Stable Zero 123 Conditioning|SZ123条件
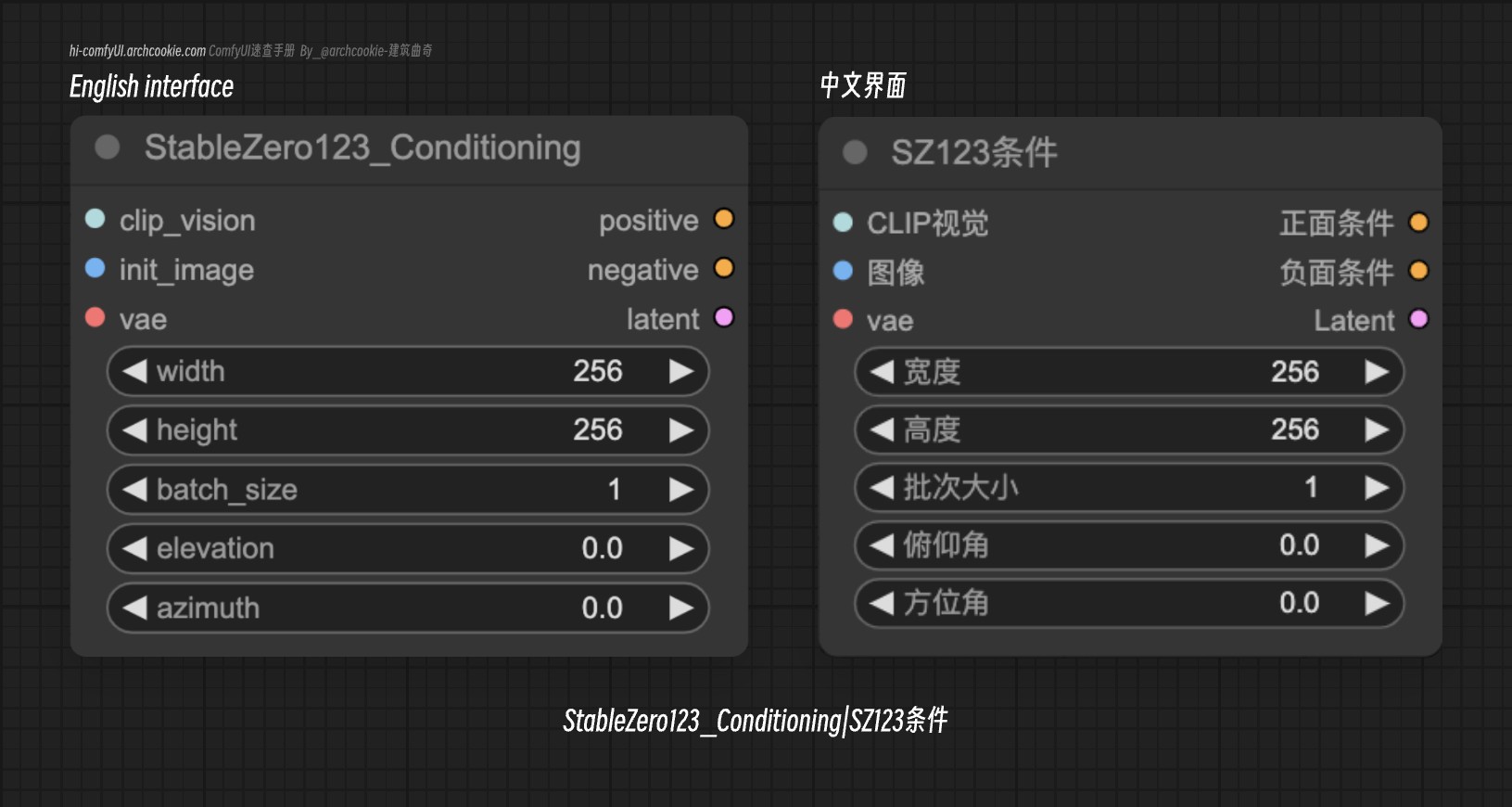
此节点设计用于处理和为StableZero123模型使用的条件数据,专注于以特定格式准备输入,这些格式与这些模型兼容并经过优化。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip_vision | CLIP_VISION | 处理视觉数据以符合模型要求,增强模型对视觉上下文的理解。 |
init_image | IMAGE | 作为模型的初始图像输入,为进一步基于图像的操作设定基线。 |
vae | VAE | 集成变分自编码器输出,促进模型生成或修改图像的能力。 |
width | INT | 指定输出图像的宽度,允许根据模型需求动态调整大小。 |
height | INT | 确定输出图像的高度,实现输出尺寸的定制化。 |
batch_size | INT | 控制单批次处理的图像数量,优化计算效率。 |
elevation | FLOAT | 调整3D模型渲染的仰角,增强模型的空间理解。 |
azimuth | FLOAT | 修改3D模型可视化的方位角,改善模型对方向的感知。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 生成正面条件向量,帮助模型加强正面特征。 |
negative | CONDITIONING | 产生负面条件向量,协助模型避免某些特征。 |
latent | LATENT | 创建潜在表示,促进模型对数据的深入理解。 |
Stable Zero 123 Conditioning Batched|SZ123条件(批次)
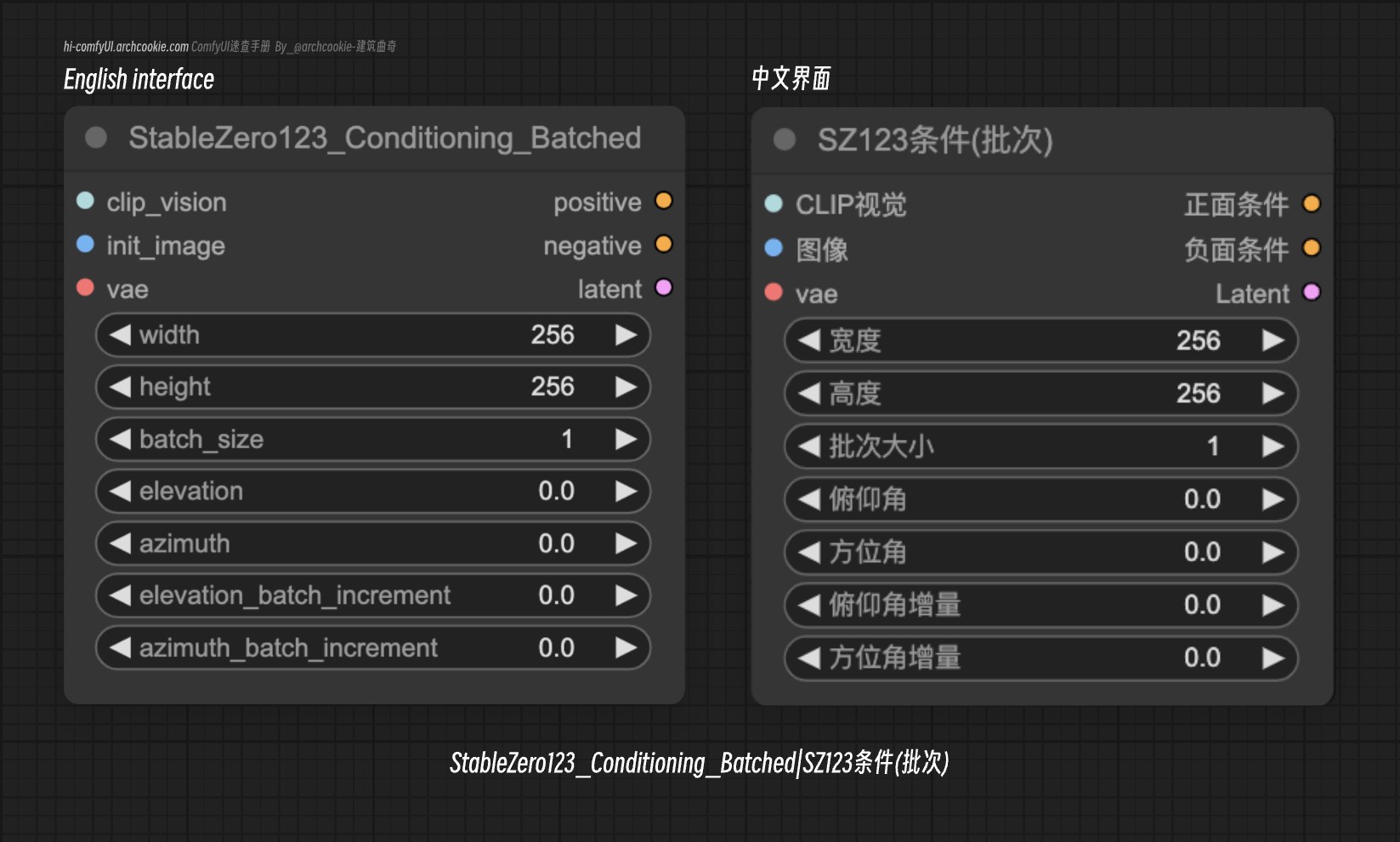
此节点专为StableZero123模型设计,以批量方式处理条件信息。它专注于同时高效处理多组条件数据,为批量处理至关重要的场景优化工作流程。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip_vision | CLIP_VISION | 提供条件过程的视觉上下文的CLIP视觉嵌入。 |
init_image | IMAGE | 要进行条件处理的初始图像,作为生成过程的起点。 |
vae | VAE | 用于条件过程中编码和解码图像的变分自编码器。 |
width | INT | 输出图像的宽度。 |
height | INT | 输出图像的高度。 |
batch_size | INT | 单批次中要处理的条件集数量。 |
elevation | FLOAT | 3D模型条件的仰角,影响生成图像的视角。 |
azimuth | FLOAT | 3D模型条件的方位角,影响生成图像的方向。 |
elevation_batch_increment | FLOAT | 仰角在批量中的增量变化,允许不同的视角。 |
azimuth_batch_increment | FLOAT | 方位角在批量中的增量变化,允许不同的方向。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 正面条件输出,专为促进生成内容中的某些特征或方面而定制。 |
negative | CONDITIONING | 负面条件输出,专为降低生成内容中的某些特征或方面而定制。 |
latent | LATENT | 来自条件过程的潜在表示,可供进一步处理或生成步骤使用。 |
CLIP Set Last Layer - CLIP设置停止层
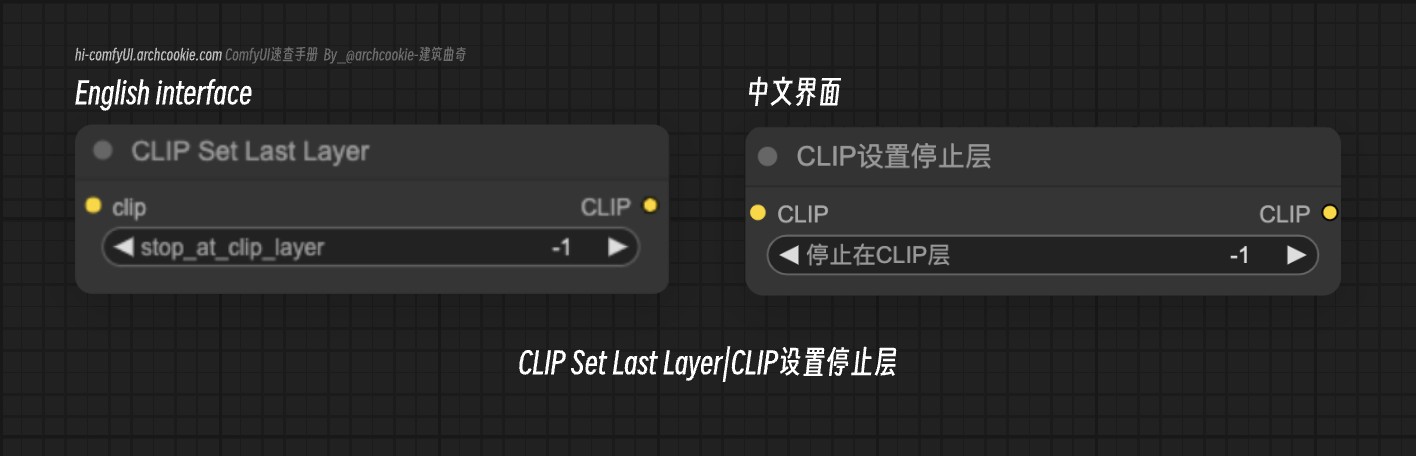
文档说明
- 节点名称:
CLIP设置停止层 - 类别:
条件 - 输出节点:
False
此节点旨在通过设置特定层为最后执行层来修改CLIP模型的行为。它允许自定义CLIP模型内处理的深度,通过限制处理的信息量,可能影响模型的输出。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip | CLIP | 要修改的CLIP模型。此参数允许节点直接与CLIP模型交互并改变其结构。 |
stop_at_clip_layer | INT | 指定CLIP模型应停止处理的层。这样可以控制计算的深度,并且可以用来调整模型的行为或性能。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip | CLIP | 已修改的CLIP模型,指定的层被设置为最后一层。此输出使得可以进一步使用或分析调整后的模型。 |
CLIP Text Encode(prompt) - CLIP文本编码器
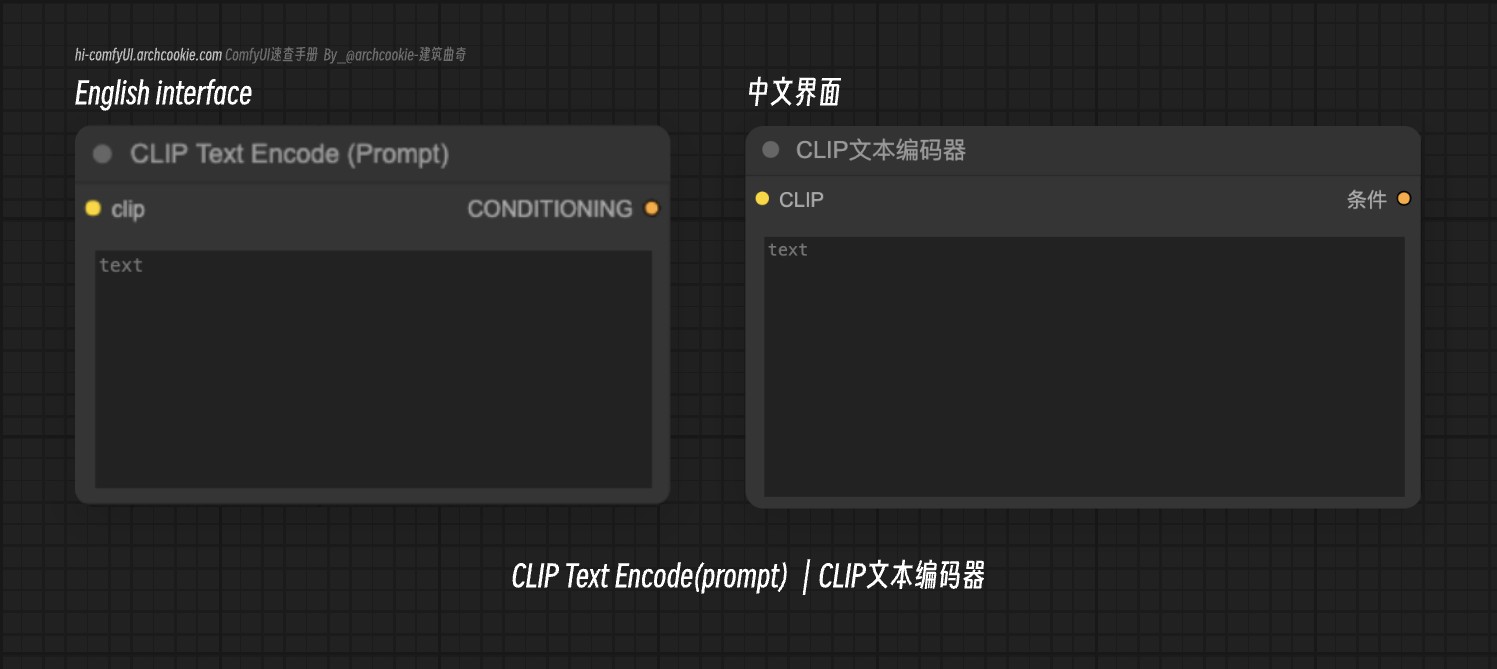
文档说明
- 类名:
CLIP文本编码 - 类别:
条件 - 输出节点:
False
这个节点主要通过输入Prompt(文本提示词),通过CLIP模型对输入的文本进行编码,生成一个嵌入向量,用来引导diffusion model扩散模型生成符合文本条件图像
除了正常的文本提示词之外也可以用于输入 embedding 模型,比如你在对应的模型目录 ComfyUI/models/embeddings 下添加了 embedding 模型,那么你就可以在提示词中使用这个 embedding 模型。
假设对应的模型名称为EasyNegative,那么你可以在提示词中使用 embedding:EasyNegative, 来使用这个对应的模型
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
text | STRING | text 参数是要编码的文本输入。它在确定输出条件向量中起着关键作用,因为它是编码过程的主要信息源。 |
clip | CLIP | clip 参数代表用于文本标记化和编码的CLIP模型。它对于将文本输入转换为条件向量至关重要,影响生成输出的质量和相关性。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 输出的conditioning是由CLIP模型编码的输入文本的向量表示。它作为指导生成模型产生相关和连贯输出的关键组件。 |
CLIP Vision Encode - CLIP视觉编码
文档说明
- 类名:
CLIP视觉编码 - 类别:
条件 - 输出节点:
False
CLIP视觉编码节点旨在使用CLIP视觉模型对图像进行编码,将视觉输入转换为适合进一步处理或分析的格式。该节点抽象了图像编码的复杂性,提供了一个简化的接口,用于将图像转换为编码表示。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip_vision | CLIP_VISION | 用于编码图像的CLIP视觉模型。它对编码过程至关重要,因为它决定了编码的方法和质量。 |
image | IMAGE | 要编码的图像。此输入对于生成视觉内容的编码表示至关重要。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip_vision_output | CLIP_VISION_OUTPUT | 由CLIP视觉模型生成的输入图像的编码表示。此输出适合于进一步的处理或分析。 |
Conditioning Average - 条件平均
文档说明
- 类名:
条件平均 - 类别:
条件 - 输出节点:
False此节点设计用于混合两组条件数据,根据指定的强度应用加权平均。这一过程允许动态调整条件影响,便于微调生成的内容或特征。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning_to | CONDITIONING | 表示将应用混合的主要条件数据集。它作为加权平均操作的基础。 |
conditioning_from | CONDITIONING | 表示将混合到主要数据集中的次要条件数据集。此数据基于指定的强度影响最终输出。 |
conditioning_to_strength | FLOAT | 标量值,用于确定主要和次要条件数据之间混合的强度。它直接影响加权平均的平衡。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 混合主要和次要条件数据的结果,产生一组新的条件,反映了加权平均。 |
Conditioning(Combine) - 条件合并
.jpg)
文档说明
- 类名:
条件合并 - 类别:
条件 - 输出节点:
False
此节点将两个条件输入组合成单个输出,有效地合并它们的信息。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning_1 | CONDITIONING | 要组合的第一个条件输入。在组合过程中与conditioning_2扮演同等重要角色。 |
conditioning_2 | CONDITIONING | 要组合的第二个条件输入。在合并过程中与conditioning_1同等重要。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 组合conditioning_1和conditioning_2的结果,封装了合并后的信息。 |
Conditioning (Concat) - 条件联结
.jpg)
文档说明
- 类名:
条件联结 - 类别:
条件 - 输出节点:
False
此节点设计用于连接条件向量,特别是将’conditioning_from’向量合并到’conditioning_to’向量中。在需要将来自两个源的条件信息组合成单一、统一表示的场景中,此操作是基础。
想象一下,你在做一道菜,conditioning_to 是基本的食谱,而 conditioning_from 是一些额外的调料或佐料。ConditioningConcat 类就像是一个帮你把这些调料加入食谱的工具,让你的菜肴更加丰富多彩。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning_to | CONDITIONING | 表示’conditioning_from’向量将被连接到的主要条件向量集。它作为连接过程的基础。 |
conditioning_from | CONDITIONING | 包含要连接到’conditioning_to’向量的条件向量。此参数允许将额外的条件信息集成到现有的集。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 输出是统一的条件向量集,由’conditioning_from’向量连接到’conditioning_to’向量的结果。 |
Conditioning(Set Area) - 条件采样区域
.jpg)
文档说明
- 类名:
条件采样区域 - 类别:
条件 - 输出节点:
False
此节点设计用于通过在条件上下文中设置特定区域来修改条件信息。它允许对条件元素进行精确的空间操作,根据指定的尺寸和强度实现有针对性的调整和增强。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 要修改的条件数据。它作为应用空间调整的基础。 |
width | INT | 指定要在条件上下文中设置的区域的宽度,影响调整的水平范围。 |
height | INT | 确定要设置的区域的高度,影响条件修改的垂直范围。 |
x | INT | 要设置的区域的水平起始点,定位条件上下文中的调整。 |
y | INT | 区域调整的垂直起始点,确定其在条件上下文中的位置。 |
strength | FLOAT | 定义指定区域内条件修改的强度,允许对调整的影响进行精细控制。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 修改后的条件数据,反映了指定区域设置和调整。 |
Conditioning(Set Area With Percentage) - 按系数设置条件采样区域
.jpg)
文档说明
- 类名:
按系数设置条件采样区域 - 类别:
条件 - 输出节点:
False条件采样区域百分比设置节点专门用于根据百分比值调整条件元素的影响区域。它允许指定区域的尺寸和位置作为总图像尺寸的百分比,以及一个强度参数来调节条件效果的强度。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 表示要修改的条件元素,作为应用区域和强度调整的基础。 |
width | FLOAT | 指定区域的宽度,作为总图像宽度的百分比,影响条件水平上影响图像的程度。 |
height | FLOAT | 确定区域的高度,作为总图像高度的百分比,影响条件影响的垂直范围。 |
x | FLOAT | 表示区域的水平起始点,作为总图像宽度的百分比,定位条件效果。 |
y | FLOAT | 指定区域的垂直起始点,作为总图像高度的百分比,定位条件效果。 |
strength | FLOAT | 控制指定区域内条件效果的强度,允许微调其影响。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 返回具有更新的区域和强度参数的修改后条件元素,准备进行进一步处理或应用。 |
条件设置区域强度

文档
- 类名:
条件设置区域强度 - 类别:
条件 - 输出节点:
False
此节点旨在修改给定条件集的强度属性,允许调整条件对生成过程的影响或强度。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 要修改的条件集,代表影响生成过程的当前条件状态。 |
strength | FLOAT | 要应用于条件集的强度值,决定其影响的强度。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 修改后的条件集,每个元素的强度值已更新。 |
Conditioning(Set Mask) - 条件设置遮罩
.jpg)
文档说明
- 类名:
条件设置遮罩 - 类别:
条件 - 输出节点:
False
此节点设计通过应用具有指定强度的遮罩来修改生成模型的条件,允许对条件内的特定区域进行有针对性的调整,从而实现对生成过程更精确的控制。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 要修改的条件数据。它作为应用遮罩和强度调整的基础。 |
mask | MASK | 一个遮罩张量,指定要在其中修改的条件区域。 |
strength | FLOAT | 遮罩对条件的影响强度,允许对应用的修改进行微调。 |
set_cond_area | COMBO[STRING] | 确定遮罩的效果是应用于默认区域还是由遮罩本身限定,提供在定位特定区域方面的灵活性。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 应用了遮罩和强度调整的修改后条件数据。 |
Apply ControlNet 应用ControlNet节点

此节点将 ControlNet 应用于给定的图像和条件,根据控制网络的参数和指定的强度调整图像的属性,比如 Depth、OpenPose、Canny、HED等等。
Apply ControlNet 文档说明
- 类名:
ControlNet应用 - 类别:
条件 - 输出节点:
False
使用 controlNet 要求对输入图像进行预处理,由于ComfyUI 初始节点不带处理器和 controlNet 模型,所以请先安装ContrlNet预处理器这里下载与处理器和contrlNet 对应的模型。
Apply ControlNet 输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 正向条件数据,来自CLIP文本编码器或者其它条件输入 |
negative | CONDITIONING | 负向条件数据,来自CLIP文本编码器或者其它条件输入 |
control_net | CONTROL_NET | 要应用的controlNet模型,通常输入来自 controlNt加载器 |
image | IMAGE | 用于 controlNet 应用的图片,需要经过预处理器处理 |
vae | VAE | Vae模型输入 |
strength | FLOAT | 用来控制网络调整的强度,取值0~10。建议取值在0.5~1.5之间比较合理,越小则模型会发挥越高的自由度,越大则会被限制得越严格,过高会出现很诡异的画面。你也可以通过自己测试来调整这个值,用来微调控制网络对图像产生的影响。 |
start_percent | FLOAT | 取值 0.000~1.000,确定开始应用controlNet的百分比,比如取值0.2,意味着ControlNet的引导将在扩散过程完成20%时开始影响图像生成 |
end_percent | FLOAT | 取值 0.000~1.000,确定结束应用controlNet的百分比,比如取值0.8,意味着ControlNet的引导将在扩散过程完成80%时停止影响图像生成 |
Apply ControlNet 输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 经过ControlNet 处理后的正向条件数据,可以输出到下一个ControlNet 或者 K采样器等节点 |
negative | CONDITIONING | 经过ControlNet 处理后的负向条件数据,可以输出到下一个ControlNet 或者 K采样器等节点 |
ComfyUI ControlNet 使用示例
访问下面的页面查看示例
- ComfyUI OpenPose controlNet使用示例
- ComfyUI Depth controlNet使用示例
- ComfyUI Canny controlNet使用示例
- ComfyUI Multi ControlNet使用示例
相关资源
- 模型资源:controlNet模型资源下载
- 预处理器插件:ComfyUI ControlNet Auxiliary Preprocessors
Apply ControlNet (OLD) 旧版本节点说明
 这个节点为早期版本的 Apply ControlNet 节点,目前节点相关选项已更新,为了保证兼容性在 ComfyUI 中如果你下载了使用旧版本节点的工作流则会显示为此节点,你可以更换为新的 Apply ControlNet 节点。
这个节点为早期版本的 Apply ControlNet 节点,目前节点相关选项已更新,为了保证兼容性在 ComfyUI 中如果你下载了使用旧版本节点的工作流则会显示为此节点,你可以更换为新的 Apply ControlNet 节点。
Apply ControlNet (OLD) 输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
条件 | CONDITIONING | 条件数据,来自CLIP文本编码器或者其它条件输入(如另一个条件节点的输入) |
control_net | CONTROL_NET | 要应用的controlNet模型,通常输入来自 controlNt加载器 |
image | IMAGE | 用于 controlNet 应用的图片,需要经过预处理器处理 |
强度 | FLOAT | 用来控制网络调整的强度,取值0~10。建议取值在0.5~1.5之间比较合理,越小则模型会发挥越高的自由度,越大则会被限制得越严格,过高会出现很诡异的画面。你也可以通过自己测试来调整这个值,用来微调控制网络对图像产生的影响。 |
Apply ControlNet (OLD) 输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
条件 | CONDITIONING | 经过ControlNet 处理后的条件数据,可以输出到下一个ControlNet 或者 K采样器等节点 |
Apply ControlNet(advance) - ControlNet
文档说明
- 类名:
ControlNet应用高级 - 类别:
条件 - 输出节点:
False此节点基于图像和控制网模型对条件数据应用高级控制网变换。它允许对控制网对生成内容的影响进行微调调整,从而对条件进行更精确和多样化的修改。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 将应用控制网变换的正面条件数据。它代表在生成内容中增强或保持的期望属性或特征。 |
negative | CONDITIONING | 负面条件数据,代表要从生成内容中减少或移除的属性或特征。控制网变换也应用于这些数据,允许平衡调整内容的特性。 |
control_net | CONTROL_NET | 控制网模型对于定义条件数据的具体调整和增强至关重要。它解释参考图像和强度参数以应用变换,通过修改正面和负面条件数据中的属性,显著影响最终输出。 |
image | IMAGE | 作为控制网变换的参考图像。它影响控制网对条件数据的调整,引导特定特征的增强或抑制。 |
strength | FLOAT | 标量值,确定控制网对条件数据的影响强度。更高的值会导致更显著的调整。 |
start_percent | FLOAT | 控制网效果的起始百分比,允许在指定范围内逐步应用变换。 |
end_percent | FLOAT | 控制网效果的结束百分比,定义变换应用的范围。这允许对调整过程进行更微妙的控制。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 应用控制网变换后的修改正面条件数据,反映了基于输入参数所做增强。 |
negative | CONDITIONING | 应用控制网变换后的修改负面条件数据,反映了基于输入参数对特定特征的抑制或移除。 |
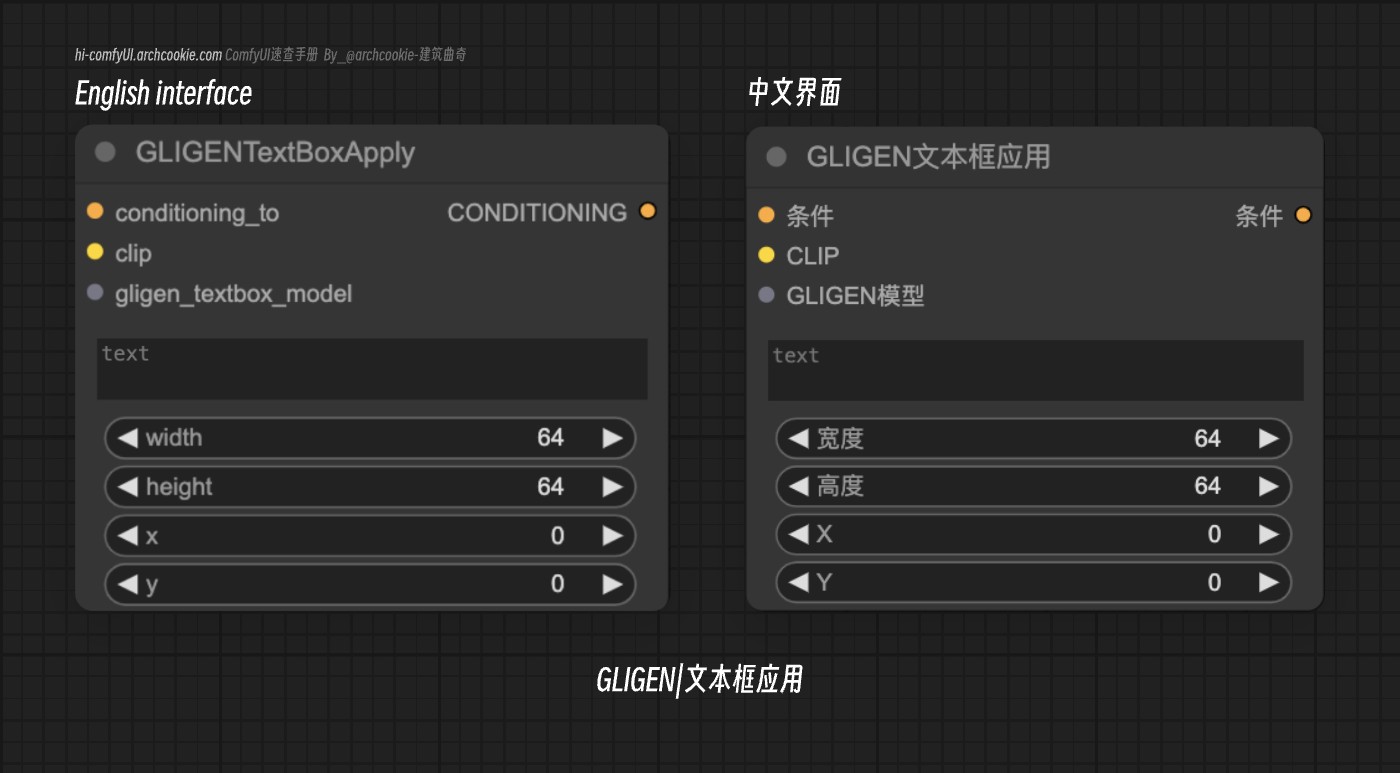
GLIGEN Text Box Apply GLIGEN|文本框应用
文档说明
- 类名:
GLIGENTextBoxApply - 分类:
conditioning/gligen - 输出节点:
False
GLIGENTextBoxApply 节点旨在将基于文本的条件信息整合到生成模型的输入中,具体做法是应用文本框参数并使用 CLIP 模型对其进行编码。这个过程通过空间和文本信息丰富了条件信息,从而促进了更精确和上下文感知的生成。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning_to | CONDITIONING | 指定初始条件输入,文本框参数和编码后的文本信息将附加于此。它通过整合新的条件数据,在确定最终输出中起着关键作用。 |
clip | CLIP | 用于将提供的文本编码为生成模型可以使用的格式的 CLIP 模型。它对于将文本信息转换为兼容的条件格式至关重要。 |
gligen_textbox_model | GLIGEN | 表示要用于生成文本框的特定 GLIGEN 模型配置。它对于确保根据所需的规格生成文本框至关重要。 |
text | STRING | 要编码并整合到条件中的文本内容。它提供了指导生成模型的语义信息。 |
width | INT | 文本框的宽度,以像素为单位。它定义了文本框在生成图像中的空间尺寸。 |
height | INT | 文本框的高度,以像素为单位。与宽度类似,它定义了文本框在生成图像中的空间尺寸。 |
x | INT | 文本框在生成图像内左上角的 x 坐标。它指定了文本框的水平位置。 |
y | INT | 文本框在生成图像内左上角的 y 坐标。它指定了文本框的垂直位置。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 丰富的条件输出,包括原始条件数据以及新附加的文本框参数和编码后的文本信息。它用于指导生成模型产生上下文感知的输出。 |
inpaint Model Conditioning|内补模型条件-ComfyUI节点

文档
- 类名:
修复模型条件 - 类别:
条件/修复 - 输出节点:
False
修复模型条件节点旨在简化修复模型的条件处理过程,允许集成和操作各种条件输入以定制修复输出。它包含了一系列功能,从加载特定的模型检查点和应用风格或控制网络模型,到对条件元素进行编码和组合,因此作为定制修复任务的全面工具。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 表示应用于修复模型的正面条件信息或参数。此输入对于定义修复操作应执行的上下文或约束至关重要,对最终输出有显著影响。 |
negative | CONDITIONING | 表示应用于修复模型的负面条件信息或参数。此输入对于指定修复过程中要避免的条件或上下文至关重要,因此影响最终输出。 |
vae | VAE | 指定在条件处理过程中使用的VAE模型。此输入对于确定将使用的VAE模型的具体架构和参数至关重要。 |
pixels | IMAGE | 表示要进行修复的图像的像素数据。此输入对于提供修复任务所需的视觉上下文至关重要。 |
mask | MASK | 指定要应用于图像的遮罩,指示需要进行修复的区域。此输入对于定义图像中需要修复的特定区域至关重要。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 处理后的修改正面条件信息,准备应用于修复模型。此输出对于根据指定的正面条件指导修复过程至关重要。 |
negative | CONDITIONING | 处理后的修改负面条件信息,准备应用于修复模型。此输出对于根据指定的负面条件指导修复过程至关重要。 |
latent | LATENT | 从条件处理过程派生的潜在表示。此输出对于理解正在修复的图像的底层特征和特性至关重要。 |
Apply Style model-风格模型应用

文档说明
- 类名:
StyleModelApply - 分类:
条件/风格模型 - 输出节点:
否此节点将风格模型应用于给定的条件,基于CLIP视觉模型的输出增强或改变其风格。它将风格模型的条件整合到现有条件中,允许在生成过程中风格无缝融合。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 原始条件数据,用于对文本进行编码的CLIP模型将应用风格模型的条件。它对于定义将被增强或改变的基础上下文或风格至关重要。 |
style_model | STYLE_MODEL | 用于基于CLIP视觉模型的输出生成新条件的风格模型。它在定义要应用的新风格中起着关键作用。 |
clip_vision_output | CLIP_VISION_OUTPUT | 来自CLIP视觉模型的输出,风格模型用它来生成新条件。它为风格应用提供了必要的视觉上下文。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 增强或改变的条件,融入了风格模型的输出。它代表了最终的风格化条件,准备进行进一步处理或生成。 |
unCLIP Conditioning - unCLIP条件
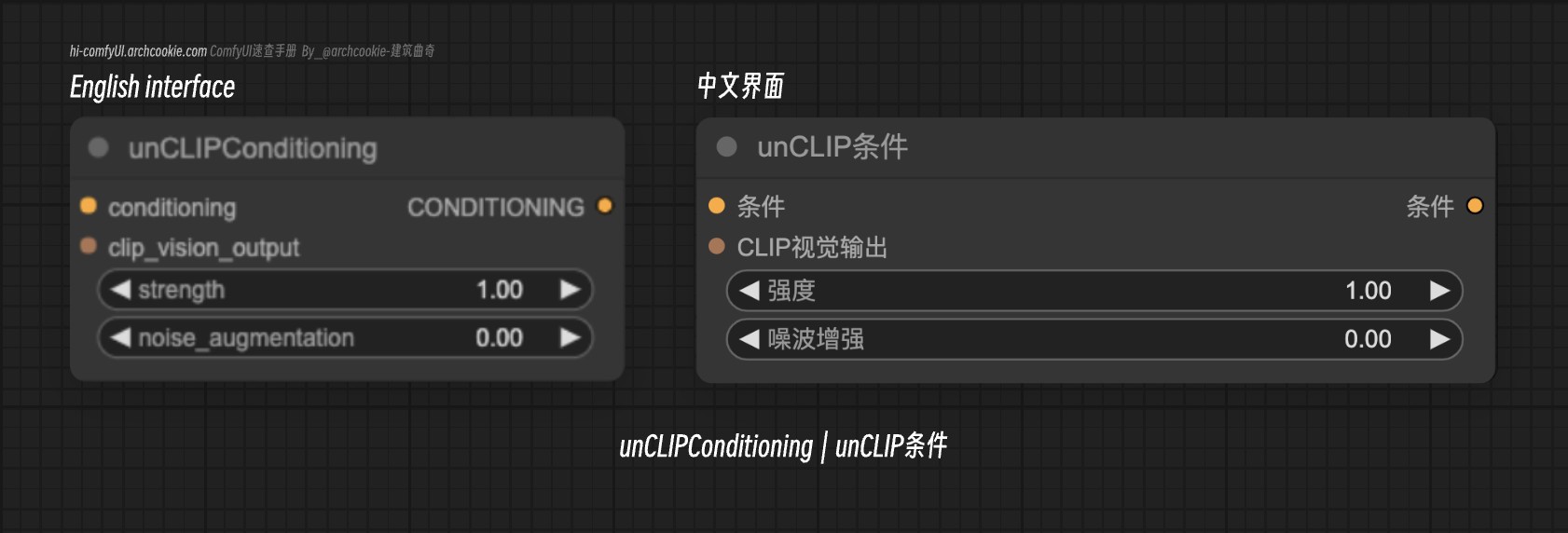
文档说明
- 类名:
unCLIP条件 - 类别:
条件 - 输出节点:
False此节点设计用于将CLIP视觉输出整合到条件过程中,根据指定的强度和噪声增强参数调整这些输出的影响。它通过视觉上下文丰富了条件,增强了生成过程。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 基础条件数据,将向其添加CLIP视觉输出,作为进一步修改的基础。 |
clip_vision_output | CLIP_VISION_OUTPUT | 来自CLIP视觉模型的输出,提供被整合进条件的视觉上下文。 |
strength | FLOAT | 确定CLIP视觉输出对条件影响的强度。 |
noise_augmentation | FLOAT | 指定在将CLIP视觉输出整合进条件之前应用的噪声增强水平。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
conditioning | CONDITIONING | 丰富的条件数据,现在包含已应用强度和噪声增强的整合CLIP视觉输出。 |
SD_4X Upscale Conditioning|SD4X放大条件

文档说明
- 类名:
SD_4X放大条件 - 类别:
条件/放大扩散 - 输出节点:
False此节点专门通过4倍放大过程增强图像分辨率,同时结合条件元素来细化输出。它利用扩散技术在放大图像的同时,允许调整缩放比率和噪声增强,以微调增强过程。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
images | IMAGE | 要放大的输入图像。此参数至关重要,因为它直接影响输出图像的质量和分辨率。 |
positive | CONDITIONING | 正面条件元素,指导放大过程朝着输出图像中的期望属性或特征发展。 |
negative | CONDITIONING | 负面条件元素,放大过程应避免这些元素,有助于引导输出远离不希望的属性或特征。 |
scale_ratio | FLOAT | 确定图像分辨率增加的因子。更高的缩放比率会产生更大的输出图像,允许更详细和清晰的细节。 |
noise_augmentation | FLOAT | 控制放大过程中应用的噪声增强水平。这可以用来引入变异性并提高输出图像的鲁棒性。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 放大过程后得到的精细正面条件元素。 |
negative | CONDITIONING | 放大过程后得到的精细负面条件元素。 |
latent | LATENT | 在放大过程中生成的潜在表示,可用于进一步处理或模型训练。 |
SVD img2vid Conditioning|SVD_图像到视频_条件-ComfyUI节点
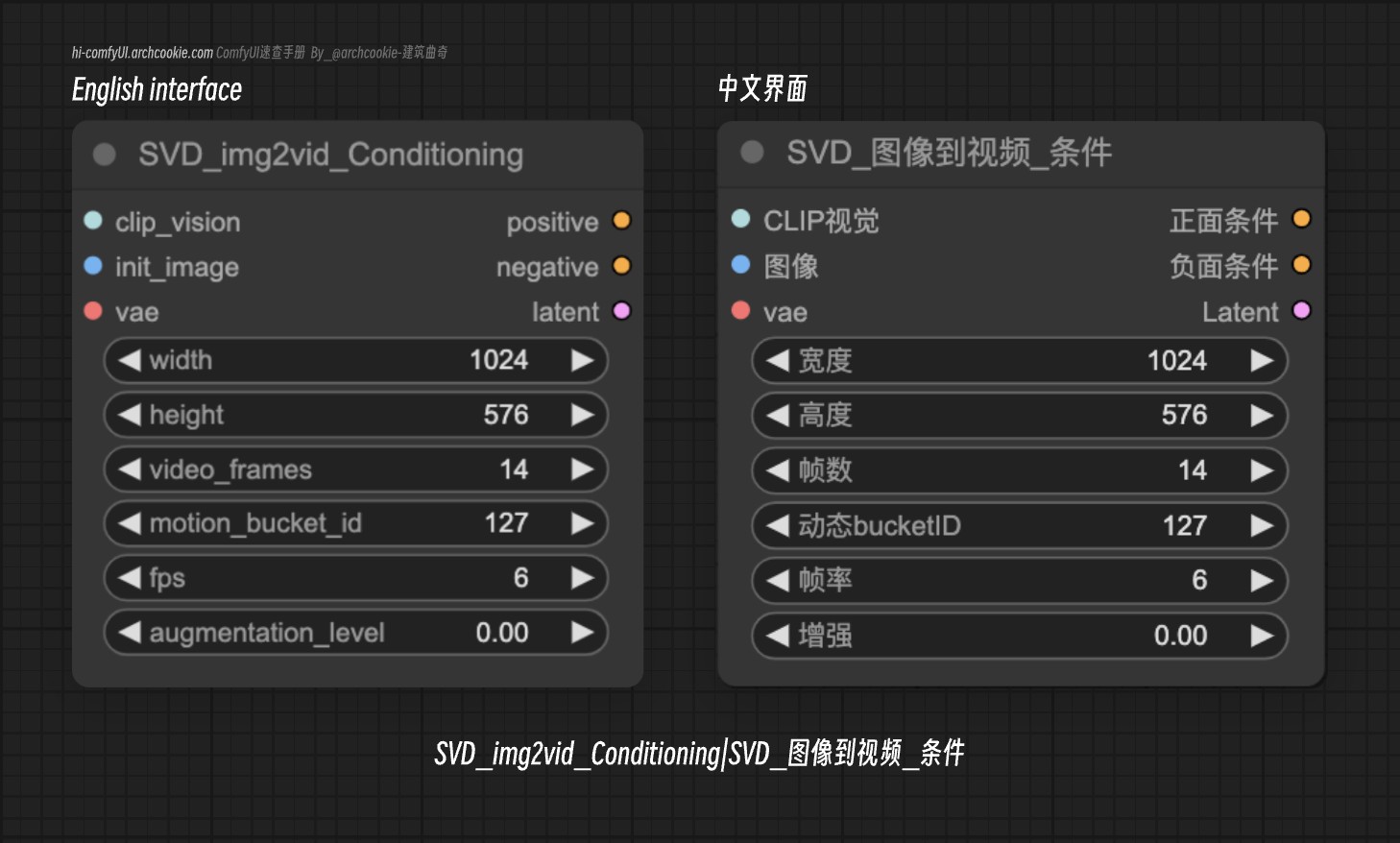
文档说明
- 类名:
SVD_img2vid_条件 - 类别:
条件/视频模型 - 输出节点:
False
此节点旨在为视频生成任务生成条件数据,特别适用于SVD_img2vid模型。它接受各种输入,包括初始图像、视频参数和VAE模型,以产生可用于指导视频帧生成的条件数据。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip_vision | CLIP_VISION | 用于从初始图像编码视觉特征的CLIP视觉模型,对理解图像内容和视频生成上下文至关重要。 |
init_image | IMAGE | 视频将从中生成的初始图像,作为视频生成过程的起点。 |
vae | VAE | 用于将初始图像编码到潜在空间的变分自编码器(VAE)模型,有助于生成连贯和连续的视频帧。 |
width | INT | 要生成的视频帧的期望宽度,允许自定义视频的分辨率。 |
height | INT | 要生成的视频帧的高度,可以控制视频的宽高比和分辨率。 |
video_frames | INT | 为视频生成的帧数,决定视频的长度。 |
motion_bucket_id | INT | 用于分类将要应用的视频生成中运动类型的标识符,有助于创造动态和吸引人的视频。 |
fps | INT | 视频的每秒帧数(fps),影响生成视频的平滑度和真实感。 |
augmentation_level | FLOAT | 控制应用于初始图像的增强水平的参数,影响生成视频帧的多样性和可变性。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 正面条件数据,由编码特征和参数组成,指导视频生成过程朝着期望的方向发展。 |
negative | CONDITIONING | 负面条件数据,与正面条件形成对比,可用于避免生成视频中的某些模式或特征。 |
latent | LATENT | 为视频中的每一帧生成的潜在表示,作为视频生成过程的基础组成部分。 |
ComfyUI WanFunControlToVideo 节点
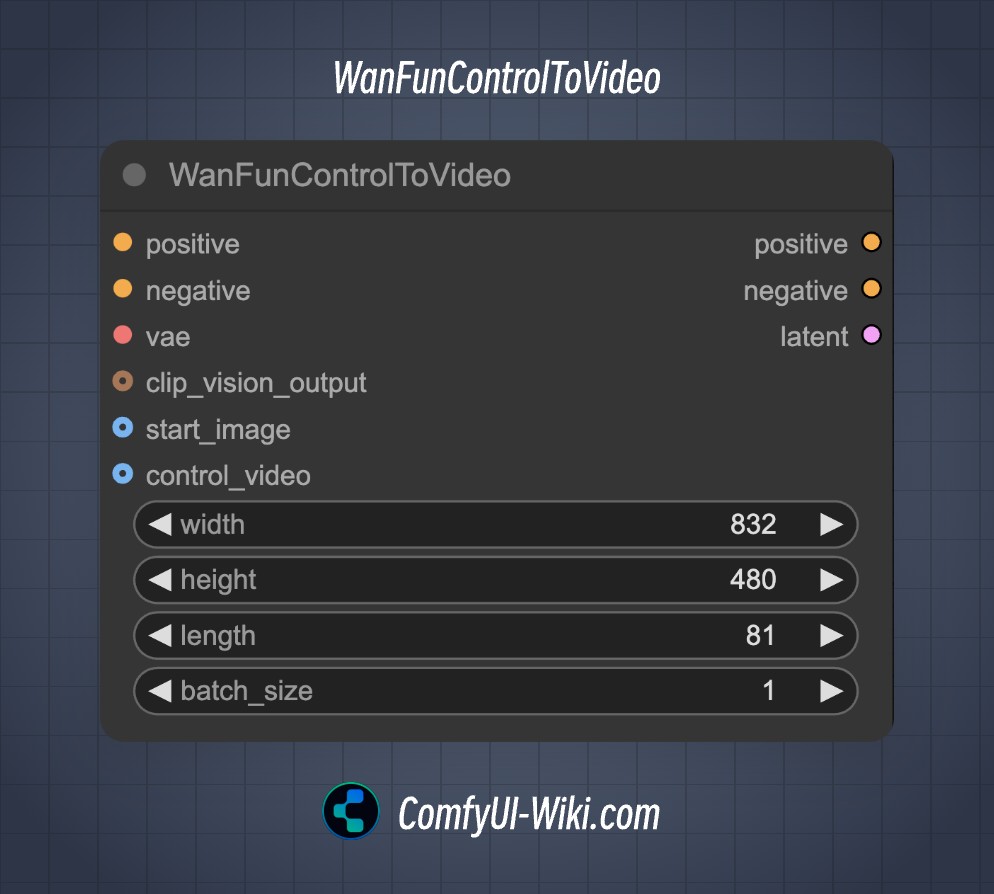
该节点是为了支持阿里巴巴的 Wan Fun Control 模型而添加的,用于视频生成,并在 此提交 之后添加。
- 目的: 准备使用 Wan 2.1 Fun Control 模型进行视频生成所需的条件信息。
WanFunControlToVideo 节点是 ComfyUI 的一个附加功能,旨在支持用于视频生成的 Wan Fun Control 模型,旨在利用 WanFun 控制进行视频创作。
该节点作为准备必要条件信息的起点,并初始化潜在空间的中心点,指导后续使用 Wan 2.1 Fun 模型的视频生成过程。节点的名称清楚地表明了其功能:它接受各种输入并将其转换为适合在 WanFun 框架内控制视频生成的格式。
该节点在 ComfyUI 节点层次结构中的位置表明,它在视频生成管道的早期阶段操作,专注于在实际采样或解码视频帧之前操纵条件信号。
WanFunControlToVideo 节点详细分析
输入参数
| 参数名称 | 必需 | 数据类型 | 描述 | 默认值 |
|---|---|---|---|---|
| positive | 是 | CONDITIONING | 标准 ComfyUI 正条件数据,通常来自“CLIP Text Encode”节点。正提示描述用户设想的生成视频的内容、主题和艺术风格。 | N/A |
| negative | 是 | CONDITIONING | 标准 ComfyUI 负条件数据,通常由“CLIP Text Encode”节点生成。负提示指定用户希望在生成视频中避免的元素、风格或伪影。 | N/A |
| vae | 是 | VAE | 需要与 Wan 2.1 Fun 模型系列兼容的 VAE(变分自编码器)模型,用于编码和解码图像/视频数据。 | N/A |
| width | 是 | INT | 输出视频帧的期望宽度(以像素为单位),默认值为 832,最小值为 16,最大值由 nodes.MAX_RESOLUTION 决定,步长为 16。 | 832 |
| height | 是 | INT | 输出视频帧的期望高度(以像素为单位),默认值为 480,最小值为 16,最大值由 nodes.MAX_RESOLUTION 决定,步长为 16。 | 480 |
| length | 是 | INT | 生成视频中的总帧数,默认值为 81,最小值为 1,最大值由 nodes.MAX_RESOLUTION 决定,步长为 4。 | 81 |
| batch_size | 是 | INT | 一次生成的视频数量,默认值为 1,最小值为 1,最大值为 4096。 | 1 |
| clip_vision_output | 否 | CLIP_VISION_OUTPUT | (可选)由 CLIP 视觉模型提取的视觉特征,允许进行视觉风格和内容指导。 | 无 |
| start_image | 否 | IMAGE | (可选)影响生成视频开头的初始图像。 | 无 |
| control_video | 否 | IMAGE | (可选)允许用户提供经过预处理的 ControlNet 参考视频,以指导生成视频的运动和潜在结构。 | 无 |
输出参数
| 参数名称 | 数据类型 | 描述 |
|---|---|---|
| positive | CONDITIONING | 提供增强的正条件数据,包括编码的 start_image 和 control_video。 |
| negative | CONDITIONING | 提供同样增强的负条件数据,包含相同的 concat_latent_image。 |
| latent | LATENT | 一个字典,包含一个空的潜在张量,键为“samples”。 |
节点示例工作流
请访问 Wan Fun Control 节点示例工作流程 以了解 ComfyUI 如何原生支持 Wan Fun Control 模型。
节点源代码
节点源代码,代码版本 3661c833bcc41b788a7c9f0e7bc48524f8ee5f82
encode 函数分析
WanFunControlToVideo 节点中的 encode 函数负责将输入参数转换为条件信息和潜在空间,这些信息将被后续的视频生成模型使用。
该函数首先初始化一个名为 latent 的空潜在张量,具有特定的形状:[batch_size, 16, ((length - 1) // 4) + 1, height // 8, width // 8]。该张量被放置在 comfy.model_management.intermediate_device() 上,通常是可用的 GPU。接下来,另一个与 latent 形状相同的潜在张量 concat_latent 被初始化,用于存储来自可选的 start_image 和 control_video 输入的编码信息。
在处理可选的视觉输入后,concat_latent 张量现在包含来自 start_image 和 control_video(如果提供)的编码信息,并通过 node_helpers.conditioning_set_values 函数将其添加到正向和负向条件信息中的 “concat_latent_image” 键下。
最后,函数检查是否提供了 clip_vision_output。如果提供了,它也会被添加到正向和负向条件中的 “clip_vision_output” 键下。这使得由 CLIP 模型提取的视觉特征能够进一步优化生成过程。
额外的 Wan Fun Control 相关内容
WanFun Control 主要与 Wan 2.1 模型系列一起使用。该方法受到 ControlNet 的启发,ControlNet 是一种广泛用于图像生成的强大技术,通过各种空间和结构输入来调节输出。WanFun Control 将这些原则扩展到视频的时间域,使用户能够对生成的视频内容产生较高的影响,超越纯文本驱动方法的局限。它利用从输入视频中提取的视觉信息(例如深度图、边缘轮廓(Canny)或人体姿势(OpenPose))来促进受控视频的创建。
Wan 2.1 模型系列是 WanFun Control 的基础,提供了包括 1.3B 和 14B 模型在内的不同参数变体,为用户提供了在计算资源与所需输出质量和复杂性之间取得平衡的选项。
WanFun Control 的基本概念是利用参考视频中的视觉线索来指导 AI 的创作过程。用户可以提供一个“控制视频”,该视频体现了所需的运动或空间排列,而不仅仅依赖文本提示来确定生成视频的运动、结构和风格。这使得创建具有特定特征的视频变得更加直接和直观。例如,用户可能提供一个人走路的视频,而 WanFun Control 系统将生成一个不同主体执行相同走路动作的新视频,同时遵循文本提示中对主体外观和整体场景的描述。这种将视觉数据与文本描述相结合的结构化视频生成方法,能够实现更高的运动准确性、改善的风格化效果以及更有意图的视觉转换能力。