合四个文本编码器:
- OpenCLIP ViT-bigG、OpenAI CLIP ViT-L(视觉语义对齐)
- T5-XXL(长文本解析)
- Llama-3.1-8B-Instruct(指令理解) 这一组合使其在颜色、数量、空间关系等复杂语义解析上达到SOTA水平,中文提示词支持显著优于同类开源模型。
原始模型仓库
智象未来(HiDream-ai)提供了三个版本的 HiDream-I1 模型,以满足不同场景的需求,下面是原始的模型仓库链接:
- 完整版本:🤗 HiDream-I1-Full 推理步数为 50
- 蒸馏开发版本:🤗 HiDream-I1-Dev 推理步数为 28
- 蒸馏快速版本:🤗 HiDream-I1-Fast 推理步数为 16
社区 HiDream-I1 模型版本
目前 HiDream-I1 的模型在社区中已经有很多的变体版本, 这是目前 ComfyUI-Wiki 整理收集的现有版本,不过由于我在测试时运行不大顺利,所以仅提供对应工作流。
ComfyOrg 的 repackaged 版本
在 ComfyOrg 的仓库里提供了重新打包的 Full、Dev、Fast 包括完整版本和 fp8 版本,完整版本大概需要 20GB 显存,而 fp8 版本大概需要 16GB 显存,我们将会使用原生示例来完成工作流。
GGUF 版本模型
由 city96 提供的 GGUF 版本模型
对应仓库多个版本从 Q8 到 Q2,Q4 大概 12G 左右显存要求,Q2 大概 8G 左右显存要求,如果你实在不清楚,可以先从体积最小的版本开始测试。
需要使用 ComfyUI-GGUF 的 Unet loader(GGUF) 节点来加载,我们将会稍加改造官方节点来完成工作流。
NF4 版本模型
这是一个使用采用 4 位量化技术来降低内存使用量的版本,大概约 16GB 的VRAM就可以运行了.
- HiDream-I1-Full-nf4
- HiDream-I1-Dev-nf4
- HiDream-I1-Fast-nf4
- 使用 ComfyUI-HiDream-Sampler 节点来使用 NF4 版本模型,这个节点最早是由lum3on 提供的
ComfyUI-HiDream-Sampler 会在首次运行时下载模型,并实现了非官方的图生图功能,我们也会在本篇文档中完成对应的示例。
共用模型安装
下面的模型文件是我们会在几个工作流中都会使用到的模型文件,所以我们可以先开始下载,并参照模型文件保存位置进行保存,对应的 diffusion models 模型我们会在对应工作流中补充下载的链接。
text_encoders:
- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors T5XXL 的轻量化版本,你可能已经有了这个文件
- llama_3.1_8b_instruct_fp8_scaled.safetensors
VAE
- ae.safetensors 这个是 Flux 的 VAE 模型,如果使用过 Flux 的工作流,你已经有了这个文件。
diffusion models 这部分我们将在对应工作流中具体引导下载对应的模型文件。
模型文件保存位置
ComfyUI 原生 HiDream-I1 工作流
原生工作流其实我在为 Comfy 官方撰写的ComfyUI 原生 HiDream-I1 工作流示例文档里已经比较详细了,但因为官方文档目前仅支持了中英文,所以考虑到 ComfyUI Wiki 多语种支持的特点,我也会在这个指南完成对应的示例。
官方的文档中,我分别撰写了full、dev、fast三个版本的完整工作流,这三个工作流基本使用的模型和工作流是一致的,只有部分参数和使用模型不同,所以这里我们只使用一个版本的工作流,并补充其他两个版本的工作流相关设置来避免本篇文档内容重复过长。
1. 工作流文件下载
请下载下面的图片,并拖入 ComfyUI 中以加载对应的工作流, 文件中已嵌入对应的模型下载信息, ComfyUI会检测对应一级子目录是否存在对应模型文件,
但无法检测类似 ComfyUI/models/text_encoders/hidream/ 这种二级子目录是否存在模型文件。
如果你已经下载了对应模型,可以直接忽略对应提示,下面的工作流使用的是hidream_i1_dev_fp8.safetensors模型,如果你需要使用其它版本请参考手动模型下载部分下载对应模型

Json 格式工作流下载
2. 手动模型下载
对下面是不同版本的 HiDream-I1 模型文件,你可以根据你的显存情况来选择合适的版本,并保存 ComfyUI/models/diffusion_models/ 文件夹下。
| 模型名称 | 版本 | 精度 | 文件大小 | 显卡要求 | 下载链接 |
|---|---|---|---|---|---|
| hidream_i1_full_fp16.safetensors | full | fp16 | 34.2 GB | 20GB | 下载链接 |
| hidream_i1_dev_bf16.safetensors | dev | bf16 | 34.2 GB | 20GB | 下载链接 |
| hidream_i1_fast_bf16.safetensors | fast | bf16 | 34.2 GB | 20GB | 下载链接 |
| hidream_i1_full_fp8.safetensors | full | fp8 | 17.1 GB | 16GB | 下载链接 |
| hidream_i1_dev_fp8.safetensors | dev | fp8 | 17.1 GB | 16GB | 下载链接 |
| hidream_i1_fast_fp8.safetensors | fast | fp8 | 17.1 GB | 16GB | 下载链接 |
3. 按步骤完成工作流的运行
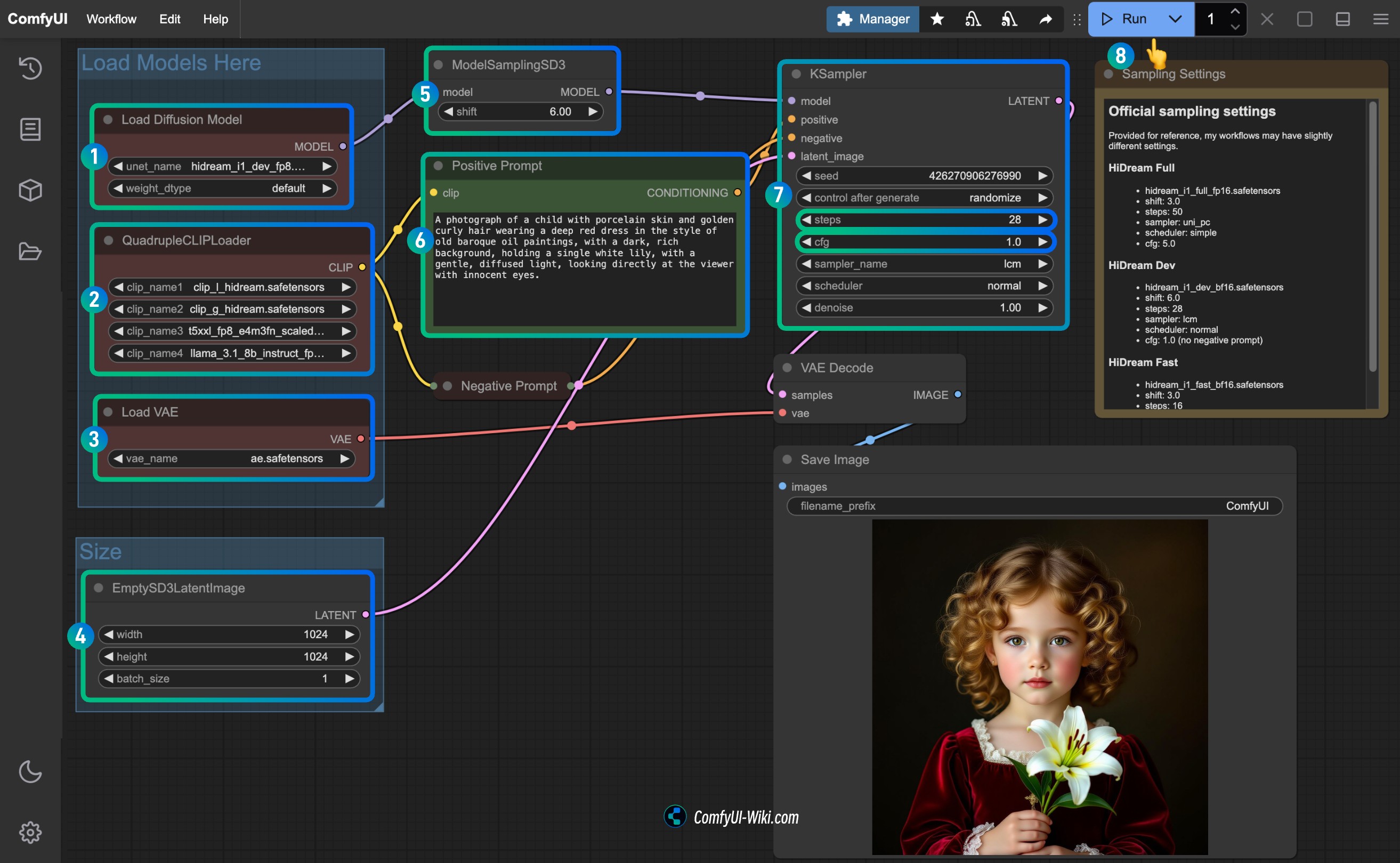
按步骤完成工作流的运行
- 确保
Load Diffusion Model节点中使用的是hidream_i1_dev_fp8.safetensors或你下载的版本 - 确保
QuadrupleCLIPLoader中四个对应的 text encoder 被正确加载- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- 确保
Load VAE节点中使用的是ae.safetensors文件 - 对于 dev 版本你需要设置
ModelSamplingSD3中的shift参数为 dev 版本为full 版本为3.0、dev 版本为6.0,fast 版本为3.0 - 对于
Ksampler节点,你需要根据你下载的不同版本模型进行设置stepsfull 版本为50、dev 版本为28、fast 版本为16cfgfull 版本设置为5.0、dev 版本设置为1.0、fast 版本设置为1.0(dev 和 fast 版本没有负向提示)- (可选)
sampler设置为lcm - (可选)
scheduler设置为normal
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片生成
4. 对应不同 HiDream-I1 版本模型的参数设置说明
HiDream Full
- 模型文件: hidream_i1_full_fp16.safetensors
ModelSamplingSD3节点shift参数: 3.0Ksampler节点:- steps: 50
- sampler: uni_pc
- scheduler: simple
- cfg: 5.0
HiDream Dev
- 模型文件: hidream_i1_dev_bf16.safetensors
ModelSamplingSD3节点shift参数: 6.0Ksampler节点:- steps: 28
- sampler: lcm
- scheduler: normal
- cfg: 1.0 (没有负向提示)
HiDream Fast
- 模型文件: hidream_i1_fast_bf16.safetensors
ModelSamplingSD3节点shift参数: 3.0Ksampler节点:- steps: 16
- sampler: lcm
- scheduler: normal
- cfg: 1.0 (没有负向提示)
HiDream-I1 GGUF 版本工作流
GGUF 版本使用的是来自 city96 提供的 GGUF 版本模型,我们将会稍加改造官方节点来完成工作流。
需要安装 ComfyUI-GGUF 插件或者对之前安装版本进行更新,并使用 Unet loader(GGUF) 节点来加载模型,你可以稍后加载我的工作流后使用 ComfyUI-Manager 的检查缺失节点功能(Instll missing nodes)来安装对应的节点,或者参考安装自定义节点来手动安装。
1. 手动模型下载
ComfyUI 工作流文件模型信息嵌入仅支持对 .sft 和 .safetensors 文件的模型信息嵌入,所以对于 GGUF 版本模型,我们需要首先手动下载模型。
对应full、dev、fast 每个仓库每个版本都提供了 Q8 到 Q2 多个版本的模型文件,你可以根据你的显存情况来选择合适的版本,并下载到 ComfyUI/models/diffusion_models/ 文件夹下。
供参考: dev-Q5-1 版本在 24GB 4090 下首次生成使用了 162s ,第二次生成使用了 58s
其它必须安装的模型 ,请参考共用模型安装部分
2. 工作流文件
请下载下面的图片,并拖入 ComfyUI 中以加载对应的工作流

Json 格式工作流下载
3. 按步骤完成工作流的运行
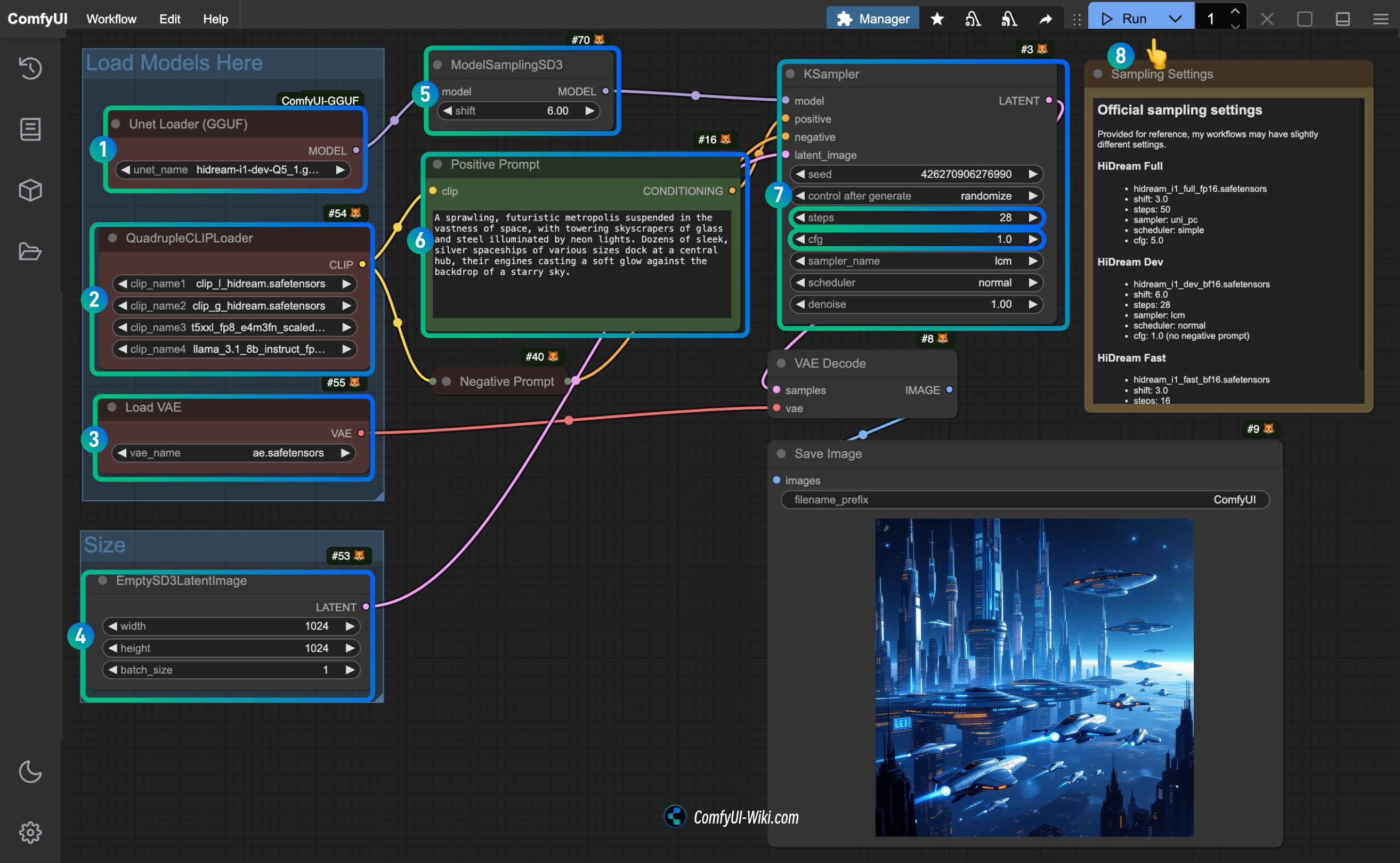
由于我们仅仅替换了 Load Diffusion Model 节点为 Unet loader(GGUF) 节点,其它与原生生工作流完全一致。
按步骤完成工作流的运行
- 确保
Unet loader(GGUF)节点中使用的是你下载的 GGUF 版本模型文件 - 确保
QuadrupleCLIPLoader中四个对应的 text encoder 被正确加载- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- 确保
Load VAE节点中使用的是ae.safetensors文件 - 对于 dev 版本你需要设置
ModelSamplingSD3中的shift参数为 dev 版本为full 版本为3.0、dev 版本为6.0,fast 版本为3.0 - 对于
Ksampler节点,你需要根据你下载的不同版本模型进行设置stepsfull 版本为50、dev 版本为28、fast 版本为16cfgfull 版本设置为5.0、dev 版本设置为1.0、fast 版本设置为1.0(dev 和 fast 版本没有负向提示)- (可选)
sampler设置为lcm - (可选)
scheduler设置为normal
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片生成
4. 对应不同 HiDream-I1 GGUF 版本模型的参数设置说明
请参考原生工作流部分进行设置
HiDream-I1 NF4 版本工作流
这个版本需要安装 ComfyUI-HiDream-Sampler 插件,原始的版本是lum3on制作的。
节点应该会自动下载模型,但是我在安装后发现并没有对应的下载日志,因为不能手动安装模型,和自己手动选择模型位置,这让我感觉有点点没有控制感,但在他们的工作流示例中已经实现了图生图的功能, 安装后在对应文件夹你应该可以找到一个 sample-workflow 的文件夹 或者访问sample-workflow 来获取。 下面的图片也已经包含了对应工作流,如果你测试成功了,可以在评论中告诉我应该怎么做。:)
文生图工作流
图生图工作流
Qwen-Image ComfyUI 原生、GGUF、Nunchaku 工作流完整使用指南
Qwen-Image 是由阿里巴巴通义千问团队开发的图像生成基础模型,采用 20B 参数的 MMDiT(多模态扩散变换器)架构,以 Apache 2.0 许可证形式开源发布。该模型在图像生成领域展现出独特的技术优势,特别是在文本渲染和图像编辑方面表现突出。
核心特性:
- 多语言文本渲染能力:模型能够准确生成包含英语、中文、韩语、日语等多种语言的图像,文本清晰可读且与图像风格协调
- 丰富的艺术风格支持:从写实风格到艺术创作,从动漫风格到现代设计,模型能够根据提示词灵活切换不同的视觉风格
- 精确的图像编辑功能:支持对现有图像进行局部修改、风格转换、内容添加等操作,保持整体视觉一致性
相关资源:
Qwen-Image ComfyUI 原生工作流指南
在本篇文档所附工作流中使用的不同模型有三种
- Qwen-Image 原版模型 fp8_e4m3fn
- 8步加速版: Qwen-Image 原版模型 fp8_e4m3fn 使用 lightx2v 8步 LoRA,
- 蒸馏版:Qwen-Image 蒸馏版模型 fp8_e4m3fn
显存使用参考 GPU: RTX4090D 24GB
| 使用模型 | VRAM Usage | 首次生成 | 第二次生成 |
|---|---|---|---|
| fp8_e4m3fn | 86% | ≈ 94s | ≈ 71s |
| fp8_e4m3fn 使用 lightx2v 8步 LoRA | 86% | ≈ 55s | ≈ 34s |
| 蒸馏版 fp8_e4m3fn | 86% | ≈ 69s | ≈ 36s |
1. 工作流文件
更新 ComfyUI 后你可以从模板中找到工作流文件,或者将下面的工作流拖入 ComfyUI 中加载

蒸馏版
2. 模型下载
你可以在 ComfyOrg 仓库找到的版本
- Qwen-Image_bf16 (40.9 GB)
- Qwen-Image_fp8 (20.4 GB)
- 蒸馏版本 (非官方,仅需 15 步)
所有模型均可在 Huggingface 或者 魔搭 找到
Diffusion model
Qwen_image_distill
LoRA
Text encoder
VAE
模型保存位置
3. 按步骤完成工作流
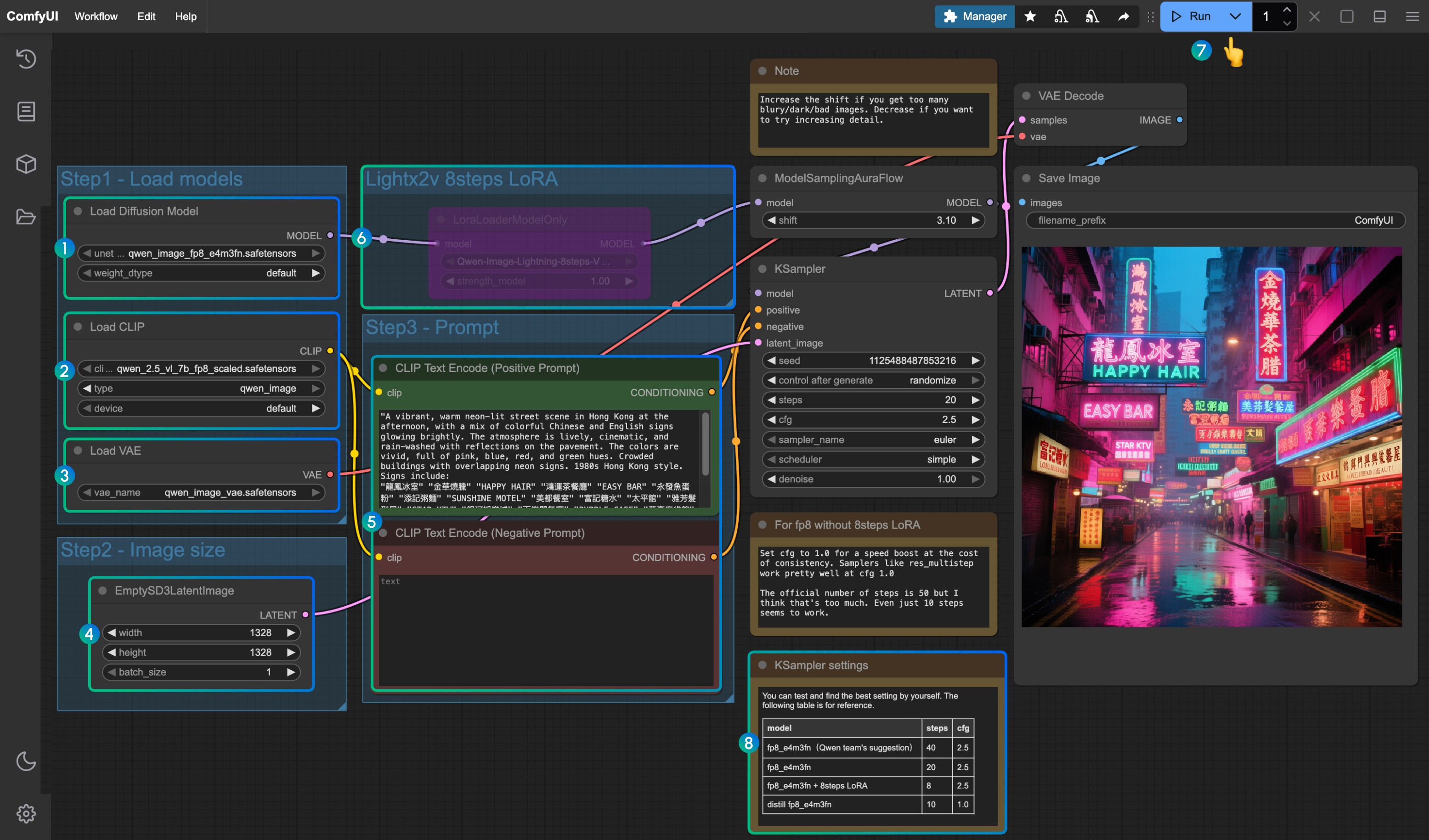
- 确保
Load Diffusion Model节点加载了qwen_image_fp8_e4m3fn.safetensors - 确保
Load CLIP节点中加载了qwen_2.5_vl_7b_fp8_scaled.safetensors - 确保
Load VAE节点中加载了qwen_image_vae.safetensors - 确保
EmptySD3LatentImage节点中设置好了图片的尺寸 - 在
CLIP Text Encoder节点中设置好提示词,目前经过测试目前至少支持:英语、中文、韩语、日语、意大利语等 - 如果需要启用 lightx2v 的 8 步加速 LoRA ,请选中后用
Ctrl + B启用该节点,并按 序号8处的设置参数修改 Ksampler 的设置设置 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流 - 对于不同版本的模型和工作流的对应 KSampler 的参数设置
蒸馏版模型和 lightx2v 的 8 步加速 LoRA 似乎不能同时使用,你可以测试具体的组合参数来验证组合使用的方式是否可行
Qwen-Image GGUF 版 ComfyUI 工作流
GGUF 版本对低显存用户来说比较友好,在某些权重情况下你只需要 8GB 左右的显存即可运行 Qwen-Image
显存使用情况参考:
| Workflow | VRAM Usage | 首次生成 | 后续生成 |
|---|---|---|---|
| qwen-image-Q4_K_S.gguf | 56% | ≈ 135s | ≈ 77s |
| With 8steps LoRA | 56% | ≈ 100s | ≈ 45s |
模型地址:Qwen-Image-gguf
1. 更新或者安装自定义节点
使用 GGUF 版本需要你安装或者 更新 ComfyUI-GGUF 这个插件
具体请参考如何安装 ComfyUI 自定义节点,或者通过 Manager 搜索安装即可
2. 工作流下载

3. 模型下载
GGUF 版本使用的模型仅有 diffusion 模型与其它的不同
请访问 https://huggingface.co/city96/Qwen-Image-gguf 下载任意一个权重,通常文件体积越大质量越好,同时也要求更高的显存,在本篇教程中我将使用下面的版本
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── qwen-image-Q4_K_S.gguf # 或者其它你选择的版本3. 按步骤完成工作流
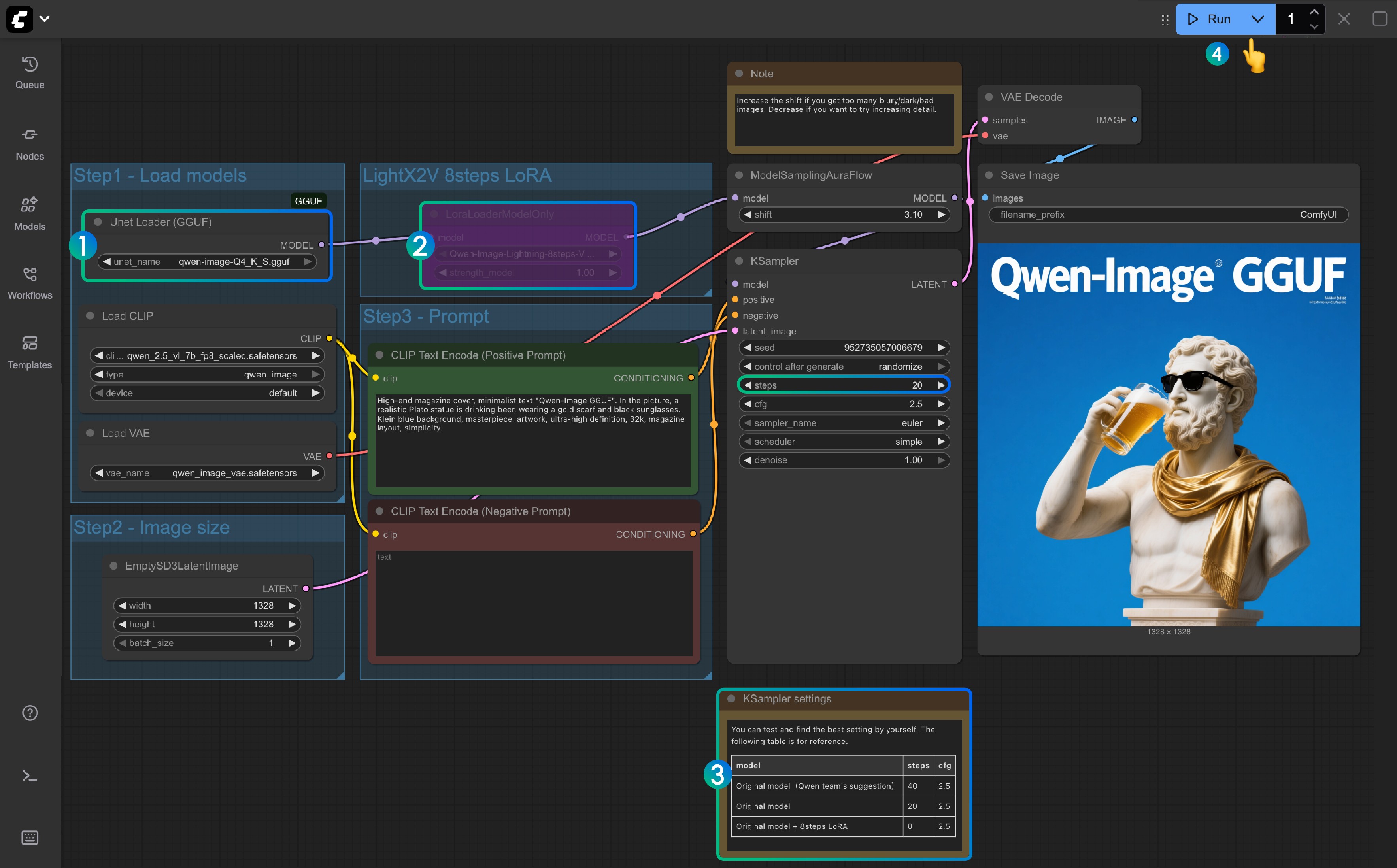
- 确保
Unet Loader(GGUF)节点中加载了qwen-image-Q4_K_S.gguf或者其它你下载的版本- 请确保 ComfyUI-GGUF 已经安装并更新
- 对于
LightX2V 8Steps LoRA默认并未启用,你可以选中后使用 Ctrl+B 启用该节点 - 如果未启用 8 步 LoRA 时,对应的步数默认为 20 , 如果你启用了 8 步 LoRA 请把它设置为 8
- 这里是对应设置步数的参考
- 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
Qwen-Image Nunchaku 版工作流
模型地址:nunchaku-qwen-image 自定义节点地址:https://github.com/nunchaku-tech/ComfyUI-nunchaku
待支持 Nunchaku 支持
Qwen Image ControlNet
Qwen Image ControlNet DiffSynth-ControlNets Model Patches 工作流
这个模型实际上并不是一个 controlnet,而是一个 Model patch, 支持 canny、depth、inpaint 三种不同的控制模式
原始模型地址:DiffSynth-Studio/Qwen-Image ControlNet Comfy Org rehost 地址: Qwen-Image-DiffSynth-ControlNets/model_patches
1. 工作流及输入图片
下载下面的图片拖入 ComfyUI 中以加载对应的工作流

下载下面的图片作为输入图片:

2. 模型链接
其它模型与 Qwen-Image 基础工作流一致,你只需下载下面的模型并保存到 ComfyUI/models/model_patches 文件夹中
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. 工作流使用说明
目前 diffsynth 有三个 patch 的模型: Canny、Detph、Inpaint 三个模型
如果你是第一次使用 ControlNet 相关的工作流,你需要了解的是,用于控制的图片需要预处理成受支持的图像才可以被模型使用和识别

- Canny: 处理后的 canny , 线稿轮廓
- Detph: 预处理后的深度图,体现空间关系
- Inpaint: 需要用 Mask 标记需要重绘的部分
由于这个 patch 模型分为了三个不同的模型,所以你需要在输入时选择正确的预处理类型来保证图像的正确预处理
Canny 模型 ControlNet 使用说明
- 确保对应
qwen_image_canny_diffsynth_controlnet.safetensors已被加载 - 上传输入图片,用于后续处理
- Canny 节点是原生的预处理节点,它将按照你设置的参数,将输入图像进行预处理,控制生成
- 如果需要可以修改
QwenImageDiffsynthControlnet节点的strength强度来控制线稿控制的强度 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
对于 qwen_image_depth_diffsynth_controlnet.safetensors 使用,需要将图像预处理成 detph 深度图,替换掉
image proccessing图,对于这部分的使用,请参考本篇文档中 InstantX 的处理方法,其它部分与 Canny 模型的使用类似
Inpaint 模型 ControlNet 使用说明
对于 Inpaint 模型,它需要使用 蒙版编辑器,来绘制一个蒙版然后作为输入控制条件
- 确保
ModelPatchLoader加载的是qwen_image_inpaint_diffsynth_controlnet.safetensors模型 - 上传图片,并使用蒙版编辑器 绘制蒙版,你需要将对应
Load Image节点的mask输出连接到QwenImageDiffsynthControlnet的mask输入才能保证对应的蒙版被加载 - 使用
Ctrl-B快捷键,将原本工作流中的 Canny 设置为绕过模式,来使得对应的 Canny 节点处理不生效 - 在
CLIP Text Encoder输入你需要将蒙版部分修改成样式 - 如需要可以修改
QwenImageDiffsynthControlnet节点的strength强度来控制对应的控制强度 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
Qwen Image union ControlNet LoRA 工作流
原始模型地址:DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Comfy Org reshot 地址: qwen_image_union_diffsynth_lora.safetensors: 图像结构控制lora 支持 canny、depth、post、lineart、softedge、normal、openpose
1. 工作流及输入图片
下载下面的图片并拖入 ComfyUI 以加载工作流

下载下面的图片作为输入图片

2. 模型链接
下载下面的模型,由于这是一个 LoRA 模型,所以需要保存到 ComfyUI/models/loras/ 文件夹下
- qwen_image_union_diffsynth_lora.safetensors: 图像结构控制lora 支持 canny、depth、post、lineart、softedge、normal、openpose
3. 工作流说明
这个模型是一个统一的控制 LoRA, 支持 canny、depth、pose、lineart、softedge、normal、openpose 等控制, 由于许多的图像预处理原生节点并未完全支持,所以你应该需要类似 comfyui_controlnet_aux 来完成其它图像的预处理
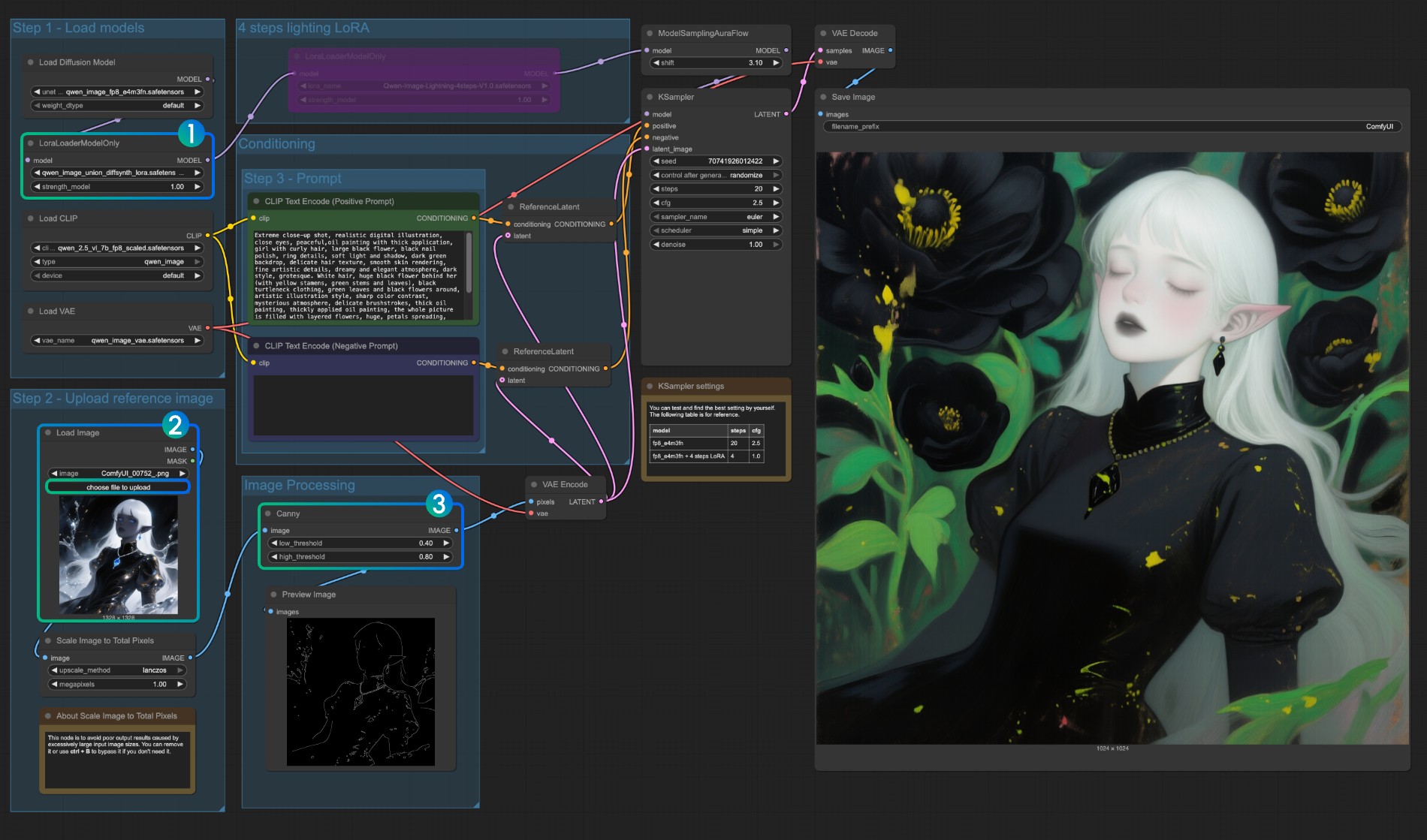
- 确保
LoraLoaderModelOnly正确加载了qwen_image_union_diffsynth_lora.safetensors模型 - 上传输入图像
- 如需要你可以调整
Canny节点的参数,由于不同的输入图像需要不同的参数设置来获得更好的图像预处理结果,你可以尝试调整对应的参数值来获得更多/更少细节 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
其它类型的类型的控制,也是需要将图像处理的部分替换
Qwen-Image-2512 ComfyUI 原生工作流使用指南
Qwen-Image-2512 是阿里巴巴通义千问团队在 2024 年 12 月发布的 Qwen-Image 模型更新版本。相比 8 月发布的基础版本,新版本在图像生成质量方面进行了多项改进。
主要改进内容:
- 人物真实感提升:生成的人物图像看起来更真实自然,减少了明显的 AI 生成痕迹
- 自然细节更丰富:在风景、动物毛发等自然元素的细节表现更加细腻
- 文字渲染优化:生成图像中的文字更加清晰准确,文字与图像的组合也更加协调
相关资源:
Qwen-Image-2512 ComfyUI 原生工作流指南
工作流中包含两个子图:
- Text to Image (Qwen-Image 2512):标准的 50 步生成流程
- Text to Image (Qwen-Image 2512 4steps):使用 Lightning LoRA 实现的 4 步快速生成
1. 工作流文件
更新 ComfyUI 后,你可以从模板中找到工作流文件,或者将下面的工作流文件拖入 ComfyUI 中加载。
2. 模型下载
所有模型文件均可在 Hugging Face 或 ModelScope 找到。
文本编码器 (Text Encoders)
LoRA 模型(可选 - 用于 4 步加速)
如果你想要更快的生成速度,可以使用 Lightning LoRA 将生成步数从 50 步减少到 4 步:
扩散模型 (Diffusion Models)
你可以根据需要选择以下两种模型之一:
- qwen_image_2512_fp8_e4m3fn.safetensors (推荐,适合大多数用户使用)
- qwen_image_2512_bf16.safetensors (如果你有足够的显存且想要更好的图像质量,可以选择此版本)
VAE 模型
3. 模型文件存放位置
下载完成后,请将模型文件按照以下目录结构放置:
4. 支持的图像尺寸比例
Qwen-Image-2512 支持多种图像宽高比,你可以根据需求选择合适的尺寸:
| 宽高比 | 分辨率 |
|---|---|
| 1:1 | 1328×1328 |
| 16:9 | 1664×928 |
| 9:16 | 928×1664 |
| 4:3 | 1472×1104 |
| 3:4 | 1104×1472 |
| 3:2 | 1584×1056 |
| 2:3 | 1056×1584 |
Qwen-Image-Layered ComfyUI 工作流使用指南
Qwen-Image-Layered 是由阿里巴巴通义千问团队开发的图像分层编辑生成模型,基于 Qwen-Image 模型进行开发,采用 Apache 2.0 开源许可证。该模型可以将图像分解为多个 RGBA 图层,每个图层可以独立进行编辑操作,而不会影响图像中的其他内容。这种物理隔离的方式使得图像编辑更加精确和一致。
与传统的图像编辑方式不同,Qwen-Image-Layered 通过将图像分解为多个独立的 RGBA 图层,实现了真正的图层化编辑体验。每个图层都包含完整的颜色信息和透明度信息,使得图层之间的合成更加自然。这种设计使得用户可以对图像中的不同部分进行精确控制,而无需担心编辑操作会影响到其他区域。

核心特性:
- 图层分解能力:可以将图像分解成多个独立的 RGBA 图层,每个图层包含特定的语义或结构组件,比如前景物体、背景元素、文字等
- 独立图层编辑:支持对每个图层进行重新着色、内容替换、文字修改、删除对象、调整大小和移动位置等操作,所有操作只影响目标图层
- 灵活的图层数量:不限制固定的图层数量,可以根据需要将图像分解为不同数量的图层(例如 3 个、4 个、8 个或更多)
- 递归分解:支持递归分解功能,任何一个图层都可以进一步分解为更多的子图层,为复杂的编辑需求提供了更大的灵活性

Qwen-Image-Layered ComfyUI 原生工作流指南
Qwen-Image-Layered 已经在 ComfyUI 中获得原生支持,用户可以直接在 ComfyUI 中使用该模型进行图像分层编辑。无需安装额外的自定义节点,只需更新到最新版本的 ComfyUI 即可使用。
1. 工作流文件
更新 ComfyUI 后你可以从模板中找到工作流文件,或者将下面的工作流拖入 ComfyUI 中加载
2. 模型下载
所有模型均可在 Huggingface 或者 魔搭 找到
text_encoders
diffusion_models
vae
模型保存位置
3. FP8 版本
默认情况下我们使用的是 bf16 版本,该版本需要较高的显存。如果你的显存有限,可以使用 fp8 版本来降低显存占用:
使用 fp8 版本时,需要在工作流中的 子图 内的 Load Diffusion model 节点中更新模型路径,将其指向 fp8 版本的模型文件。
fp8 版本可以在保持较好生成质量的同时显著降低显存占用,适合显存较小的用户使用。
4. 工作流设置
采样器设置
该模型的生成速度相对较慢,运行时间较长。原始采样设置建议为步数 50 步,CFG 值为 4.0,这会使生成时间至少增加一倍。如果你需要更快的生成速度,可以适当降低步数,但可能会影响生成质量。建议在首次使用时保持默认设置,以获得最佳的生成效果。
输入尺寸
对于输入尺寸,640 像素是推荐值,这个尺寸在生成质量和速度之间取得了良好的平衡。如果需要高分辨率输出,可以使用 1024 像素,但需要注意,太大的尺寸会导致生成时间显著增加,同时也会占用更多的显存。建议根据你的硬件配置和实际需求来选择合适的尺寸。
提示词(可选)
文本提示词用于描述输入图像的整体内容,包括可能被部分遮挡的元素(例如,你可以指定被前景对象遮挡的文字)。提示词并不是用来明确控制单个图层的语义内容,而是帮助模型理解图像的整体结构。
Qwen-Image-Layered GGUF 版本工作流
GGUF 版本工作流待更新,敬请期待。
相关链接
ComfyUI LBM Relighting workflow - 快速图像重新打光技术逐步完整教程
LBM Relighting 简介
LBM (Latent Bridge Matching) 是一种基于深度学习的图像重新打光技术,由 Jasper AI 团队开发并在论文 LBM: Latent Bridge Matching for Fast Image-to-Image Translation 中首次提出。这项技术专门解决了计算机视觉领域中一个长期存在的挑战:如何让前景对象的光照效果与新的背景环境自然融合。

技术背景与创新
传统的图像合成往往面临光照不一致的问题。当我们将一个对象从一个场景移动到另一个场景时,原始的光照条件通常与新环境不匹配,导致合成结果看起来不自然。LBM 技术通过以下创新解决了这个问题:
- 潜在空间桥接匹配:在潜在空间中进行桥接匹配,实现高效的图像到图像转换
- 环境感知光照:能够理解背景环境的光照特征,并将其应用到前景对象上
- 快速推理:相比传统方法,LBM 只需要极少的推理步骤就能产生高质量结果
- 保持细节:在改变光照的同时,完美保持对象的原始细节和纹理
你可以通过以下在线演示体验 LBM Relighting 的效果: https://huggingface.co/spaces/jasperai/LBM_relighting
ComfyUI LBM Relighting 工作流逐步教程
1. LBM Relighting 工作流及素材下载
下载下面的图片并拖入 ComfyUI 中以加载对应的工作流,工作流中已包含对应的模型信息,如果有弹窗提示点击下载即可,或者参照工作流中的模型下载信息手动下载模型。

JSON 格式工作流下载
下载下面的图片作为输入图片:


2. 手动模型下载
请下载 model.safetensors 文件重命名为 LBM_relighting.safetensors ,并保存到 ComfyUI/models/diffusion_models/ 文件夹中
3. 安装必需的自定义节点
为了在 ComfyUI 中使用 LBM Relighting,您需要安装以下自定义节点,可以使用 ComfyUI Manager 的缺失节点功能来安装,或者参考ComfyUI 自定义节点安装教程手动安装。
主要节点
- ComfyUI-LBMWrapper - LBM 模型的核心包装器
辅助节点
- ComfyUI-KJNodes - 提供额外的图像处理比如尺寸调整等
- ComfyUI_essentials - 背景移除节点
- (可选)rgthree-comfy - Compare 节点提供前后对比功能
4. 参考步骤引导完成工作流运行
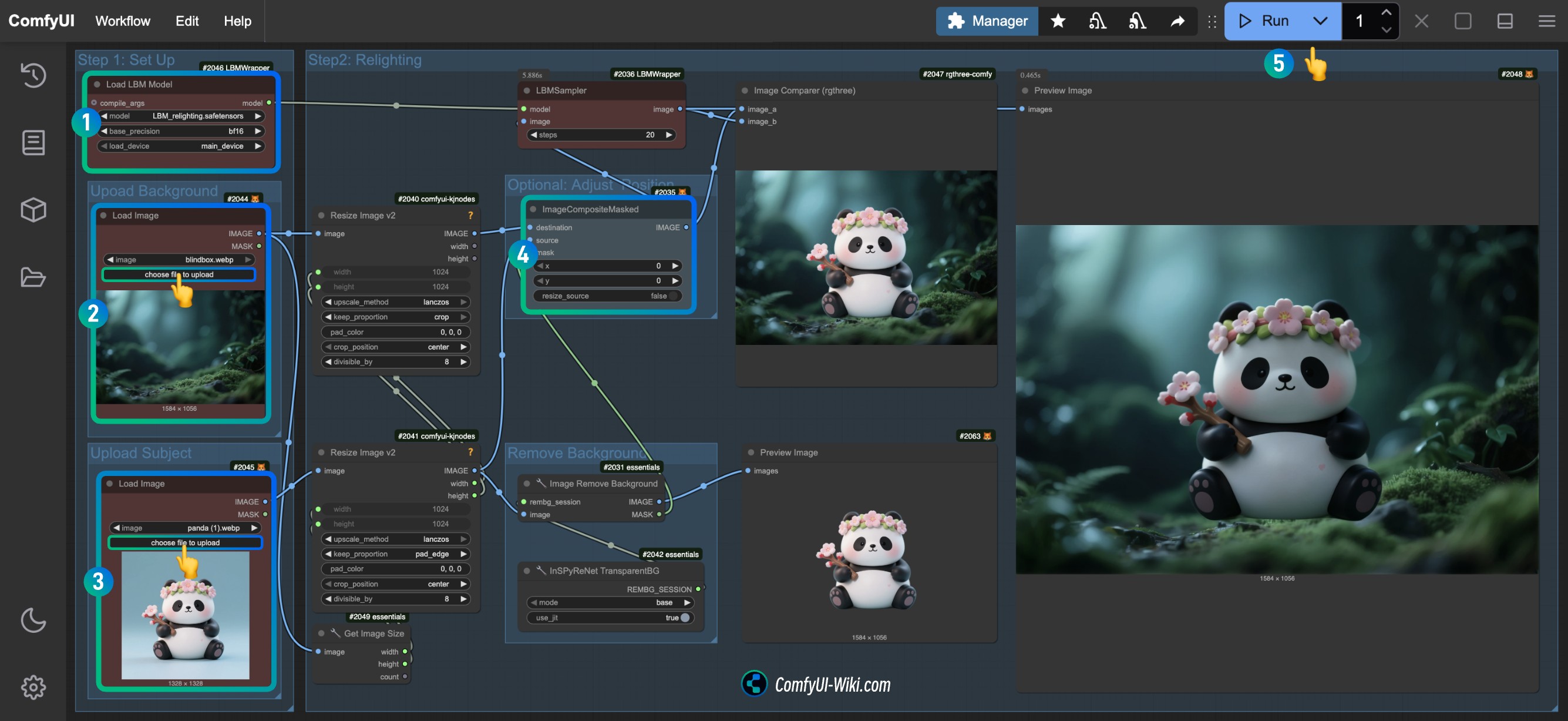
- 确保
Load LBM Model节点加载了重命名后的LBM_relighting.safetensors模型 - 在 Upload Background 组中的
Load Image节点上传背景图 - 在 Upload Subject 组中的
Load Image节点上传主体图 - (可选)在
ImageCompositeMasked节点中对应的 XY 位置来调整对应的合成位置 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片生成 - 该工作流没有使用
Save Image你可以在Preview Image节点中查看结果,并在Image Compareer(rgthree)节点中查看对比效果
5. 工作流补充说明
- 这个工作流基于原始自定义节点提供的工作流稍微做了些许调整,主要是将主体图片缩放然后调整成适合背景图的尺寸
- 你可以修改
Get Image Size节点的 Image 输入为 Subject 节点,这样可以让背景调整成为主体的图像尺寸 - 如果需要调整图像组合的位置可以修改
ImageCompositeMasked节点中的 XY 位置来调整对应的合成位置 - 如果需要调整主体大小的尺寸可以取消掉尺寸输入上的关联,而单独调整 Resize Image
节点中的Width和Height` 从而来达到调整图像尺寸的目的 - 可以在工作流之后再添加 Refine 的工作流,从而修复图像的细节
其它 LBM Relighting 相关链接
ComfyUI Frame Pack 工作流完整逐步教程
FramePack 是由斯坦福大学博士、ControlNet 作者张吕敏(Lvmin Zhang)团队开发的一项 AI 视频生成技术。其主要特点包括:
- 动态上下文压缩:通过对视频帧按重要性进行分级压缩,关键帧保留 1536 个特征标记,过渡帧精简至 192 个。
- 抗漂移采样:采用双向记忆法和倒序生成术,避免画面漂移,确保动作连贯性。
- 显存需求降低:将视频生成所需的显存门槛从专业级硬件(12GB+)降至消费级水平(仅需 6GB 显存),使普通用户使用 RTX 3060 笔记本即可生成长达 60 秒的高质量视频。
- 开源与集成:目前 FramePack 已开源并集成至腾讯混元视频模型,支持多模态输入(文字+图像+语音)和实时交互生成。
Frame Pack 相关原始链接
- 原始仓库:https://github.com/lllyasviel/FramePack/
- 在 Windows上 无需 ComfyUI 的一键运行整合包:https://github.com/lllyasviel/FramePack/releases/tag/windows
对应提示词
lllyasviel 在对应仓库提供了一段用于视频生成的 GPT 提示词,如果你在使用 frame pack 工作流时不知道怎么写提示词,可以试试。
- 复制下面的提示词,发送给 GPT
- 等 GPT 了解要求后把对应图片提供给它,你就会得到对应的提示词。
目前 Frame Pack 在 ComfyUI 中的实现
目前有三个自定义节点作者在 ComfyUI 中实现了 Frame Pack 的能力
- Kijai: ComfyUI-FramePackWrapper
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
这些自定义节点的差别
下面我们说明下这几个自定义节点实现的工作流的差异所在。
Kijai 的自定义插件
Kijai 使用了重新打包了对应的模型,我想你肯定已经用过 Kijai 的相关自定义节点了,感谢他每次都带来如此迅速的更新!
其中 Kijai 的版本似乎没有在 ComfyUI Manager 中注册,所以目前无法通过 Manager 的 Custom nodes Manager 来进行安装,你需要通过 Manager 的 Git 或者手动安装。
特点:
- 支持首尾帧视频生成
- 需要通过 Git 安装或者手动安装
- 模型重新可复用
HM-RunningHub 与 汤圆猪(TTPlanetPig) 的自定义插件
这两个自定义节点是源于相同代码的修改版本,原始版本由 HM-RunningHub 创建,然后 汤圆猪(TTPlanetPig) 实现了 FramePack 的首尾帧视频生成,并基于对应插件源码做了修改,你可以看这个 PR
这两个自定义节点使用的模型文件夹结构是一致的,都是未重新打包过的原始仓库模型文件,所以你这些模型文件,在其它不支持这个文件夹结构的的自定义节点中,会无法使用到这些模型,导致磁盘空间占用较大
特点:
- 支持首尾帧视频生成
- 下载的模型文件你可能无法在其它节点或者工作流中复用
- 对磁盘空间占用较大,因为使用的模型文件都是没有重新打包的
- 有些依赖的兼容性问题
Kijai ComfyUI-FramePackWrapper 首尾帧视频生成实现 ComfyUI 工作流
1. 插件安装
对于 ComfyUI-FramePackWrapper 你可能需要使用 Manager 的 Git 安装:
下面是你可能用到的文章:
- 如何安装自定义节点
- “This action is not allowed with this security level configuration” 问题解决
2. 工作流文件下载
下载下面的视频文件,并拖入 ComfyUI 中加载对应的工作流, 我已经在文件中添加了对应模型信息,会提示你进行模型下载
由于 ComfyUI 前端最近的更新,请确保前端是 1.16.9 之后的版本,不然这个工作流加载后可能会出现 widget 丢失的情况。 详情请访问: ComfyUI 工作流导入后,widget 消失了无法设置或者调整输入
视频预览
下载下面的图片,我们将用作图片输入


3. 手动模型安装
如果你无法顺利下载工作流中的模型,请下载下面的模型,并保存到对应位置
CLIP Vision
VAE
Text Encoder
Diffusion Model Kijai 提供了两个精度的版本,你选择一个下载就好了,你可以根据你的显卡性能选择对应的版本
| 文件名 | 精度 | 体积 | 下载链接 | 显卡性能要求 |
|---|---|---|---|---|
| FramePackI2V_HY_bf16.safetensors | bf16 | 25.7GB | 下载链接 | 高 |
| FramePackI2V_HY_fp8_e4m3fn.safetensors | fp8 | 16.3GB | 下载链接 | 低 |
文件保存位置
📂 ComfyUI/
├──📂 models/
│ ├──📂 diffusion_models/
│ │ └── FramePackI2V_HY_fp8_e4m3fn.safetensors # 或者 bf16 精度
│ ├──📂 text_encoders/
│ │ ├─── clip_l.safetensors
│ │ └─── llava_llama3_fp16.safetensors
│ ├──📂 clip_vision/
│ │ └── sigclip_vision_patch14_384.safetensors
│ └──📂 vae/
│ └── hunyuan_video_vae_bf16.safetensors4. 按步骤完成对应工作流的运行
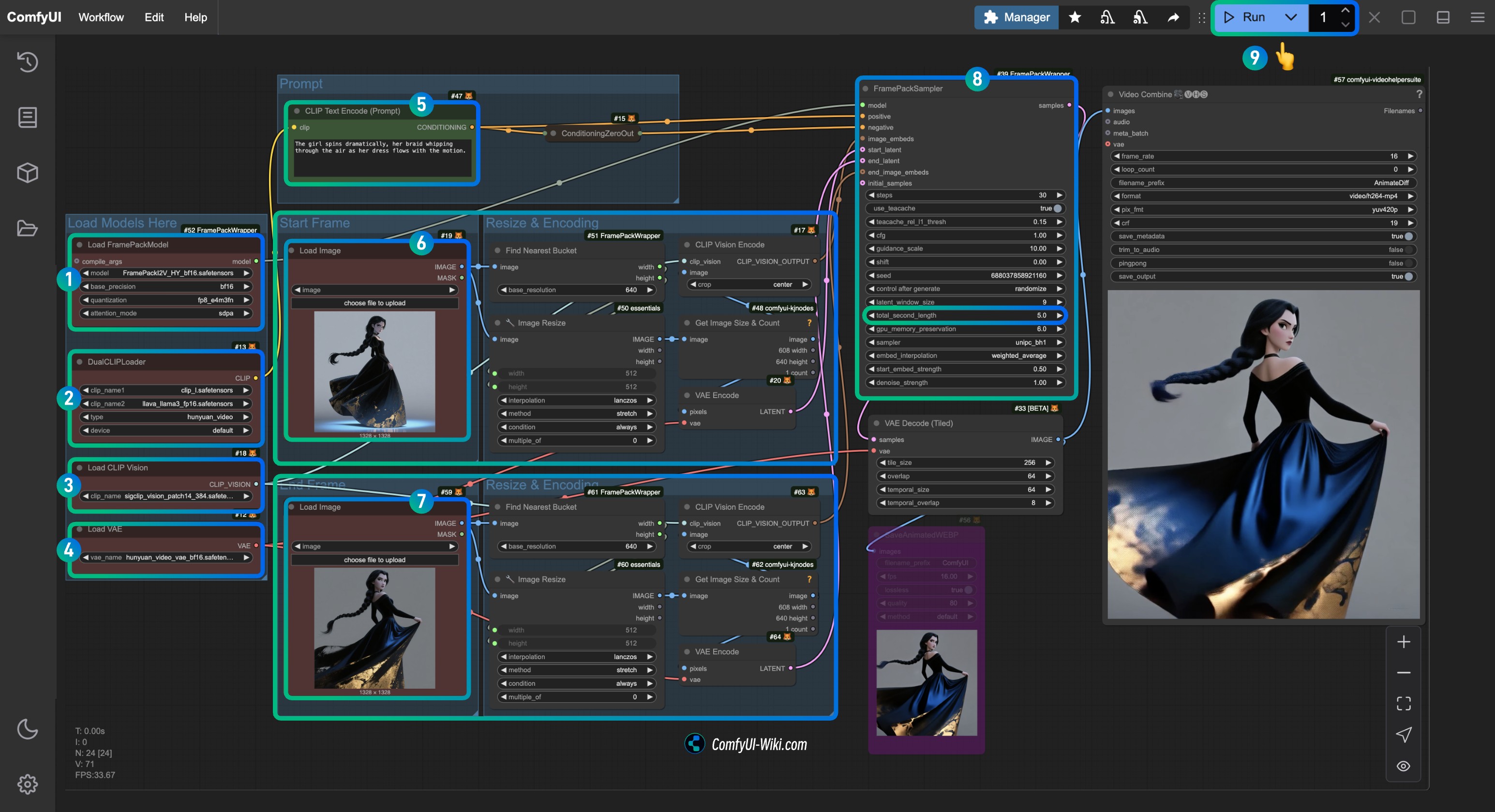
- 确保
Load FramePackModel节点加载了FramePackI2V_HY_fp8_e4m3fn.safetensors模型 - 确保
DualCLIPLoader节点加载了:clip_l.safetensors模型llava_llama3_fp16.safetensors模型
- 确保
Load CLIP Vision节点加载了sigclip_vision_patch14_384.safetensors模型 - 可以在
Load VAE节点加载了hunyuan_video_vae_bf16.safetensors模型 - (可选,如果使用我的 input 图片)修改
CLIP Text Encoder节点中的Prompt参数,输入你想要生成的视频描述内容 - 在
Load Image节点中加载first_frame.jpg这整个区域都是first_frame的输入处理相关的节点 - 在
Load Image节点中加载last_frame.jpg这整个区域都是last_frame的输入处理相关的节点(如果你不需要尾帧,可以删除或者使用 ByPass 来禁用) - 在
FramePackSampler节点中,可以修改total_second_length参数,来修改视频的时长,我的工作流中是5秒,你可以根据你的需求修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
如果不需要尾帧,请绕过(Bypass)整个 last_frame 的输入处理相关节点
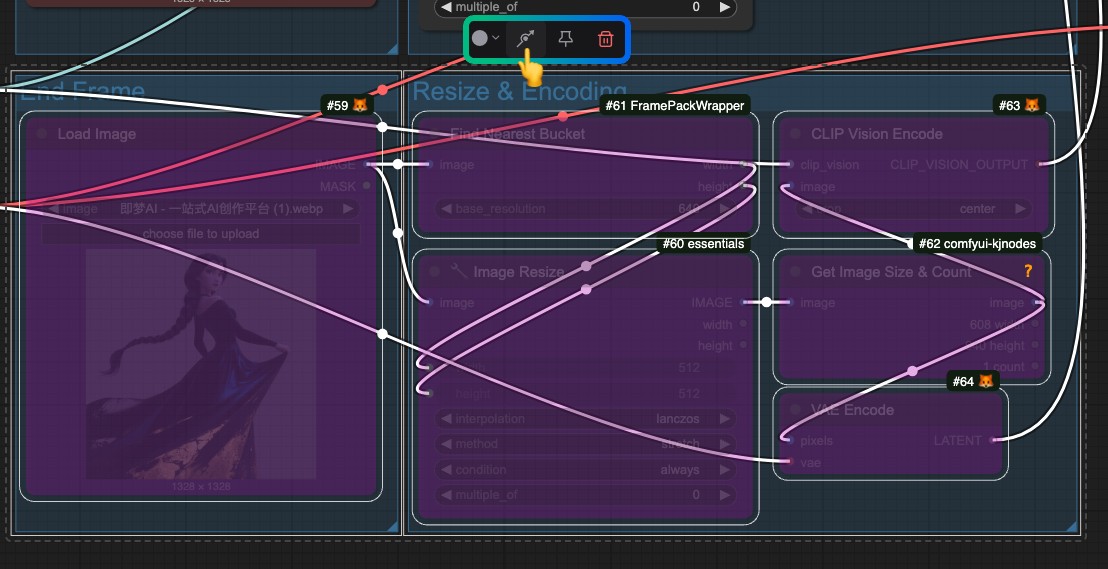
HM-RunningHub 与 汤圆猪(TTPlanetPig) 的自定义插件
这两个插件使用的模型存储位置是一致的,但是和我开头所说,他们使用模型的方式就是下载原始的整个仓库,需要保存到指定位置,这导致其它的插件并没有办法复用这些模型会造成一定硬盘空间浪费,不过实现了首尾帧生成,如果你想要体验可以尝试一下。
插件安装
- 下面二选一或者都安装,节点有所差异,但都是只有一个节点,使用起来也很简单
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
- 提升 ComfyUI 中视频编辑体验能力
如果你有使用过视频相关工作流 VideoHelperSuite 在目前扩展 ComfyUI 视频能力上还是非常关键的。
1. 模型下载
HM-RunningHub 提供了一个 python 脚本用来下载所有的模型,你只需要使用运行这个脚本,然后按照提示操作即可。
我的操作是,把下面的代码保存为 download_models.py 文件并保存到ComfyUI/models 的根目录下,然后在对应目录中使用终端运行 python download_models.py 运行这个脚本。
cd <你的安装路径>/ComfyUI/models/然后
python download_models.py当然这需要你的python独立环境 / 系统环境有安装了 huggingface_hub 这个包
from huggingface_hub import snapshot_download
# Download HunyuanVideo model
snapshot_download(
repo_id="hunyuanvideo-community/HunyuanVideo",
local_dir="HunyuanVideo",
ignore_patterns=["transformer/*", "*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download flux_redux_bfl model
snapshot_download(
repo_id="lllyasviel/flux_redux_bfl",
local_dir="flux_redux_bfl",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download FramePackI2V_HY model
snapshot_download(
repo_id="lllyasviel/FramePackI2V_HY",
local_dir="FramePackI2V_HY",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
当然你也可以使用手动下载的方式,下载下面的模型,并保存到对应位置,也就是下载对应仓库的所有文件
- HunyuanVideo: HuggingFace Link
- Flux Redux BFL: HuggingFace Link
- FramePackI2V: HuggingFace Link
文件保存结构
comfyui/models/
flux_redux_bfl
├── feature_extractor
│ └── preprocessor_config.json
├── image_embedder
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── image_encoder
│ ├── config.json
│ └── model.safetensors
├── model_index.json
└── README.md
FramePackI2V_HY
├── config.json
├── diffusion_pytorch_model-00001-of-00003.safetensors
├── diffusion_pytorch_model-00002-of-00003.safetensors
├── diffusion_pytorch_model-00003-of-00003.safetensors
├── diffusion_pytorch_model.safetensors.index.json
└── README.md
HunyuanVideo
├── config.json
├── model_index.json
├── README.md
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ ├── model-00001-of-00004.safetensors
│ ├── model-00002-of-00004.safetensors
│ ├── model-00003-of-00004.safetensors
│ ├── model-00004-of-00004.safetensors
│ └── model.safetensors.index.json
├── text_encoder_2
│ ├── config.json
│ └── model.safetensors
├── tokenizer
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── tokenizer.json
├── tokenizer_2
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
└── vae
├── config.json
└── diffusion_pytorch_model.safetensors2. 工作流下载
HM-RunningHub
汤圆猪(TTPlanetPig)

通义 Wan2.1 ComfyUI 工作流
阿里巴巴于2025年2月开源的Wan2.1是当前视频生成领域的标杆性模型,其开源协议为Apache 2.0,提供14B(140亿参数)和1.3B(13亿参数)两个版本,覆盖文生视频(T2V)、图生视频(I2V)等多项任务。 该模型不仅在性能上超越现有开源模型,更重要的是其轻量级版本仅需 8GB 显存即可运行,大大降低了使用门槛。
另外目前已有社区作者制作了 GGUF 和量化版本
- GGUF: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
- 量化版本: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
本文将带领你完成对应的 Wan2.1 相关工作流包括:
- ComfyUI 原生支持的 Wan2.1 工作流
- 来自 Kijai 的版本
- 来自 City96 的 GGUF 版本
Wan2.1 ComfyUI 原生(native)工作流示例
以下工作流来自 ComfyUI 官方博客,目前 ComfyUI 已原生支持 Wan2.1,使用官方原生支持版本请升级你的 ComfyUI 到最新版本,请参考 如何升级 ComfyUI 部分指南完成升级。 ComfyUI Wiki 对原始的工作流进行了整理。
更新 ComfyUI 到最新版本之后 在 菜单栏 Workflows -> Workflow Templates 中可以看到 Wan2.1 的工作流模板
此版本的对应工作流文件全部来自于 Comfy-Org/Wan_2.1_ComfyUI_repackaged
其中 Diffusion models Comfy-org 提供了多个版本,如果本文中官方原生版本所用模型版本对硬件要求较高,你可以选择自己需要的版本来进行使用
- i2v 为 image to video 即 图生视频模型, t2v 为 text to video 即 文生视频模型
- 14B、1.3B 为对应的参数量,数值越大对硬件性能要求越高
- bf16、fp16、fp8 代表不同的精度,精度越高对硬件性能要求越高
- 其中bf16 可能需要Ampere 架构及以上的 GPU 支持
- fp16 受支持更广泛
- fp8 精度最低,对硬件性能要求最低,但效果相对也会较差
- 通常文件体积越大对设备的硬件要求也越高
1. Wan2.1 文生视频工作流
1.1 Wan2.1 文生视频工作流文件下载
下载下面的图片,并拖入 ComfyUI 或使用菜单栏 Workflows -> Open(Ctrl+O) 打开以加载工作流

Json 格式文件下载
1.2 手动模型安装
如果上面的工作流文件无法完成模型下载,请下载下面的模型文件,并保存到对应的位置。
从下面选择一个Diffusion models 模型文件进行下载,
- wan2.1_t2v_14B_bf16.safetensors
- wan2.1_t2v_14B_fp16.safetensors
- wan2.1_t2v_14B_fp8_e4m3fn.safetensors
- wan2.1_t2v_14B_fp8_scaled.safetensors
- wan2.1_t2v_1.3B_bf16.safetensors
- wan2.1_t2v_1.3B_fp16.safetensors
从Text encoders 选择一个版本进行下载,
VAE
文件保存位置
1.3 按流程完成工作流运行
- 确保
Load Diffusion Model节点加载了wan2.1_t2v_1.3B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 可以在
CLIP Text Encoder节点中输入你想要生成的视频描述内容 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
2. Wan2.1 图生视频工作流
2.1 Wan2.1 图生视频工作流 14B Workflow
工作流文件下载
请点击下面的按钮下载对应的工作流,然后拖入 ComfyUI 界面或者使用菜单栏 Workflows -> Open(Ctrl+O) 进行加载

Json 格式文件下载
这个版本的工作流和 480P 版本基本一致,只是使用的 diffusion model 不同,和 WanImageToVideo 节点的尺寸不同
下载下面的图片作为输入图片

2.2 手动模型下载
如果上面的工作流文件无法完成模型下载,请下载下面的模型文件,并保存到对应的位置
Diffusion models
720P 版本
- wan2.1_i2v_720p_14B_bf16.safetensors
- wan2.1_i2v_720p_14B_fp16.safetensors
- wan2.1_i2v_720p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_720p_14B_fp8_scaled.safetensors
480P 版本
- wan2.1_i2v_480p_14B_bf16.safetensors
- wan2.1_i2v_480p_14B_fp16.safetensors
- wan2.1_i2v_480p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_480p_14B_fp8_scaled.safetensors
Text encoders
VAE
CLIP Vision
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_i2v_480p_14B_fp16.safetensors # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 或者你选择的版本
│ └── vae/
│ │ └── wan_2.1_vae.safetensors
│ └── clip_vision/
│ └── clip_vision_h.safetensors 2.3 按流程完成 Wan2.1 480P 图生视频工作流
- 确保
Load Diffusion Model节点加载了wan2.1_i2v_480p_14B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中加载前面提供的输入图片 - 在
CLIP Text Encoder节点中输入你想要生成的视频描述内容,或者使用工作流中的示例 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Kijai Wan2.1 量化版本工作流
这个版本由 Kijai 提供,需要配合以下自定义节点使用
需要安装下面三个节点:
请在开始前使用 ComfyUI-Manager 或者参考ComfyUI 自定义节点安装教程完成对应这三个自定义节点的安装
模型仓库:Kijai/WanVideo_comfy
该仓库提供了多种不同版本的模型,请按照你的设备性能选择合适的模型,通常体积越大,效果越好,但同时对设备性能要求也越高。
如果 ComfyUI 原生工作流在你的设备上运行良好,你也可以使用Comfy Org 提供的模型,在示例中,我将使用 Kijai 提供模型来完成示例
1. Kijai 文生图工作流
1.1 Kijai Wan2.1 文生图工作流下载
请点击下面的按钮下载对应的工作流,请点击下面的按钮下载对应的工作流,然后拖入 ComfyUI 界面或者使用菜单栏 Workflows -> Open(Ctrl+O) 进行加载
以上两个工作流文件基本相同,2 号文件多了可选的备注信息
1.2 手动模型安装
访问: https://huggingface.co/Kijai/WanVideo_comfy/tree/main 查看文件体积大小,通常文件体积越大,效果越好,但同时对设备性能要求也越高
Diffusion models
- Wan2_1-T2V-14B_fp8_e4m3fn.safetensors
- Wan2_1-T2V-14B_fp8_e5m2.safetensors
- Wan2_1-T2V-1_3B_fp32.safetensors
- Wan2_1-T2V-1_3B_bf16.safetensors
- Wan2_1-T2V-1_3B_fp8_e4m3fn.safetensors
Text encoders模型
VAE模型
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-T2V-14B_fp8_e4m3fn.safetensors # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # 或者你选择的版本
│ └─── vae/
│ └── Wan2_1_VAE_bf16.safetensors1.3 按步骤完成工作流的运行
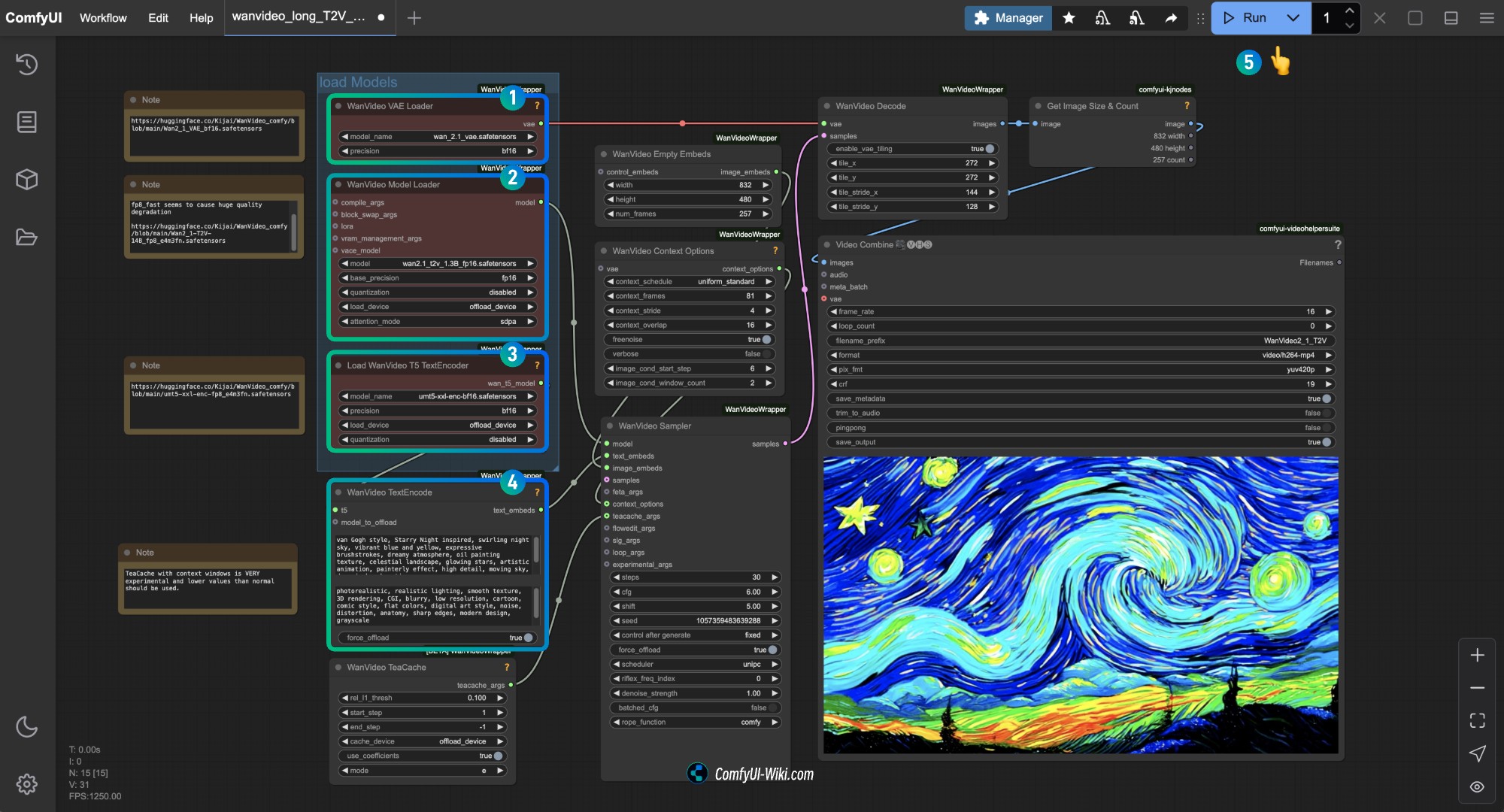
确保对应节点加载了对应模型,使用你下载的版本即可
- 确保
WanVideo Vae Loader节点加载了Wan2_1_VAE_bf16.safetensors模型 - 确保
WanVideo Model Loader节点加载了Wan2_1-T2V-14B_fp8_e4m3fn.safetensors模型 - 确保
Load WanVideo T5 TextEncoder节点加载了umt5-xxl-enc-bf16.safetensors模型 - 在
WanVideo TextEncode处输入你想要生成的视频画面提示词 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
可以修改 WanVideo Empty Embeds 中的尺寸来修改画面尺寸
2. Kiai Wan2.1 图生视频工作流
2.1 工作流文件下载
下载下面的图片我们将作输入图片

2.2 手动模型下载
使用 ComfyUI Native 部分的示例的模型也是可以的,似乎仅有 text_encoder 无法使用
Diffusion models 720P 版本
480P 版本
Text encoders模型
VAE模型
CLIP Vision
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # 或者你选择的版本
│ ├── vae/
│ │ └── Wan2_1_VAE_fp32.safetensors # 或者你选择的版本
│ └── clip_vision/
│ └── clip_vision_h.safetensors 2.3 按步骤完成工作流的运行
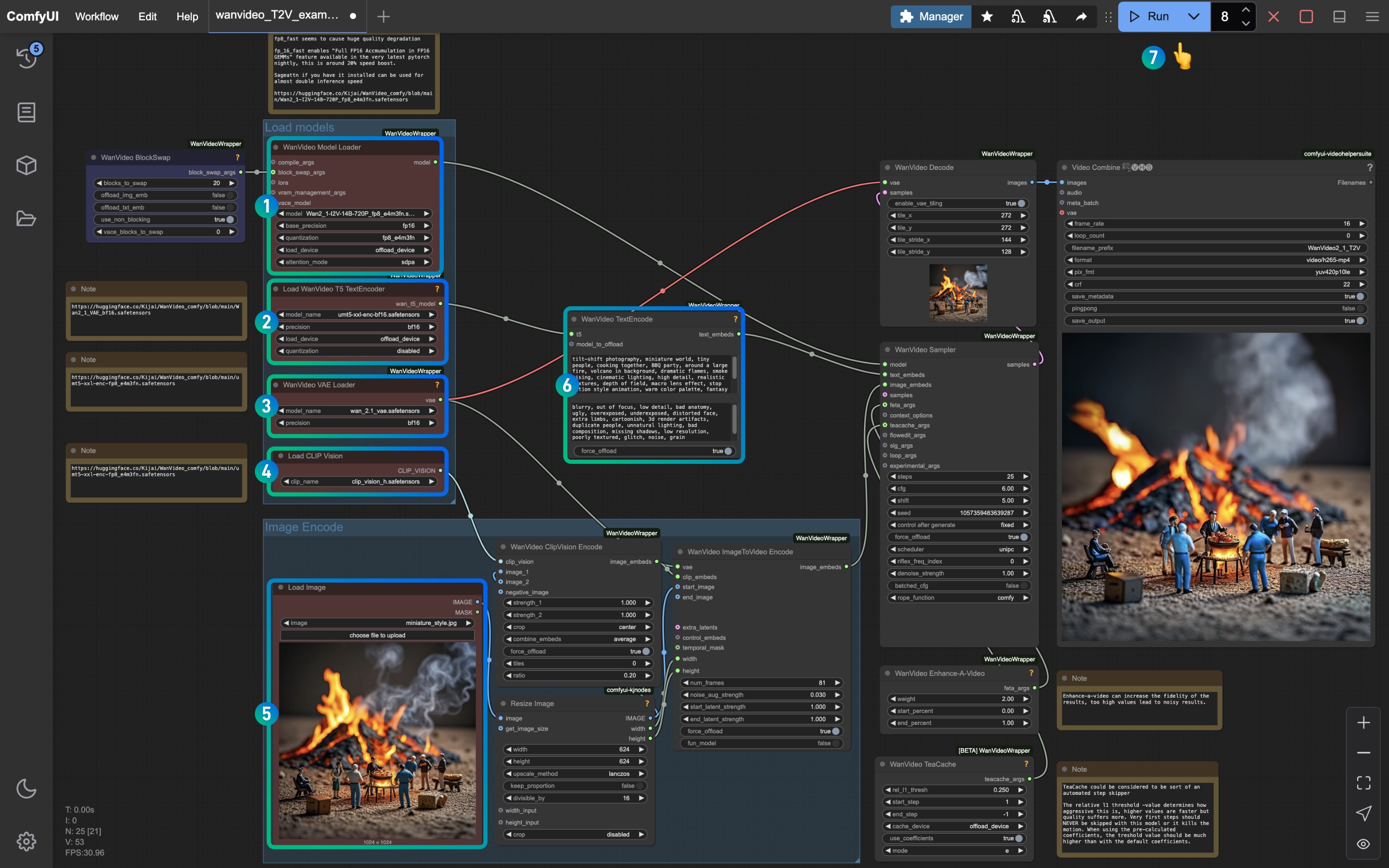
请参考图片序号,确保对应节点和模型均已加载来完成来确保模型能够正常运行
- 确保
WanVideo Model Loader节点加载了Wan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors模型 - 确保
Load WanVideo T5 TextEncoder节点加载了umt5-xxl-enc-bf16.safetensors模型 - 确保
WanVideo Vae Loader节点加载了Wan2_1_VAE_fp32.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中加载我们前面提供的输入图片 - 保存默认或者修改
WanVideo TextEncode提示词来调整画面效果 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Wan2.1 GGUF 版本工作流
这个部分我们将使用 GGUF 版本模型来完成视频生成 模型仓库:https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
我们需要 ComfyUI-GGUF 来加载对应模型,请在开始前使用 ComfyUI-Manager 或者参考ComfyUI 自定义节点安装教程完成对应自定义节点的安装
这个版本工作流基本与 ComfyUI Native 版本工作流一致,只不过我们使用了 GGUF 版本和对应 GGUF模型加载来完成视频生成,我仍旧会在这个部分提供完整的模型列表,防止有些用户直接查看这个部分的示例。
1. Wan2.1 GGUF 版本文生视频工作流
1.1 工作流文件下载

1.2 手动模型下载
从下面选择一个Diffusion models 模型文件进行下载, city96 提供了多种不同版本的模型,请访问 https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main 下载一个合适你的版本,通常体积越大,效果越好,但同时对设备性能要求也越高
从Text encoders 选择一个版本进行下载,
VAE
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-t2v-14b-Q4_K_M.gguf # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 或者你选择的版本
│ └── vae/
│ └── wan_2.1_vae.safetensors1.3 按步骤完成工作流的运行
- 确保
Unet Loader(GGUF)节点加载了wan2.1-t2v-14b-Q4_K_M.gguf模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 可以在
CLIP Text Encoder节点中输入你想要生成的视频描述内容 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
2. Wan2.1 GGUF 版本图生视频工作流
2.1 工作流文件下载

2.2 手动模型下载
从下面选择一个Diffusion models 模型文件进行下载, city96 提供了多种不同版本的模型,请访问对应仓库下载适合你的版本,通常体积越大,效果越好,但同时对设备性能要求也越高
在这里我使用 wan2.1-i2v-14b-Q4_K_M.gguf 模型来完成示例
从Text encoders 选择一个版本进行下载,
VAE
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-i2v-14b-Q4_K_M.gguf # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 或者你选择的版本
│ └── vae/
│ └── wan_2.1_vae.safetensors2.3 按步骤完成工作流的运行
- 确保
Unet Loader(GGUF)节点加载了wan2.1-i2v-14b-Q4_K_M.gguf模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中加载前面提供的输入图片 - 在
CLIP Text Encoder节点中输入你想要生成的视频描述内容,或者使用工作流中的示例 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
常见问题
如何保存为 mp4 格式视频
上面的视频生成工作流默认生成的为 .webp 格式视频,如果想要保存为其它格式视频,可以尝试使用 ComfyUI-VideoHelperSuite 插件中的 video Combine 节点来保存为 mp4 格式视频
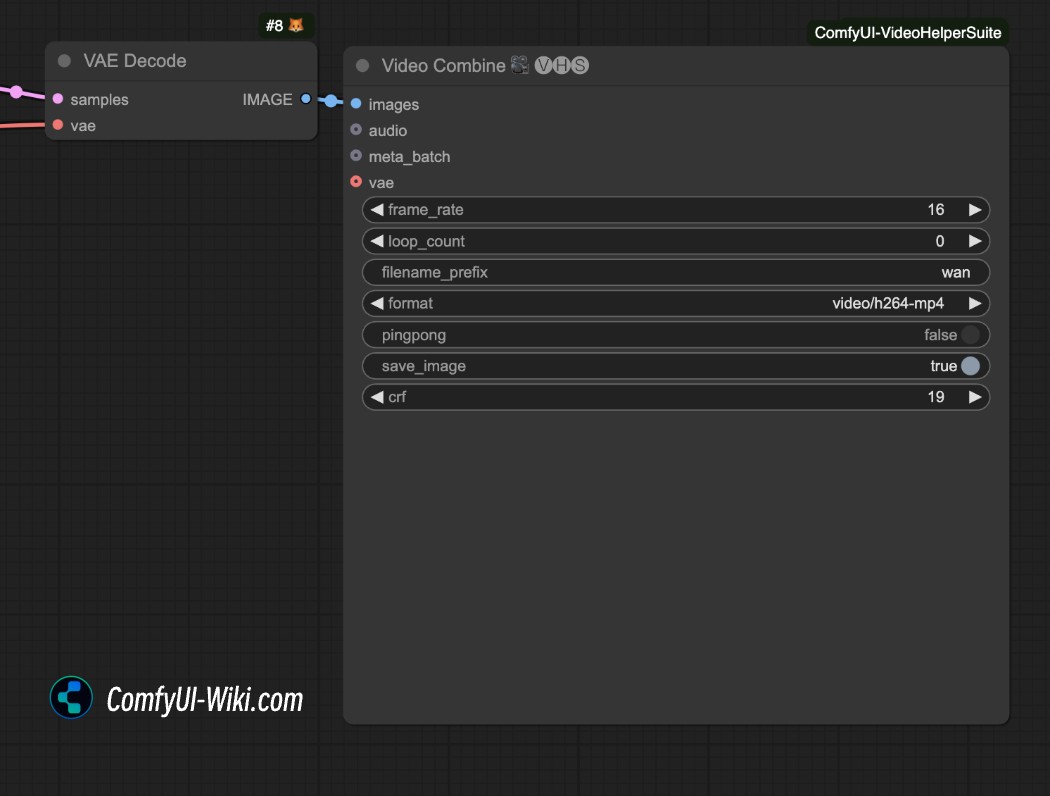
相关资源
目前所有模型已在 Hugging Face 和 ModelScope 平台开放下载:
Wan2.1 Video LoRA 工作流
在本篇示例中,我们将使用在 Wan2.1 Video 工作流中使用 LoRA 模型, 在本篇示例中我们将使用下面的模型:
访问并下载对应模型:Squish Effect (Wan2.1 I2V LoRA)
将对应模型保存到 ComfyUI/models/loras 目录下
在对应的模型中描述中,有提及对应的 lora 触发词 sq41sh squish effect ,所以在具体的提示词书写过程中我们需要将对应触发词添加到提示词中。
ComfyUI 原生 Wan2.1 Video LoRA 工作流

Json 格式文件下载
使用下面的图片作为输入图片

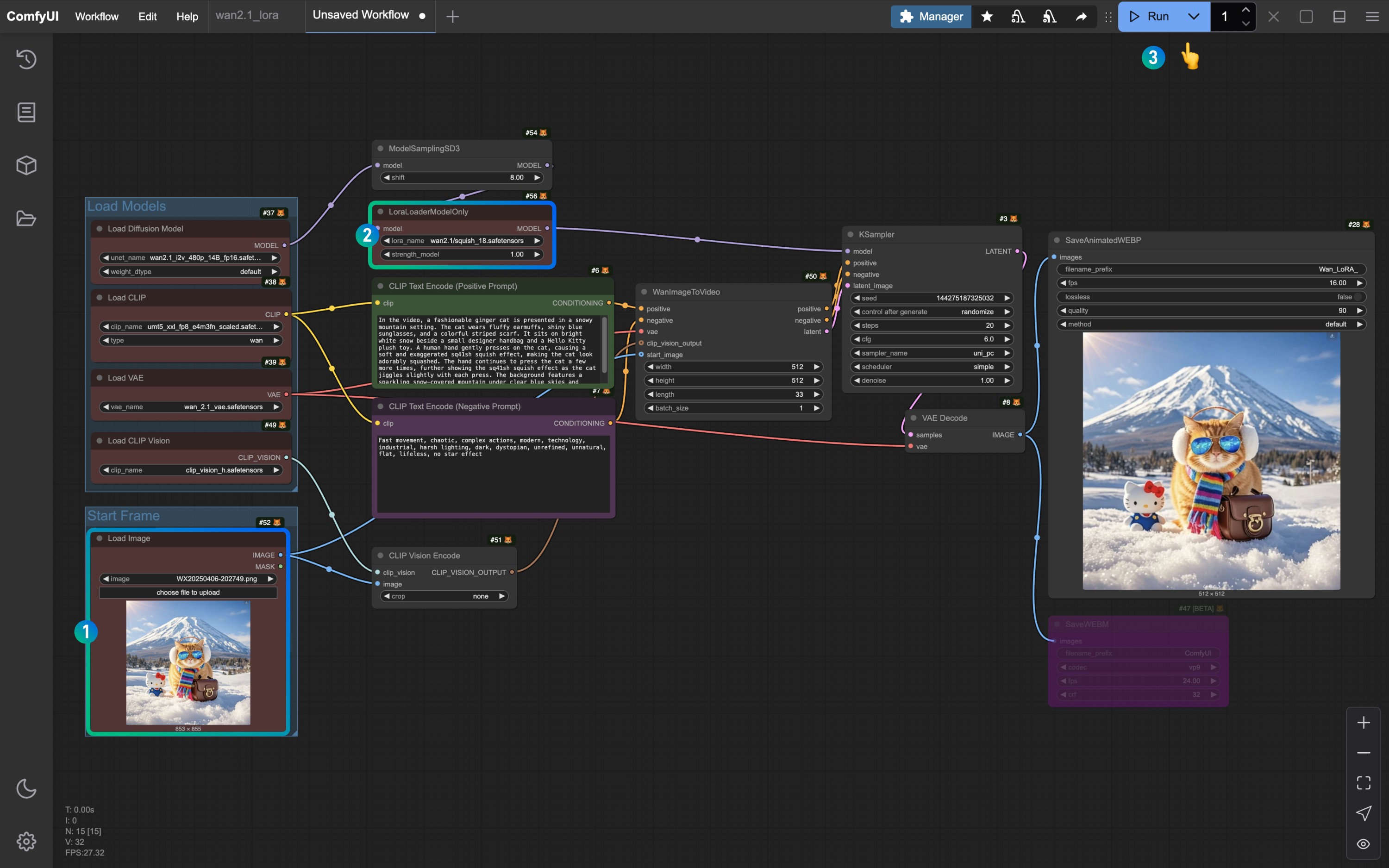
- 确保
Load image节点使用的是我们准备好的图片 - 在原始的图生视频工作流中我们添加了一个
LoraLoaderModelOnly节点,并加载本文开头使用的Squish Effect (Wan2.1 I2V LoRA)模型 - 确保所有原始的模型加载节点都已经正确加载了模型后,点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
你可以从这个工作流里看到,对应的 LoRA 模型加载的方法和之前大多图片类型的工作流依旧是非常相似的。
Kijai 的 Wan2.1 Video LoRA 工作流

Json 格式文件下载
使用下面的图片作为输入图片

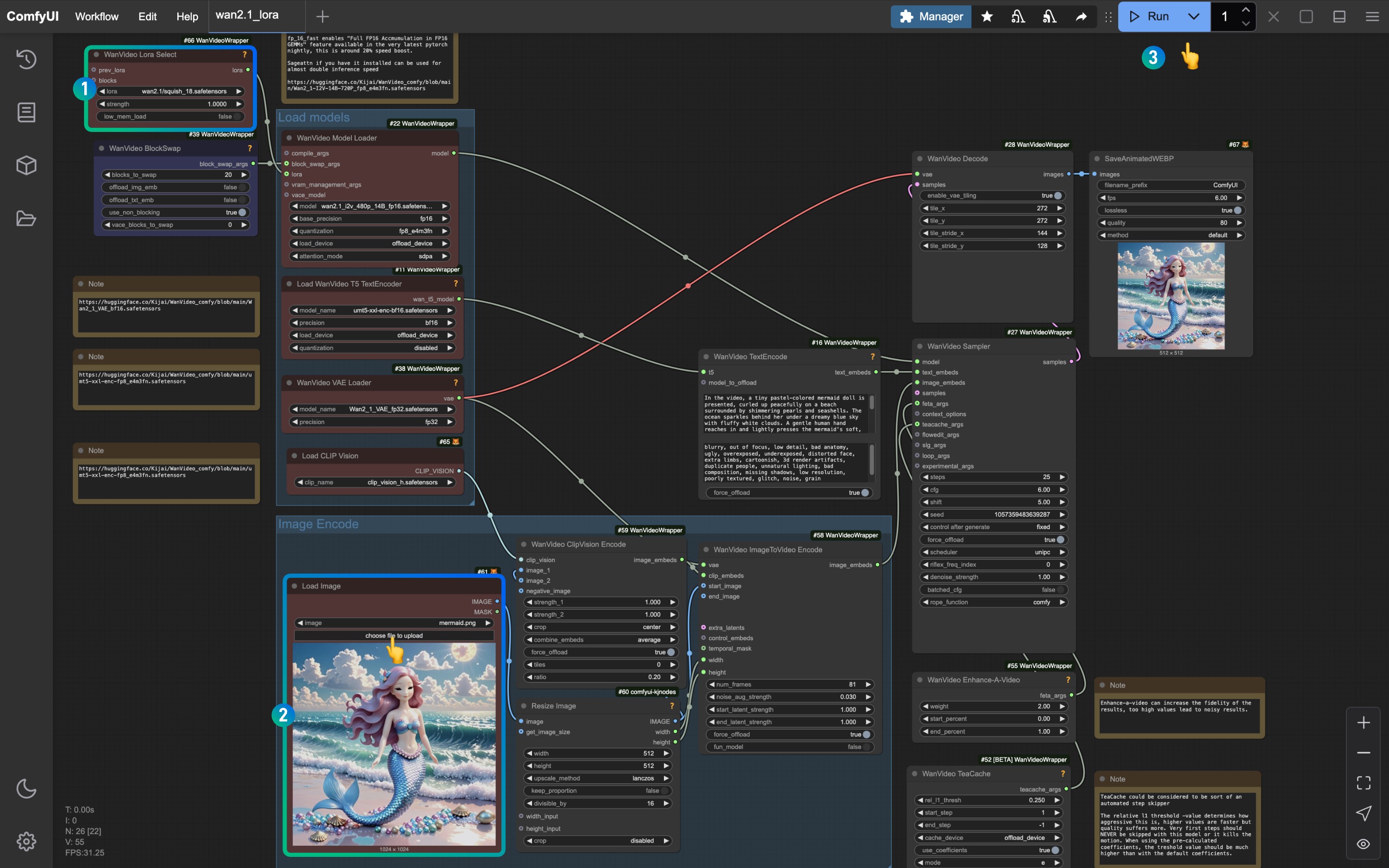
- 添加了一个
WanVideo Lora Select节点,加载我们之前使用的模型,并连接到WanVideo Model Loader节点 - 确保
Load image节点使用的是我们准备好的图片 - 确保所有原始的模型加载节点都已经正确加载了模型后,点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
GGUF 版 Wan2.1 Video LoRA 工作流
由于 GGUF 版本和 ComfyUI 原生版本的工作流非常相似,所以这里仅提供对应的 GGUF 版本的工作流文件
相关资源
LoRA 模型训练
LoRA 模型推荐
通义 Wan2.1 Fun Control ComfyUI 工作流 - 完整指南
Wan2.1-Fun-Control 是阿里团队最新发布的视频控制能力,可以实现视频的depth,openpose,canny等控制能力,目前这一模型分为 1.3B 和 14B 两大类模型。
本篇指南将涉及两类工作流
- ComfyUI 原生工作流
-
- 完全原生(不依赖第三方自定义节点)
-
- 在原生工作流上的改进版本(使用了自定义节点)
- 使用 Kijai 的 ComfyUI-WanVideoWrapper 工作流
- 两个工作流在模型上基本相同,不过我还是使用了不同来源的模型只是为了更符合原始工作流的情况和模型使用。
- 对于视频相关你可以使用 ComfyUI-VideoHelperSuite 这个自定义节点包来完成视频加载、保存成 mp4 视频合并等等丰富的视频操作
- 插件安装请参考如何安装自定义节点 这篇指南完成
ComfyUI 原生 Wan2.1 Fun Control 工作流
目前 ComfyUI 官方已经原生支持了 Wan Fun Control 模型,但是截止目前(2025-04-10)并未官方正式式发布对应的工作流示例
在开始之前你需要保证你的 ComfyUI 版本至少在这个commit之后,你才能找到对应的WanFunControlToVideo节点 请参考 如何更新 ComfyUI 来更新你的 ComfyUI 版本。
1.1 Wan2.1 Fun Control 工作流文件下载
1.1.1 工作流文件
下载下面的图片,并拖入 ComfyUI 中,将会加载对应的工作流,并提示对应的模型下载。

Json 格式下载
1.1.2 起始帧及控制视频
下载下面的图片及视频,我们将会将他们作为输入条件

1.2 手动模型安装
如果对应的模型没有成功下载,下面是对应的模型下载地址
Diffusion models 选择 1.3B 或者 14B, 14B 的文件体积更大,效果更好,但同时对设备性能要求也更高
- Wan2.1-Fun-1.3B-Control: 下载后重命名为
Wan2.1-Fun-1.3B-Control.safetensors - Wan2.1-Fun-14B-Control: 下载后重命名为
Wan2.1-Fun-14B-Control.safetensors
Text encoders 选择下面两个模型中的一个,fp16 体积较大对性能要求高
VAE
CLIP Vision 用于提取图像特征
文件保存位置
1.3 按步骤完成工作流的运行
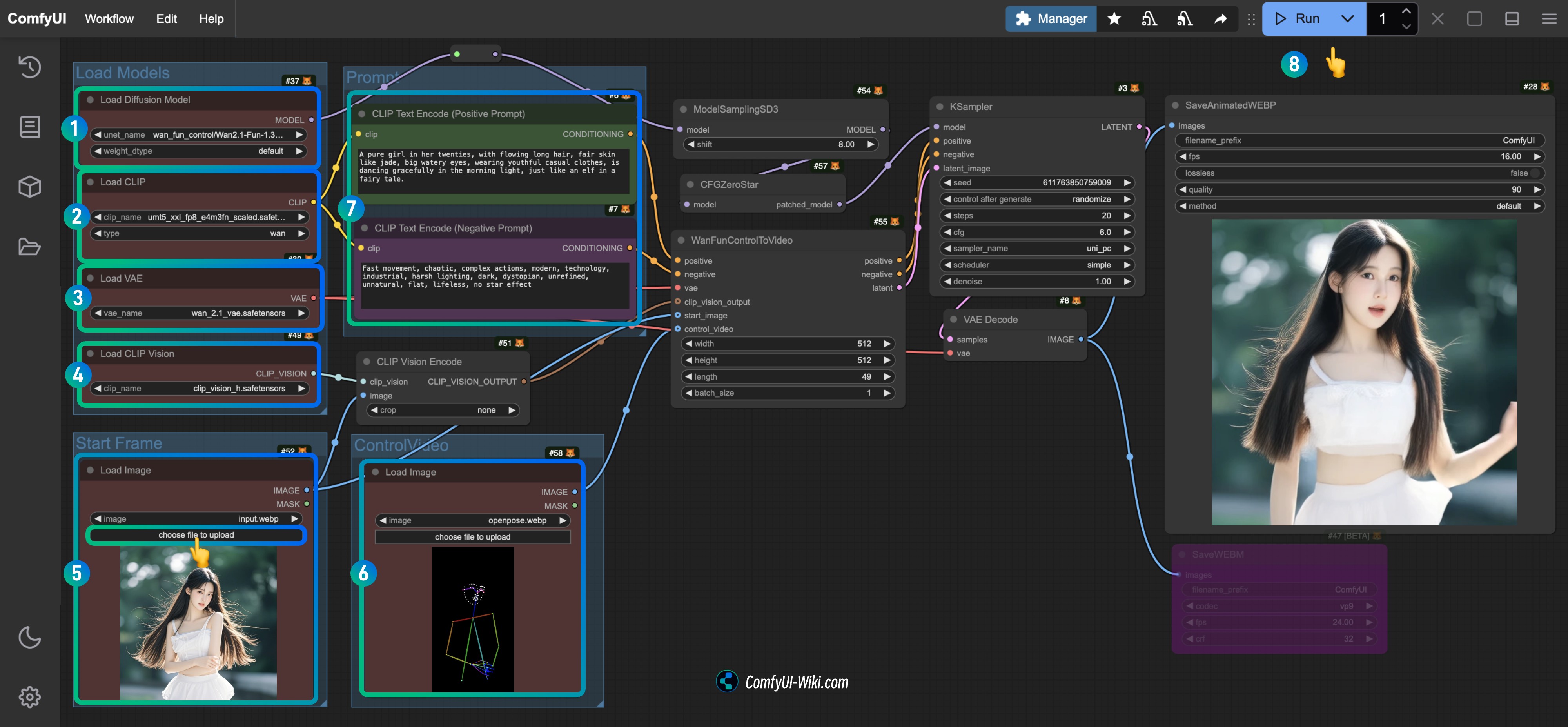
- 确保
Load Diffusion Model节点加载了Wan2.1-Fun-1.3B-Control.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中加载前面提供的输入图片作为起始帧 - 在
Load Image节点上传前面提供的视频,作为控制条件 - (可选)在
CLIP Text Encoder节点中修改视频提示词 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
1.4 工作流分析
原生的工作流主要在视频帧获取,对应的 WanFunControlToVideo 节点提供的默认的 Length 为 81(以 15 帧每秒将会生成 5秒的视频),而我的提供的控制视频仅有 49 帧,所以我进行了调整修改。 另外你可能看到人物在视频生成后被突然拉近了,这是因为起始帧图像和控制视频他们的尺寸不一致,导致处理过程中进行了裁切放大
2. Wan2.1 Fun Control 原生工作流调整版本
由于完全原生的工作流在视频尺寸和帧数计算上使用起来不是很便利,所以在这个改进版本的工作流中我使用了下面自定义节点包中的部分节点:
- ComfyUI-KJNodes 调整视频尺寸和获取图像帧数
- ComfyUI-comfyui_controlnet_aux: 进行视频图像的预处理
在开始前,确保你已经安装了这两个自定义节点包,或者使用 ComfyUI-Manager 在工作流加载后进行安装
2.1 工作流文件下载
2.1.1 工作流文件下载
下载下面的图片,并拖入 ComfyUI 中,将会加载对应的工作流,并提示对应的模型下载。

2.1.2 输入视频下载
下载下面的图片和视频,用于输入条件

因为没有足够的时间,还是使用了这个有突然放大效果的视频作为输入
2.2 按步骤完成工作流的运行
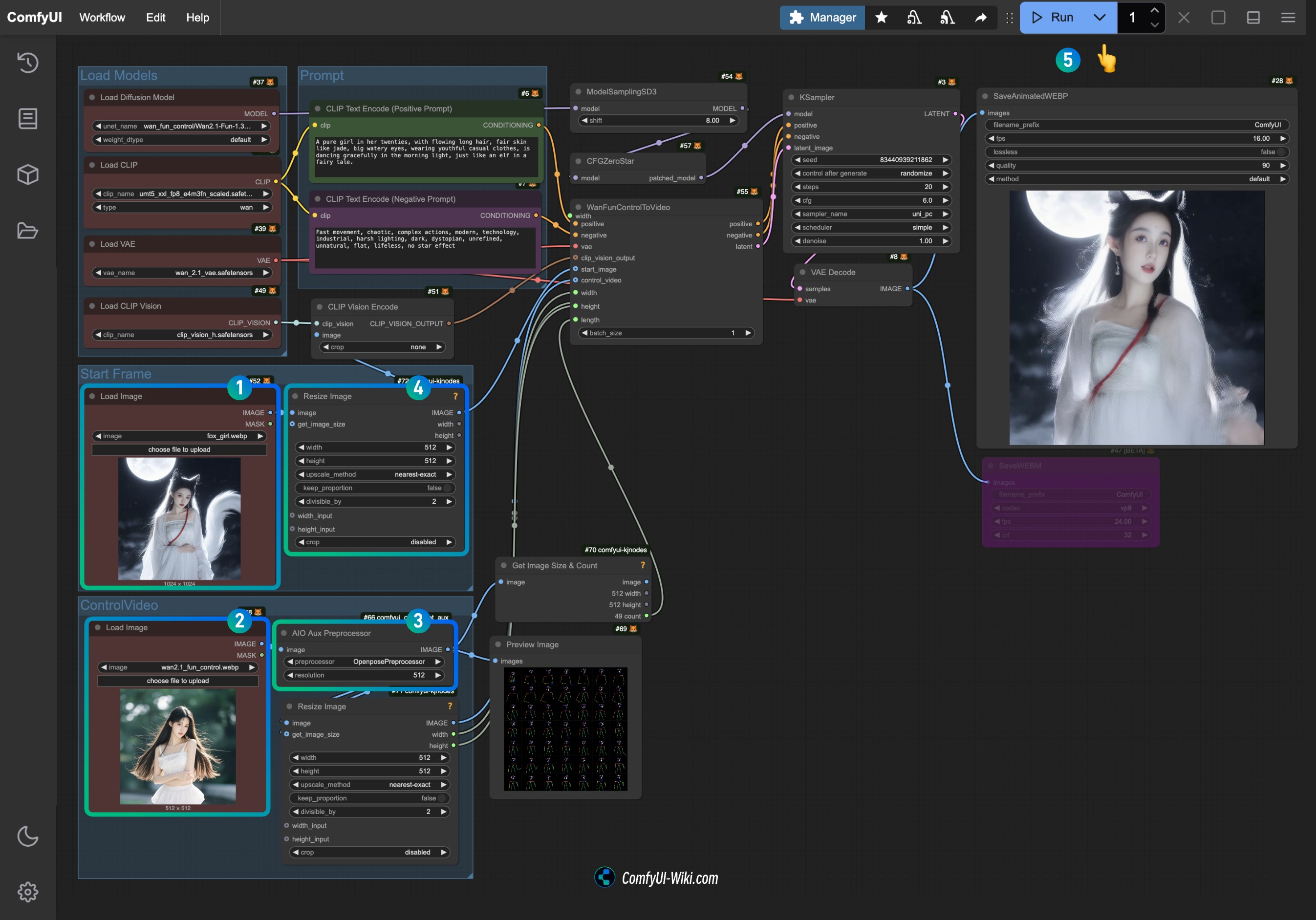
- 在 Start Frame 的
Load Image节点上传提供的输入图片 - 在 Control Video 的
Load Image节点上传前面提供的视频,作为控制条件 - 在
AIO Aux Preprocessor上选择你希望使用的预处理器(第一次运行时将会从 Hugging face下载对应模型) - 如果你需要调整尺寸,可以修改
Resize Image节点的尺寸设置,记得两个节点要保持一致 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
3. 相关扩展
你可以在这些工作流基础上,再加上对应的图像生成的节点,从而能够不依赖输入参考图像而生成最后的视频
Kijai Wan Fun Control 工作流
将使用 Kijai 的 ComfyUI-WanVideoWrapper插件 来完成 Fun-Control 的示例,Kijai 提供的原始工作流你可以在这里找到。
本篇指南涉及的工作流,经过 ComfyUI Wiki 重新整理。
此部分工作流将分为两类:
- 仅使用视频控制条件进行 文生视频图像 的Control 工作流
- 使用 Clip_vision 对参考图片特征进行解析提取后,并添加视频控制条件的图像参考视频生成 的 Control 的工作流
相关安装
自定义节点安装
你需要安装以下几个插件,来保证工作流正常运行
- ComfyUI-WanVideoWrapper: 需要更新到最新版本
- ComfyUI-VideoHelperSuite
- ComfyUI-KJNodes
- ComfyUI-comfyui_controlnet_aux: 进行视频图像的预处理,或者你也可以替换为你常用的图像预处理节点
你可以使用 ComfyUI Manager 来更新或者安装上面提到的自定义节点,或者参考如何安装自定义节点 这篇指南完成对应的安装。
ComfyUI-comfyui_controlnet_aux 在首次运行时会下载对应的模型,请确保你可以正常访问 huggingface
模型安装
Wan2.1 Fun Control 提供了 1.3B 和 14B 两个模型,你可以根据你的设备性能选择合适的模型,
- Wan2.1-Fun-1.3B-Control: 下载后重命名为
Wan2.1-Fun-1.3B-Control.safetensors - Wan2.1-Fun-14B-Control: 下载后重命名为
Wan2.1-Fun-14B-Control.safetensors - Kijai/Wan2.1-Fun-Control-14B_fp8_e4m3fn.safetensors
从Text encoders 选择一个版本进行下载,
VAE
CLIP Vision
文件保存位置
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── Wan2.1-Fun-1.3B-Control.safetensors # 或者你选择的版本
│ ├── 📂 text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # 或者你选择的版本
│ ├── 📂 vae/
│ │ └── Wan2_1_VAE_bf16.safetensors
│ └── 📂clip_vision/
│ └── clip_vision_h.safetensors 1. 视频控制文生视频工作流
1.1 工作流文件下载
下载下面的图片,并拖入 ComfyUI 中,加载对应的工作流

Json 格式下载
下载下面的视频,作为输入视频
1.2 按步骤完成工作流的运行
下载下面的图片,并拖入 ComfyUI 中,加载对应的工作流
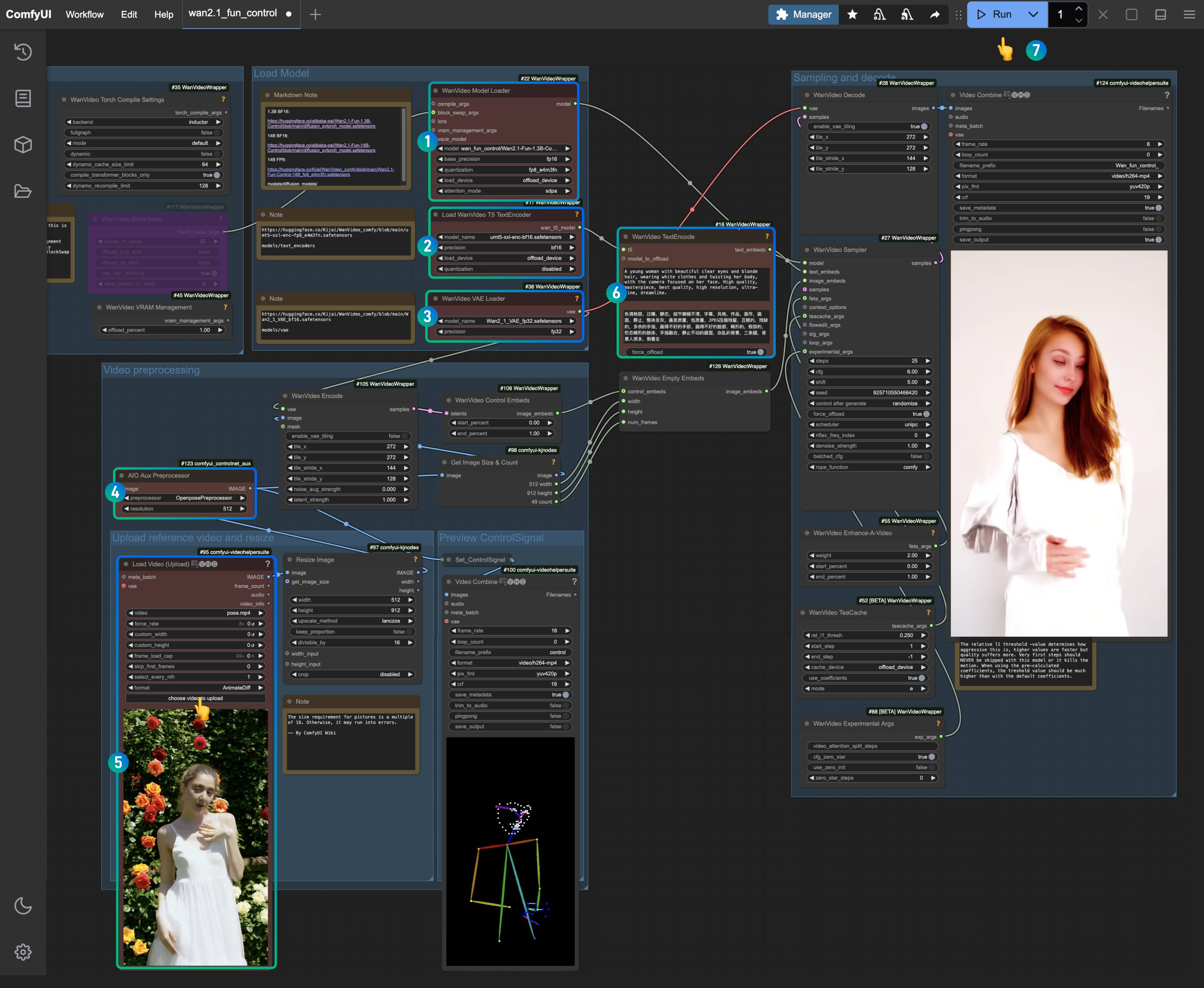
确保对应节点加载了对应模型,使用你下载的版本即可
- 确保
WanVideo Model Loader节点加载了Wan2.1-Fun-1.3B-Control.safetensors模型 - 确保
Load WanVideo T5 TextEncoder节点加载了umt5-xxl-enc-bf16.safetensors模型 - 确保
WanVideo Vae Loader节点加载了Wan2_1_VAE_bf16.safetensors模型 - 在
AIO AuxAux Preprocessor节点中选择OpenposePreprocessor节点 - 在
Load Video(Upload)节点中上传前面我们提供的输入视频 - 在
WanVideo TextEncode处输入你想要生成的视频画面提示词(可不修改,保持工作流默认) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
1.3 工作流分析
这个版本的工作流,主要将预处理后的图像条件进行编码,然后再对视频进行生成,在图像预处理节点 OpenposePreprocessor 中,你可以选择多种预处理方式,比如 Openpose,Depth,Canny 等,这里我们选择 Openpose 预处理方式,生成了对应的人物动作控制并编码。
2. 视频控制参考图像视频生成的工作流
这个工作流主要加载了一个 clip_vision_h.safetensors 模型,从而可以很好地理解参考图像的内容,但并不是完全保留一致进行视频生成,而是根据参考图像的特征进行视频生成。
2.1 工作流文件下载
下载下面的图片,并拖入 ComfyUI 中,加载对应的工作流

Json 格式下载
下载下面的视频和图片,我们将会将他们作为输入条件


2.2 按步骤完成工作流的运行
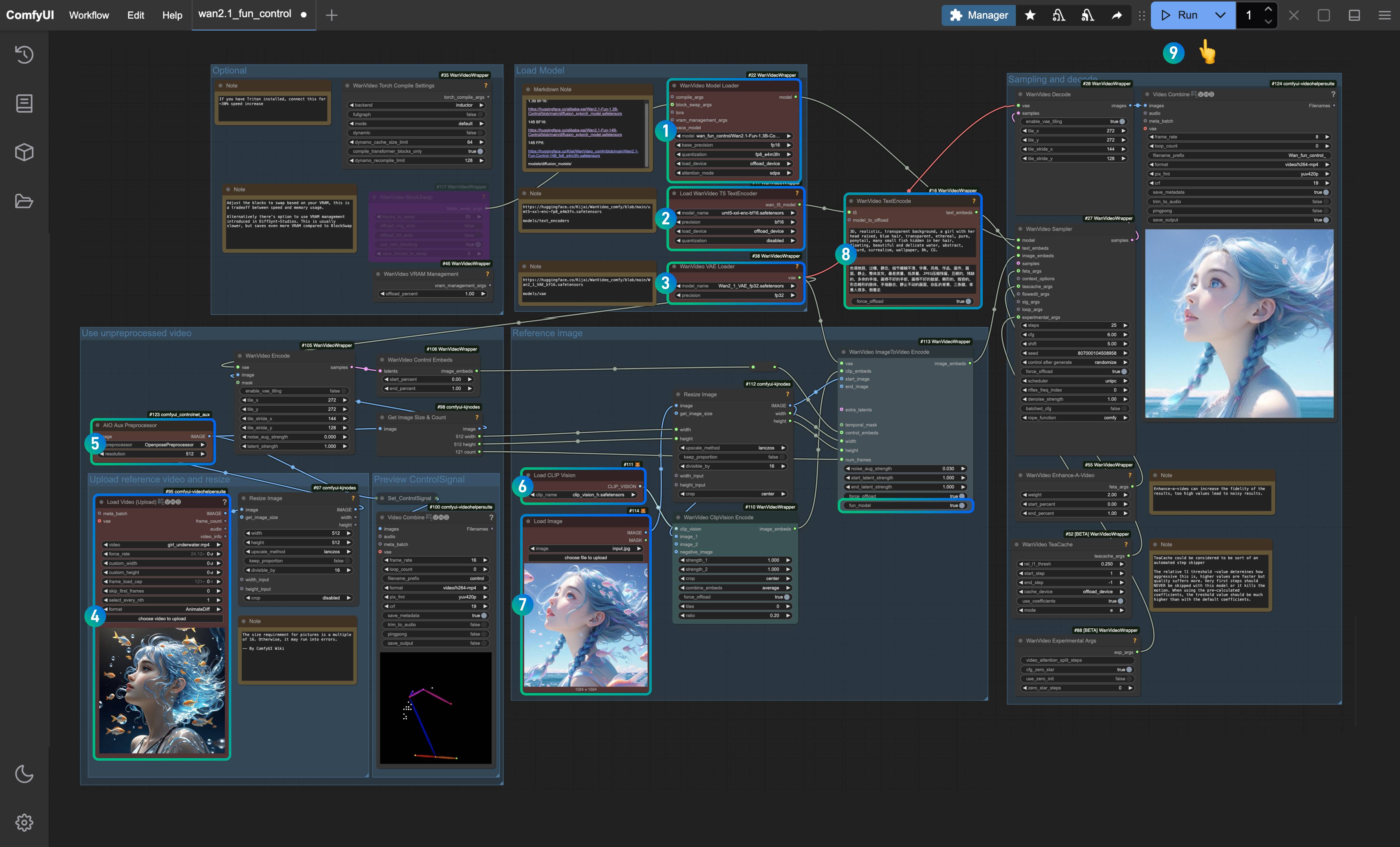
- 确保
WanVideo Model Loader节点加载了Wan2.1-Fun-1.3B-Control.safetensors模型 - 确保
Load WanVideo T5 TextEncoder节点加载了umt5-xxl-enc-bf16.safetensors模型 - 确保
WanVideo Vae Loader节点加载了Wan2_1_VAE_bf16.safetensors模型 - 在
Load Video(Upload)节点中上传前面我们提供的输入视频 - 在
AIO AuxAux Preprocessor节点中选择OpenposePreprocessor节点 - 在
Load CLIP Vision节点中,选择clip_vision_h.safetensors模型被加载了,它将用于提取参考图像的特征 - 在
Load Image节点中,上传之前提供的参考图片 - 在
WanVideo TextEncode处输入你想要生成的视频画面提示词(可不修改,保持工作流默认) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
2.3 工作流分析
- 由于 Kijai 更新了对应的节点,所以请注意
WanVideo ImageToVideo Encode节点最后有一个fun_model的选项需要设置为 true。 - 经过对比,使用了参考图像的特征会更贴合,所以使用参考图像还是必要的,但是由于只是提取了图像特征,所以并不能完整地保持角色一致性。
- 在图像预处理处,你可以尝试将多个预处理节点进行组合,来生成更加丰富的控制条件。
Wan2.2 ComfyUI 工作流完整使用指南,官方+社区版本(Kijai, GGUF)工作流全攻略
教程总览
本教程将全面介绍 Wan2.2 视频生成模型在 ComfyUI 中的各种实现方式和使用方法。Wan2.2 是阿里云推出的新一代多模态生成模型,采用创新的 MoE(Mixture of Experts)架构,具备影视级美学控制、大规模复杂运动生成和精准语义遵循等核心特性。
本教程涵盖的版本和内容
已完成的版本:
- ✅ ComfyUI 官方原生版本 - 由 ComfyOrg 官方提供的完整工作流
- ✅ Wan2.2 5B 混合版本 - 支持文生视频和图生视频的轻量级模型
- ✅ Wan2.2 14B 文生视频版本 - 高质量文本到视频生成
- ✅ Wan2.2 14B 图生视频版本 - 静态图像转动态视频
- ✅ Wan2.2 14B 首尾帧视频生成 - 基于起始和结束帧的视频生成
正在准备中的版本:
- 🔄 Kijai WanVideoWrapper 版本
- 🔄 GGUF 量化版本 - 适用于低配置设备的优化版本
- 🔄 Lightx2v 4steps LoRA - 快速生成优化方案
关于 Wan2.2 视频生成模型
Wan2.2 采用创新的 MoE(Mixture of Experts)架构,由高噪专家模型和低噪专家模型组成,能够根据去噪时间步进行专家模型划分,从而生成更高质量的视频内容。
核心优势:
- 影视级美学控制:专业镜头语言,支持光影、色彩、构图等多维度视觉控制
- 大规模复杂运动:流畅还原各类复杂运动,强化运动可控性和自然度
- 精准语义遵循:复杂场景理解,多对象生成,更好还原创意意图
- 高效压缩技术:5B版本高压缩比VAE,显存优化,支持混合训练
Wan2.2 系列模型基于 Apache2.0 开源协议,支持商业使用。Apache2.0 许可证允许您自由使用、修改和分发这些模型,包括商业用途,只需保留原始版权声明和许可证文本。
Wan2.2 开源模型版本概览
| 模型类型 | 模型名称 | 参数量 | 主要功能 | 模型仓库 |
|---|---|---|---|---|
| 混合模型 | Wan2.2-TI2V-5B | 5B | 支持文本生成视频和图像生成视频的混合版本,单一模型满足两大核心任务需求 | 🤗 Wan2.2-TI2V-5B |
| 图生视频 | Wan2.2-I2V-A14B | 14B | 将静态图像转换为动态视频,保持内容一致性和流畅的动态过程 | 🤗 Wan2.2-I2V-A14B |
| 文生视频 | Wan2.2-T2V-A14B | 14B | 从文本描述生成高质量视频,具备影视级美学控制和精准语义遵循 | 🤗 Wan2.2-T2V-A14B |
Wan2.2 提示词指南 - Wan 提供的详细提示词编写指南
ComfyUI 官方资源
ComfyOrg 官方直播回放
ComfyOrg 的 Youtube 有对 Wan2.2 在 ComfyUI 中的使用进行了详细讲解:
Wan2.2 ComfyUI 官方原生版本工作流使用指南
版本说明
ComfyUI 官方原生版本由 ComfyOrg 团队提供,使用 🤗 Comfy-Org/Wan_2.2_ComfyUI_Repackaged 重新打包的模型文件,确保与 ComfyUI 的最佳兼容性。
1. Wan2.2 TI2V 5B 混合版本工作流
Wan2.2 5B 版本配合 ComfyUI 原生 offloading 功能,能很好地适配 8GB 显存,是入门用户的理想选择。
工作流获取方式
请更新你的 ComfyUI 到最新版本,并通过菜单 工作流 -> 浏览模板 -> 视频 找到 “Wan2.2 5B video generation” 以加载工作流
下载 JSON 格式工作流
模型文件下载
Diffusion Model
VAE
Text Encoder
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ └───wan2.2_ti2v_5B_fp16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan2.2_vae.safetensors操作步骤详解
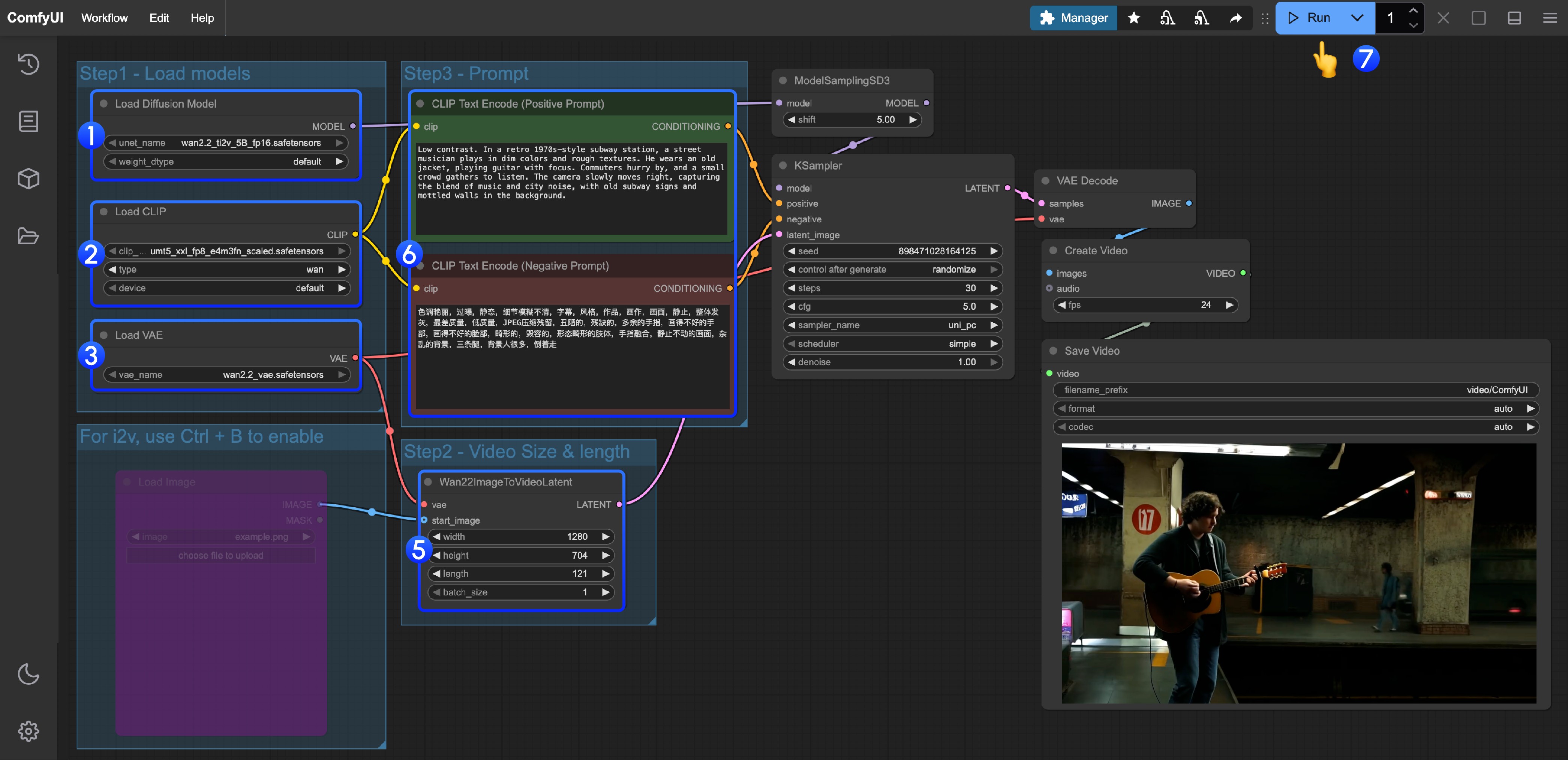
- 确保
Load Diffusion Model节点加载了wan2.2_ti2v_5B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan2.2_vae.safetensors模型 - (可选)如果你需要进行图生视频,可以使用快捷键 Ctrl+B 来启用
Load image节点来上传图片 - (可选)在
Wan22ImageToVideoLatent你可以进行尺寸的设置调整,和视频总帧数length调整 - (可选)如果你需要修改提示词(正向及负向)请在序号
5的CLIP Text Encoder节点中进行修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
2. Wan2.2 14B T2V 文生视频工作流
工作流获取方式
请更新你的 ComfyUI 到最新版本,并通过菜单 工作流 -> 浏览模板 -> 视频 找到 “Wan2.2 14B T2V”
或者更新你的 ComfyUI 到最新版本后,下载下面的工作流并拖入 ComfyUI 以加载工作流
模型文件下载
Diffusion Model
VAE
Text Encoder
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors操作步骤详解
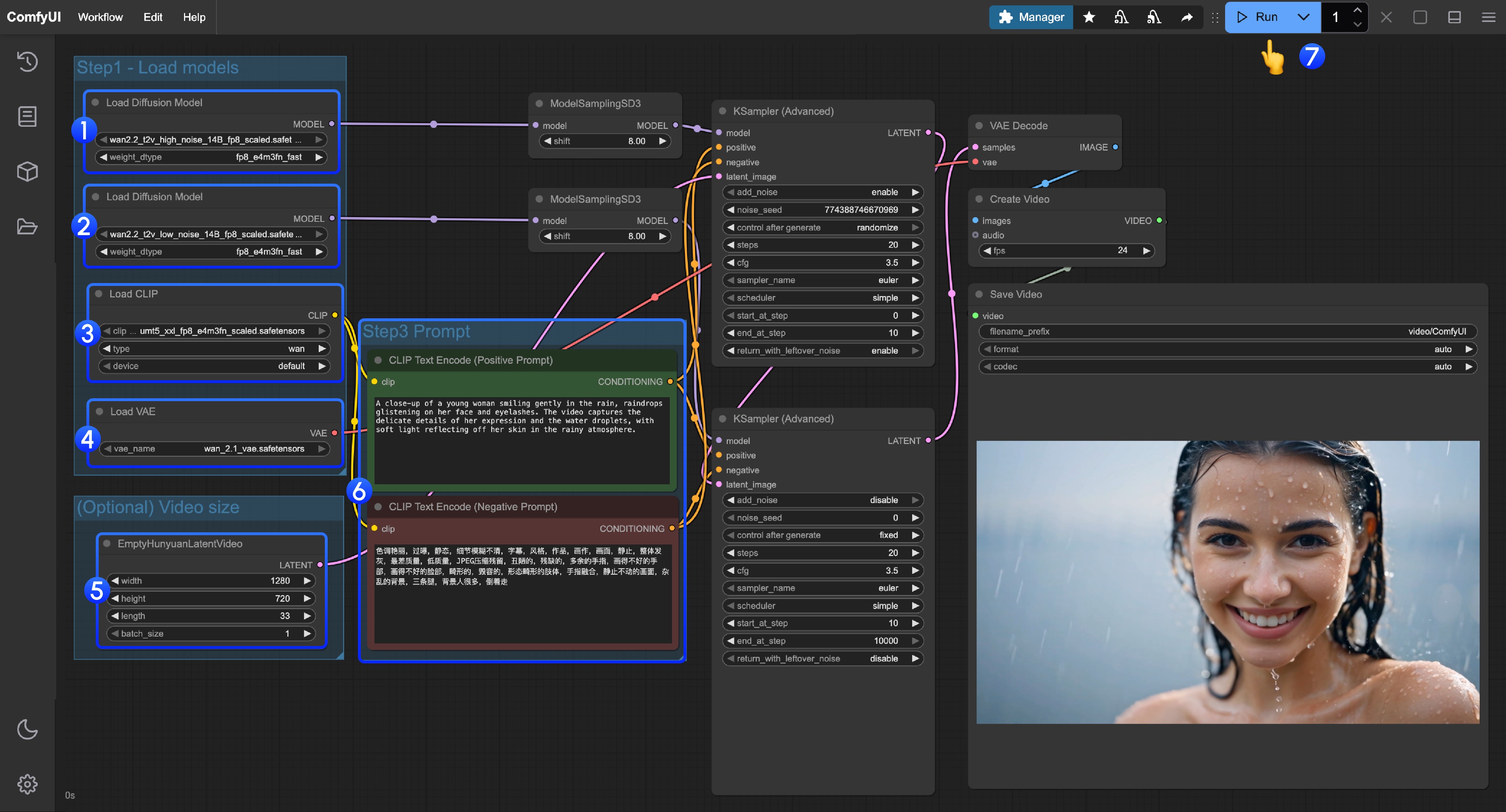
- 确保第一个
Load Diffusion Model节点加载了wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors模型 - 确保第二个
Load Diffusion Model节点加载了wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - (可选)在
EmptyHunyuanLatentVideo你可以进行尺寸的设置调整,和视频总帧数length调整 - 如果你需要修改提示词(正向及负向)请在序号
6的CLIP Text Encoder节点中进行修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
3. Wan2.2 14B I2V 图生视频工作流
工作流获取方式
请更新你的 ComfyUI 到最新版本,并通过菜单 工作流 -> 浏览模板 -> 视频 找到 “Wan2.2 14B I2V” 以加载工作流
或者更新你的 ComfyUI 到最新版本后,下载下面的工作流并拖入 ComfyUI 以加载工作流
你可以使用下面的图片作为输入

模型文件下载
Diffusion Model
VAE
Text Encoder
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_i2v_low_noise_14B_fp16.safetensors
│ │ └─── wan2.2_i2v_high_noise_14B_fp16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors操作步骤详解
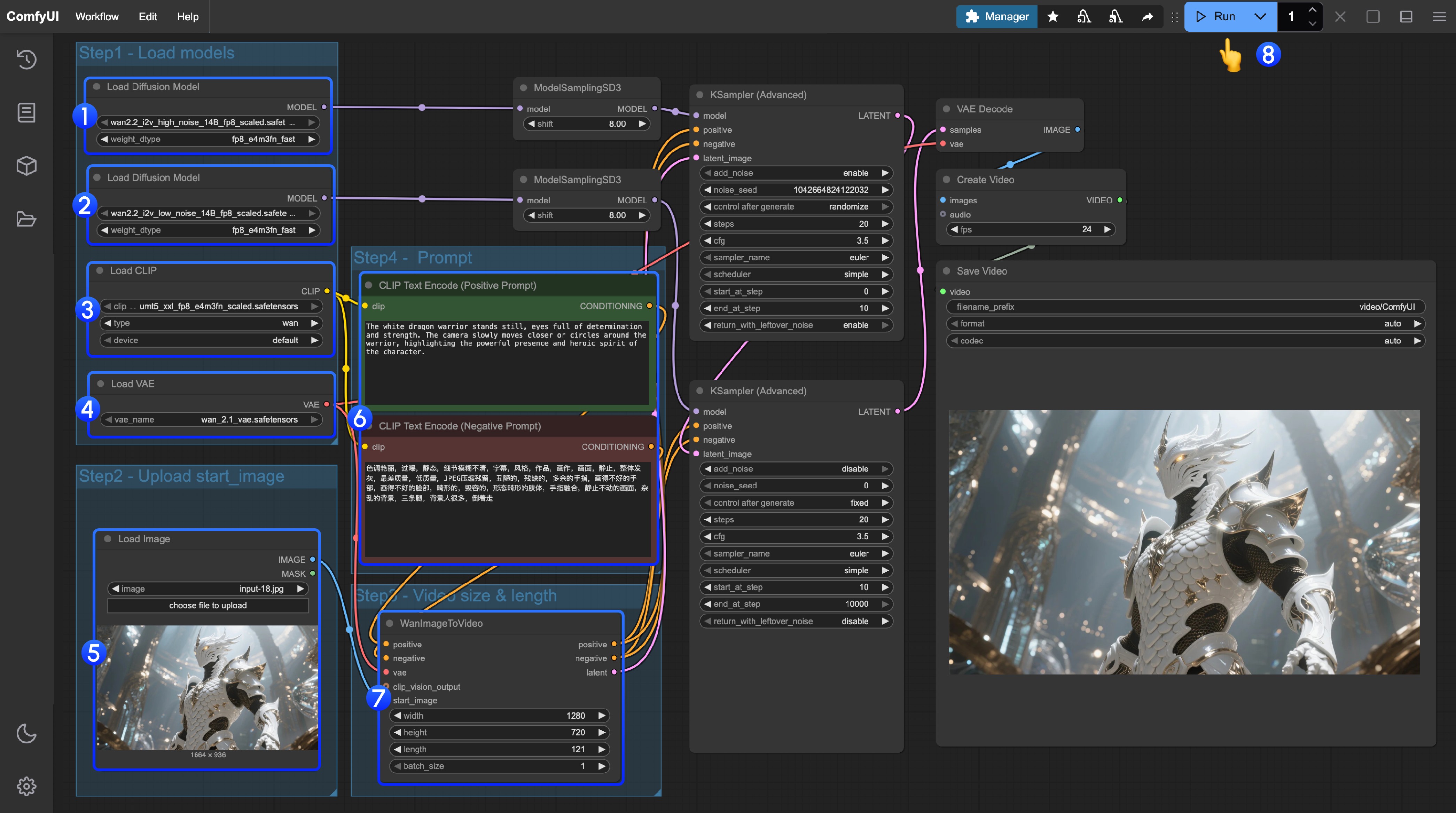
- 确保第一个
Load Diffusion Model节点加载了wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors模型 - 确保第二个
Load Diffusion Model节点加载了wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 在
Load Image节点上传作为起始帧的图像 - 如果你需要修改提示词(正向及负向)请在序号
6的CLIP Text Encoder节点中进行修改 - 可选)在
EmptyHunyuanLatentVideo你可以进行尺寸的设置调整,和视频总帧数length调整 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
4. Wan2.2 14B FLF2V 首尾帧视频生成工作流
首尾帧工作流使用模型位置与 I2V 部分完全一致
工作流及素材获取
下载下面的视频或者 JSON 格式工作流在 ComfyUI 中打开
下载下面的素材作为输入


操作步骤详解
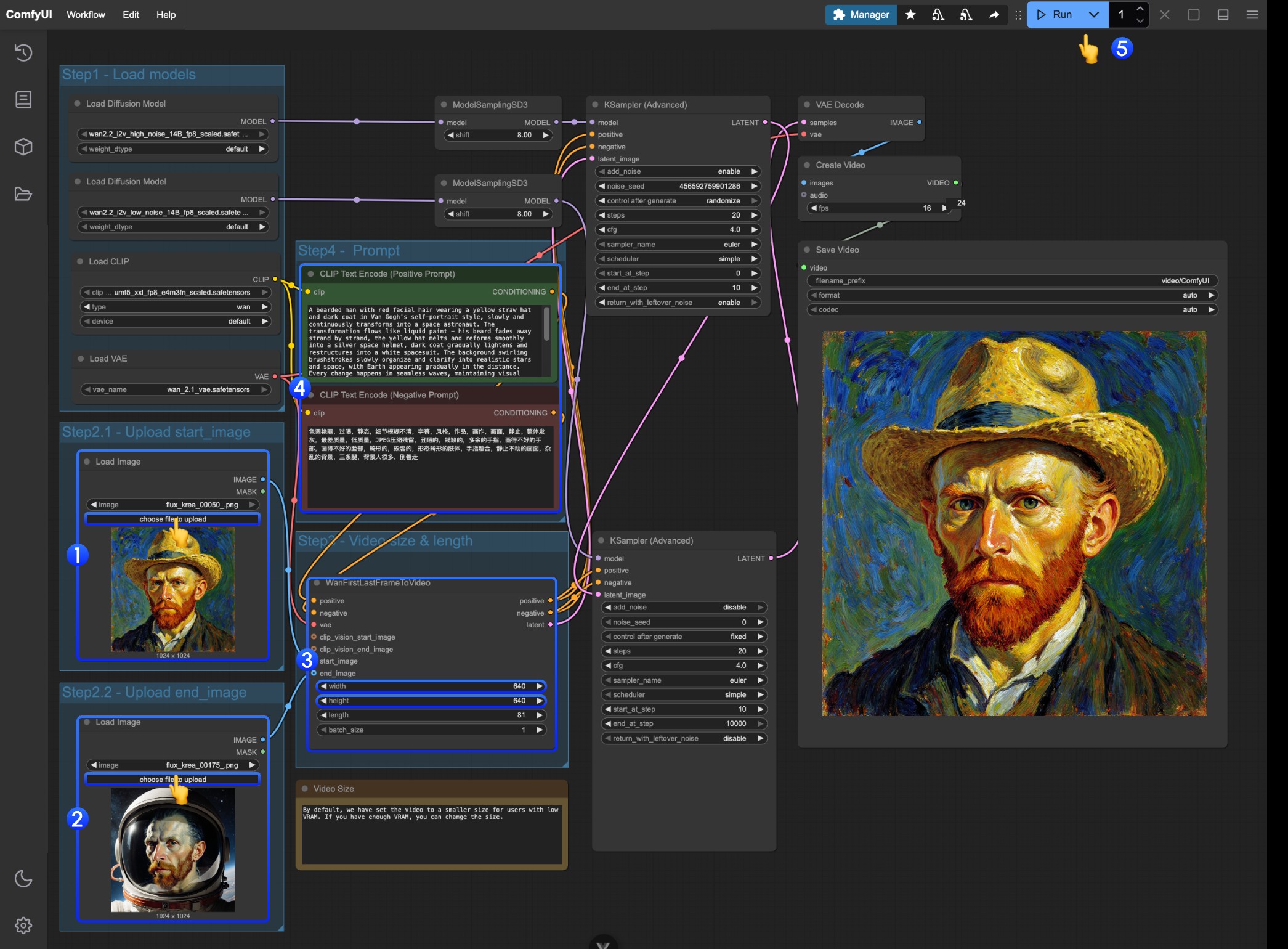
- 在第一个
Load Image节点上传作为起始帧的图像 - 在第二个
Load Image节点上传作为起始帧的图像 - 在
WanFirstLastFrameToVideo上修改尺寸设置- 工作流默认设置了一个比较小的尺寸,防止低显存用户运行占用过多资源
- 如果你有足够的显存,可以尝试 720P 左右尺寸
- 根据你的首尾帧撰写合适的提示词
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Wan2.2 Kijai WanVideoWrapper ComfyUI 工作流
此部分内容正在准备中,预计将在近期更新。
这部分教程将介绍使用 Kijai/ComfyUI-WanVideoWrapper 的便捷方式。
相关模型仓库:https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
Wan2.2 GGUF 量化版 ComfyUI 工作流
此部分内容正在准备中,预计将在近期更新。
GGUF 版本适用于显存有限的用户,提供以下资源:
相关自定义节点: City96/ComfyUI-GGUF
Lightx2v 4steps LoRA 使用说明
此部分内容正在准备中,预计将在近期更新。
Lightx2v 提供了快速生成优化方案:
Wan2.2 Animate 代表了 AI 驱动角色动画的突破,为视频内容中的角色替换和动作转移提供了全面的解决方案。
这个高级框架使用户能够使用参考视频无缝地为静态角色图像制作动画,以显著的精度捕捉复杂的面部表情和身体动作。此外,它可以在保持原始环境背景和照明条件的同时替换视频中的现有角色。
关键功能
- 双重操作模式: 在角色动画和视频替换功能之间无缝切换
- 基于骨骼的动作控制: 利用先进的姿势估计技术进行精确动作复制
- 表情保真度: 保留源材料中的微妙面部表情和微动作
- 环境一致性: 保持原始视频的照明和色彩调节,实现自然的集成
- 扩展视频支持: 迭代处理确保在较长序列中平滑的动作连续性
关于 Wan2.2 Animate 工作流
在本教程中,我们将包含两种工作流:
- ComfyUI 官方原生版本(核心节点)
- Kijai ComfyUI-WanVideoWrapper 版本[待更新]
Comfy Org 直播回放
Wan2.2 Animate ComfyUI 原生工作流(核心节点)
1. 工作流设置
首先下载工作流文件并将其导入 ComfyUI。
所需输入素材:
参考图像:

输入视频
2. 模型下载
扩散模型
- Wan2_2-Animate-14B_fp8_e4m3fn_scaled_KJ.safetensors - Kijai 仓库的优化版本
- wan2.2_animate_14B_bf16.safetensors - 原始模型权重
CLIP 视觉模型
LoRA 模型
VAE 模型
文本编码器
3. 自定义节点安装
要获得完整的工作流体验,请使用 ComfyUI-Manager 或手动安装以下自定义节点:
必需扩展:
有关安装指南,请参阅 如何安装自定义节点
4. 工作流配置
Wan2.2 Animate 在两种不同模式下运行:
- 混合模式: 在现有视频内容中进行角色替换
- 移动模式: 动作转移以动画化静态角色图像
4.1 混合模式操作
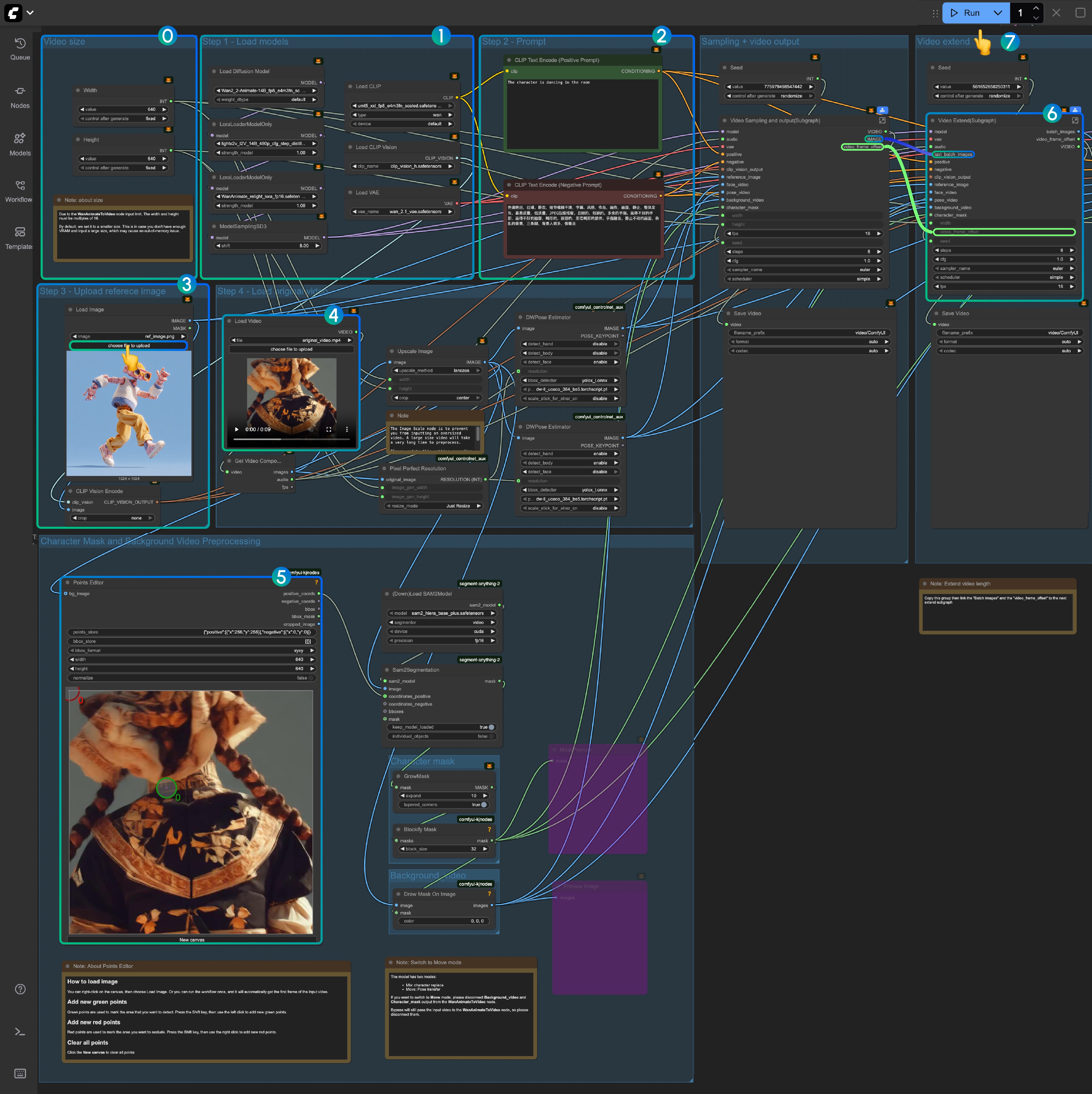
设置指南:
-
初始测试: 首次执行时使用较小的视频尺寸以验证 VRAM 兼容性。由于
WanAnimateToVideo的限制,确保视频尺寸是 16 的倍数。 -
模型验证: 确认所有必需模型都已正确加载
-
提示词自定义: 根据特定用例需要修改文本提示词
-
参考图像: 上传目标角色图像
-
输入视频处理: 最初使用提供的示例视频。来自 comfyui_controlnet_aux 的 DWPose 估计器 自动将输入视频处理为姿势和面部控制序列
-
点编辑器配置: 来自 KJNodes 的
Points Editor需要初始帧加载。运行一次工作流或手动上传第一帧 -
视频扩展: “Video Extend” 组扩展输出长度
- 每次扩展添加 77 帧(约 4.8 秒)
- 5 秒以下视频跳过
- 对于更长的扩展,复制组并依次连接
batch_images和video_frame_offset输出
-
执行: 点击
Run或使用Ctrl(Cmd) + Enter开始生成
4.2 移动模式配置
工作流使用 子图 功能进行模式切换:
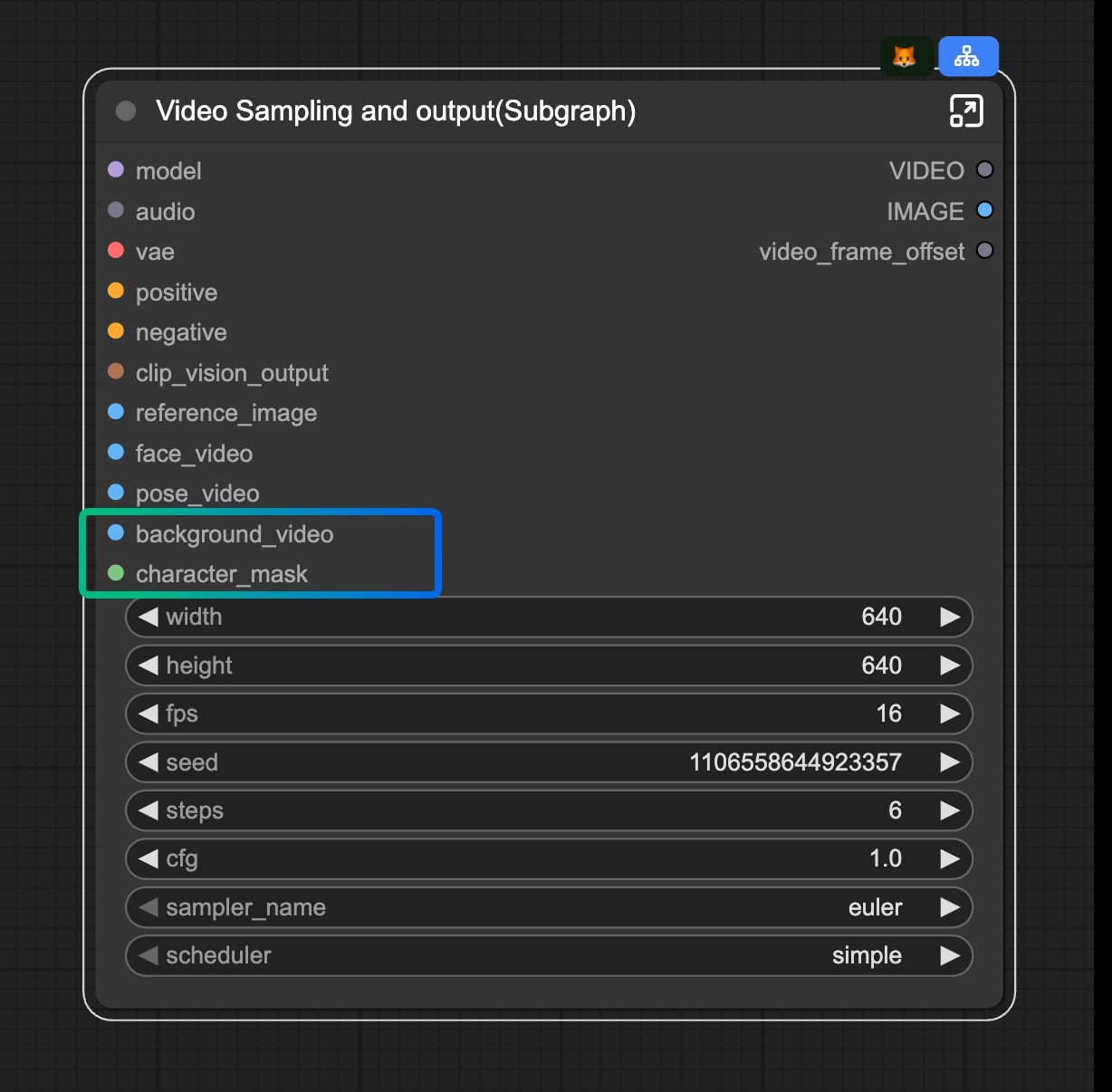
模式切换: 要激活移动模式,从 Video Sampling and output(Subgraph) 节点断开 background_video 和 character_mask 输入。
Wan2.2 Animate ComfyUI-WanVideoWrapper 工作流
[待更新]
Wan2.2 Fun Control ComfyUI 工作流完整使用指南,官方+社区版本(Kijai, GGUF)工作流全攻略
本教程将全面介绍 Wan2.2 Fun Control 视频控制生成模型在 ComfyUI 中的各种实现方式和使用方法。Wan2.2 Fun Control 是阿里云推出的新一代视频生成与控制模型,通过引入创新性的控制代码(Control Codes)机制,结合深度学习和多模态条件输入,能够生成高质量且符合预设控制条件的视频。
本教程涵盖的版本和内容
已完成的版本:
- ✅ ComfyUI 官方原生版本 - 由 我再 ComfyOrg 官方文档中提供的完整工作流
- ✅ Wan2.2 Fun Control 14B 视频控制版本 - 高质量多模态控制视频生成
正在准备中的版本:
- 🔄 Kijai WanVideoWrapper 版本 - 社区开发的便捷包装器
- 🔄 GGUF 量化版本 - 适用于低配置设备的优化版本
模型技术特点
Wan2.2 Fun Control 基于 Wan2.2 架构,专门针对视频控制生成进行了优化,具备以下核心特性:
核心优势:
- 多模态控制:支持多种控制条件,包括 Canny(线稿)、Depth(深度)、OpenPose(人体姿势)、MLSD(几何边缘)等,同时支持使用轨迹控制
- 高质量视频生成:基于 Wan2.2 架构,输出影视级质量视频
- 多语言支持:支持中英文等多语言提示词输入
- 多分辨率支持:支持生成512×512、768×768、1024×1024等分辨率的视频,适配不同场景需求
开源协议说明
Wan2.2 Fun Control 系列模型基于 Apache2.0 开源协议,支持商业使用。Apache2.0 许可证允许您自由使用、修改和分发这些模型,包括商业用途,只需保留原始版权声明和许可证文本。
Wan2.2 Fun Control 开源模型版本概览
| 模型类型 | 模型名称 | 参数量 | 主要功能 | 模型仓库 |
|---|---|---|---|---|
| 视频控制 | Wan2.2-Fun-A14B-Control | 14B | 支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制 | 🤗 Wan2.2-Fun-A14B-Control |
相关代码仓库
- VideoX-Fun GitHub 仓库 - 官方提供的完整实现代码
- Wan2.2 Fun Control 官方文档 - 详细的模型说明和使用指南
Wan2.2 Fun Control ComfyUI 官方原生版本工作流使用指南
版本说明
ComfyUI 官方原生版本由 ComfyOrg 团队提供,使用重新打包的模型文件,确保与 ComfyUI 的最佳兼容性。该版本支持标准模式和 Lightx2v 4步 LoRA 加速模式。
性能对比测试
下面是使用 RTX4090D 24GB 显存 GPU 测试的结果 640*640 分辨率, 81 帧长度的用时对比:
| 模型类型 | 分辨率 | 显存占用 | 首次生成时长 | 第二次生成时长 |
|---|---|---|---|---|
| fp8_scaled | 640×640 | 83% | ≈ 524秒 | ≈ 520秒 |
| fp8_scaled + 4步LoRA加速 | 640×640 | 89% | ≈ 138秒 | ≈ 79秒 |
由于使用了4 步 LoRA 对于初次使用工作流的用户体验较好,但可能导致生成的视频动态会有损失,我们默认启用了使用了加速 LoRA 版本,如果你需要启用另一组的工作流,框选后使用 Ctrl+B 即可启用。
1. Wan2.2 Fun Control 视频控制生成 ComfyUI 工作流
工作流获取方式
下载下面的视频或者 JSON 文件并拖入 ComfyUI 中以加载对应的工作流
下载 JSON 格式工作流
请下载下面的图片及视频,我们将作为输入。

这里我们使用了经过预处理的视频, 可以直接用于控制视频生成
模型文件下载
下面的模型你可以在 Wan_2.2_ComfyUI_Repackaged 找到
Diffusion Model
- wan2.2_fun_control_high_noise_14B_fp8_scaled.safetensors
- wan2.2_fun_control_low_noise_14B_fp8_scaled.safetensors
Wan2.2-Lightning LoRA (可选,用于加速)
- wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
VAE
Text Encoder
操作步骤详解
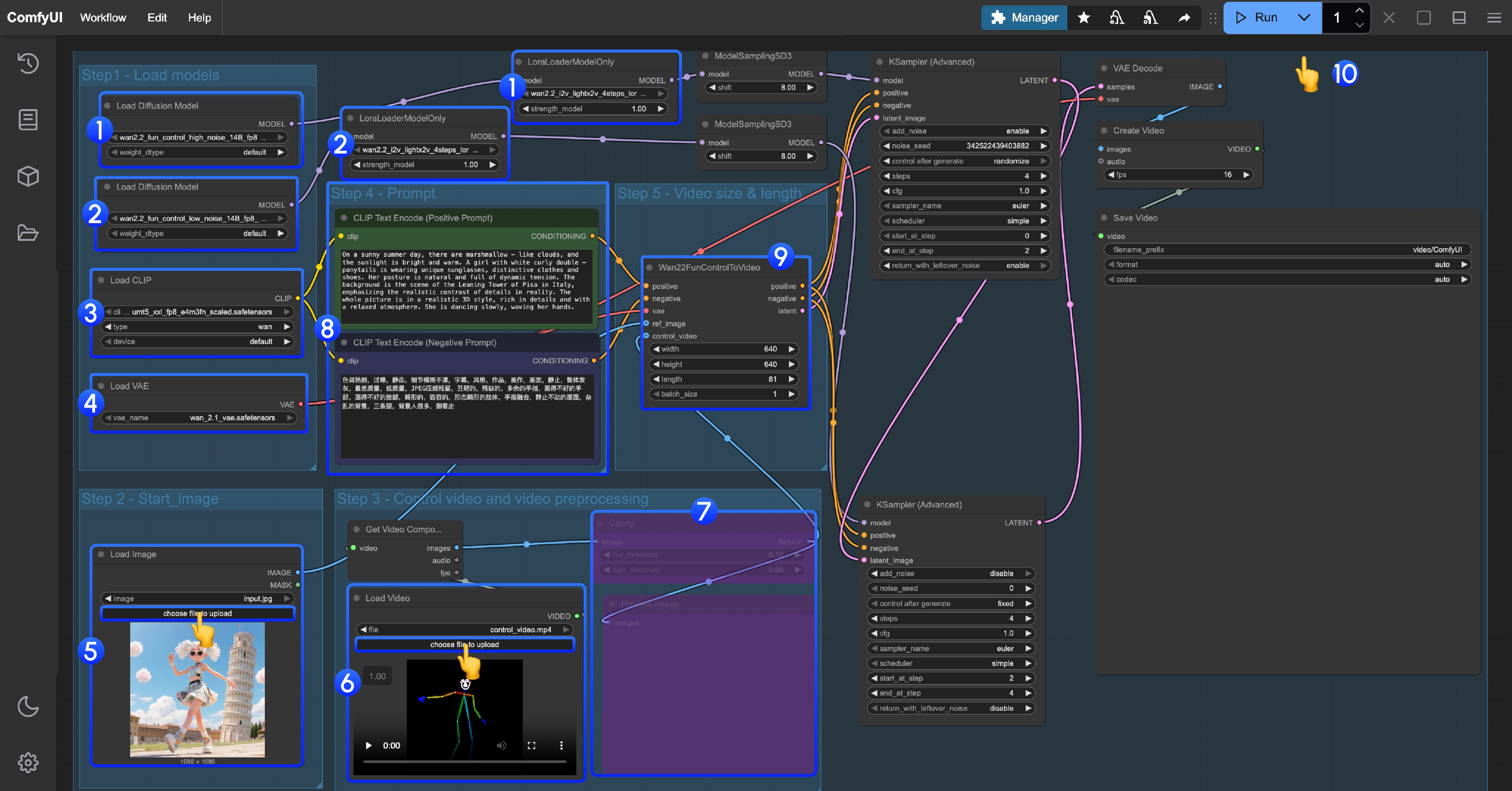
- High noise 模型及 LoRA 加载
- 确保
Load Diffusion Model节点加载了wan2.2_fun_control_high_noise_14B_fp8_scaled.safetensors模型 - 确保
LoraLoaderModelOnly节点加载了wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- Low noise 模型及 LoRA 加载
- 确保
Load Diffusion Model节点加载了wan2.2_fun_control_low_noise_14B_fp8_scaled.safetensors模型 - 确保
LoraLoaderModelOnly节点加载了wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
- 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 在
Load Image节点上传起始帧 - 在第二个
Load video节点控制视频的 pose 视频, 提供的视频已经经过预处理可以直接使用 - 由于我们提供的视频是预处理过的 pose 视频,所以对应的视频图像预处理节点需要禁用,你可以选中后使用 Ctrl + B` 来禁用
- 修改 Prompt 使用中英文都可以
- 在
Wan22FunControlToVideo修改对应视频的尺寸, 默认设置了 640*640 的分辨率来避免低显存用户使用这个工作流时过于耗时 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
补充说明
由于在 ComfyUI 自带的节点中,预处理器节点只有 Canny 的预处理器,你可以使用使用类似 ComfyUI-comfyui_controlnet_aux 来实现其它类型的图像预处理
Wan2.2 Fun Control Kijai WanVideoWrapper ComfyUI 工作流
此部分内容正在准备中,预计将在近期更新。
这部分教程将介绍使用 Kijai/ComfyUI-WanVideoWrapper 的便捷方式。
相关模型仓库:https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
Wan2.2 Fun Control GGUF 量化版 ComfyUI 工作流
此部分内容正在准备中,预计将在近期更新。
GGUF 版本适用于显存有限的用户,提供以下资源:
QuantStack/Wan2.2-Fun-A14B-Control-GGUF
相关自定义节点: City96/ComfyUI-GGUF
相关资源
Wan2.2 Fun 官方资源
社区资源
Wan2.2 Fun InP ComfyUI 工作流完整使用指南,官方+社区版本(Kijai, GGUF)工作流全攻略
教程总览
本教程将全面介绍 Wan2.2 Fun InP 首尾帧视频生成模型在 ComfyUI 中的各种实现方式和使用方法。Wan2.2 Fun InP 是阿里云推出的专业首尾帧控制视频生成模型,支持输入首帧和尾帧图像,生成中间过渡视频,为创作者带来更强的创意控制力。
本教程涵盖的版本和内容
已完成的版本:
- ✅ ComfyUI 官方原生版本 - 由 ComfyOrg 官方提供的完整工作流
- ✅ Wan2.2 Fun InP 14B 首尾帧版本 - 高质量首尾帧控制视频生成
正在准备中的版本:
- 🔄 Kijai WanVideoWrapper 版本 - 社区开发的便捷包装器
- 🔄 GGUF 量化版本 - 适用于低配置设备的优化版本
模型技术特点
Wan2.2 Fun InP 基于 Wan2.2 架构,专门针对首尾帧控制视频生成进行了优化,具备以下核心特性:
核心优势:
- 首尾帧控制:支持输入首帧和尾帧图像,生成中间过渡视频,提升视频连贯性与创意自由度
- 高质量视频生成:基于 Wan2.2 架构,输出影视级质量视频
- 多分辨率支持:支持生成512×512、768×768、1024×1024等分辨率的视频,适配不同场景需求
Wan2.2 Fun InP 系列模型基于 Apache2.0 开源协议,支持商业使用。Apache2.0 许可证允许您自由使用、修改和分发这些模型,包括商业用途,只需保留原始版权声明和许可证文本。
Wan2.2 Fun InP 开源模型版本概览
| 模型类型 | 模型名称 | 参数量 | 主要功能 | 模型仓库 |
|---|---|---|---|---|
| 首尾帧控制 | Wan2.2-Fun-A14B-InP | 14B | 支持输入首帧和尾帧图像,生成中间过渡视频,为创作者带来更强的创意控制力 | 🤗 Wan2.2-Fun-A14B-InP |
| 视频控制 | Wan2.2-Fun-A14B-Control | 14B | 支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制 | 🤗 Wan2.2-Fun-A14B-Control |
官方学习资源
相关代码仓库
- VideoX-Fun GitHub 仓库 - 官方提供的完整实现代码
- Wan2.2 Fun 官方文档 - 详细的模型说明和使用指南
Wan2.2 Fun InP ComfyUI 官方原生版本工作流使用指南
版本说明
ComfyUI 官方原生版本由 ComfyOrg 团队提供,使用重新打包的模型文件,确保与 ComfyUI 的最佳兼容性。该版本支持标准模式和 Lightx2v 4步 LoRA 加速模式。
性能对比测试
下面是使用 RTX4090D 24GB 显存 GPU 测试的结果 640*640 分辨率, 81 帧长度的用时对比:
| 模型类型 | 分辨率 | 显存占用 | 首次生成时长 | 第二次生成时长 |
|---|---|---|---|---|
| fp8_scaled | 640×640 | 83% | ≈ 524秒 | ≈ 520秒 |
| fp8_scaled + 4步LoRA加速 | 640×640 | 89% | ≈ 138秒 | ≈ 79秒 |
由于使用了加速 LoRA 后提速较为明显,虽然动态有所损失,但对低显存用户较为友好,所以在提供的两组工作流中,默认启用了使用了加速 LoRA 版本,如果你需要启用另一组的工作流,框选后使用 Ctrl+B 即可启用。
1. Wan2.2 Fun InP 首尾帧视频生成 ComfyUI 工作流
工作流获取方式
使用下面的素材作为首尾帧


模型文件下载
Diffusion Model
- wan2.2_fun_inpaint_high_noise_14B_fp8_scaled.safetensors
- wan2.2_fun_inpaint_low_noise_14B_fp8_scaled.safetensors
Lightning LoRA (可选,用于加速)
- wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
VAE
Text Encoder
操作步骤详解
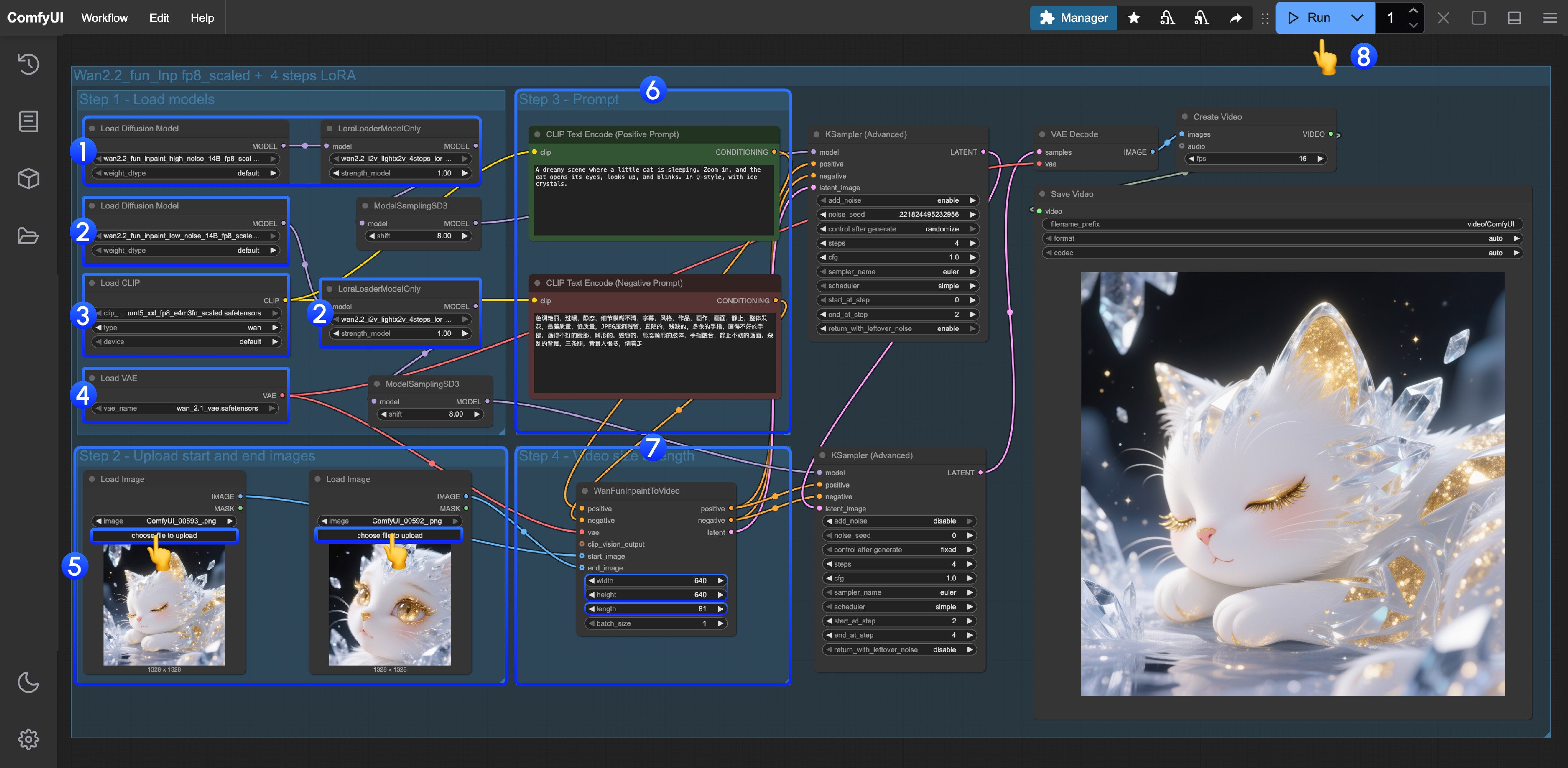
- High noise 模型及 LoRA 加载
- 确保
Load Diffusion Model节点加载了wan2.2_fun_inpaint_high_noise_14B_fp8_scaled.safetensors模型 - 确保
LoraLoaderModelOnly节点加载了wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- Low noise 模型及 LoRA 加载
- 确保
Load Diffusion Model节点加载了wan2.2_fun_inpaint_low_noise_14B_fp8_scaled.safetensors模型 - 确保
LoraLoaderModelOnly节点加载了wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
- 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 首尾帧图片上传,分别上传首尾帧图片素材
- 在 Prompt 组中输入提示词
WanFunInpaintToVideo节点尺寸和视频长度调整- 调整
width和height的尺寸,默认为640, 我们设置了较小的尺寸你可以按需进行修改 - 调整
length, 这里为视频总帧数,当前工作流 fps 为 16, 假设你需要生成一个 5 秒的视频,那么你应该设置 5*16 = 80
- 调整
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Wan2.2 Fun InP Kijai WanVideoWrapper ComfyUI 工作流
此部分内容正在准备中,预计将在近期更新。
这部分教程将介绍使用 Kijai/ComfyUI-WanVideoWrapper 的便捷方式。
相关模型仓库:https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
Wan2.2 Fun InP GGUF 量化版 ComfyUI 工作流
此部分内容正在准备中,预计将在近期更新。
GGUF 版本适用于显存有限的用户,提供以下资源:
QuantStack/Wan2.2-Fun-A14B-InP-GGUF
相关自定义节点: City96/ComfyUI-GGUF
title: Wan2.2-S2V 音频驱动视频生成 ComfyUI 工作流和教程 description: 使用 Wan2.2-S2V 在 ComfyUI 中创建音频同步视频的完整指南,包括模型设置、工作流配置和实际示例。 sidebarTitle: “Wan2.2 S2V” tag: video, wan2.2, audio-generation, tutorial
Wan2.2-S2V 音频驱动视频生成 ComfyUI 工作流和教程
Wan2.2-S2V 代表了 AI 视频生成技术的重大进步,能够从静态图像和音频输入创建动态视频内容。这一创新模型擅长生成具有自然唇同步的同步视频,对于处理对话场景、音乐表演和角色驱动叙事的内容创作者特别有价值。
模型亮点
- 音频驱动视频生成:将静态图像和音频转换为具有自然唇同步和表情的同步视频
- 电影级质量:生成具有真实面部表情、身体动作和镜头语言的电影质量视频
- 分钟级生成:支持单次生成长达分钟级的长格式视频创作
- 多格式支持:适用于真人、卡通、动物、数字人,并支持肖像、半身和全身格式
- 增强的动作控制:通过 AdaIN 和 CrossAttention 控制机制从文本指令生成动作和环境
- 高性能指标:实现 FID 15.66、CSIM 0.677 和 SSIM 0.734,提供卓越的视频质量和身份一致性
Wan2.2 S2V ComfyUI 原生工作流
1. 下载工作流文件
下载以下工作流文件并将其拖入 ComfyUI 以加载工作流。
下载以下图像和音频作为输入:

2. 模型链接
您可以在 我们的仓库 中找到这些模型
diffusion_models
audio_encoders
vae
text_encoders
3. 工作流说明
3.1 Lightning LoRA(可选,用于加速)
Lightning LoRA 将生成时间从 20 步减少到 4 步,但可能影响质量。用于快速预览,最终输出时禁用。
3.1.1 音频预处理提示
人声分离以获得更好效果:由于 ComfyUI 核心不包含人声分离节点,我们建议在处理前使用外部工具将人声与背景音乐分离。这对于对话和唇同步生成尤为重要,因为干净的人声轨道比混合了背景音乐或噪音的音频能产生明显更好的结果。
3.2 关于 fp8_scaled 和 bf16 模型
您可以在此处找到两个模型 here:
模板使用 wan2.2_s2v_14B_fp8_scaled.safetensors 以降低 VRAM 使用。尝试 wan2.2_s2v_14B_bf16.safetensors 以获得更好质量。
3.3 逐步操作说明
步骤 1: 加载模型
- 加载扩散模型:加载
wan2.2_s2v_14B_fp8_scaled.safetensors或wan2.2_s2v_14B_bf16.safetensors- 工作流使用
wan2.2_s2v_14B_fp8_scaled.safetensors以降低 VRAM 需求 - 使用
wan2.2_s2v_14B_bf16.safetensors以获得更好质量的输出
- 工作流使用
- 加载 CLIP:加载
umt5_xxl_fp8_e4m3fn_scaled.safetensors - 加载 VAE:加载
wan_2.1_vae.safetensors - AudioEncoderLoader:加载
wav2vec2_large_english_fp16.safetensors - LoraLoaderModelOnly:加载
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors(Lightning LoRA)- 此 LoRA 可减少生成时间但可能影响质量
- 如果输出质量不足请禁用
- LoadAudio:上传提供的音频文件或您自己的音频
- Load Image:上传参考图像
- 批处理大小:根据 Video S2V Extend 子图节点数量设置
- 每个 Video S2V Extend 子图添加 77 帧到输出
- 示例:2 个 Video S2V Extend 子图 = 批处理大小 3
- 块长度:保持默认值 77
- 采样器设置:根据 Lightning LoRA 使用情况选择
- 使用 4 步 Lightning LoRA:steps: 4, cfg: 1.0
- 不使用 Lightning LoRA:steps: 20, cfg: 6.0
- 尺寸设置:设置输出视频尺寸
- Video S2V Extend:视频扩展子图节点
- 每个扩展生成 77 / 16 = 4.8125 秒视频
- 计算所需节点:音频长度(秒)× 16 ÷ 77
- 示例:14 秒音频 = 224 帧 ÷ 77 = 3 个扩展节点
- 使用 Ctrl-Enter 或点击运行按钮执行工作流
相关链接
- Wan2.2 S2V 代码:GitHub
- Wan2.2 S2V 模型:Hugging Face