安装好 ComfyUI 之后要如何运行?
在开始这个教程之前:
- 请先确保你已经安装好了 ComfyUI
- 你的 ComfyUI 中至少应该有一个 chekcpoint 模型,如果你仅仅是为了测试能否正常运行软件,这个步骤可以省略
如果你还没有安装 ComfyUI,请先按照 ComfyUI 安装指南 进行安装,并且对应章节也已经将对应的首次生成图片的细节讲解完了
这里的教程将以 Windows 版本的 ComfyUI 为例。
ComfyUI Desktop 桌面版
如果你是用 ComfyUI Desktop 桌面版,你可以直接双击桌面上的 ComfyUI 图标来启动 ComfyUI
使用 ComfyUI Portable 官方便携版本如何启动 ComfyUI
如果你使用的是 ComfyUI 官方整合包,那么在对应的文件夹下你应该可以找到如下文件
根据你的情况选择 run_cpu.bat 或者 run_nvidia_gpu.bat 来运行程序
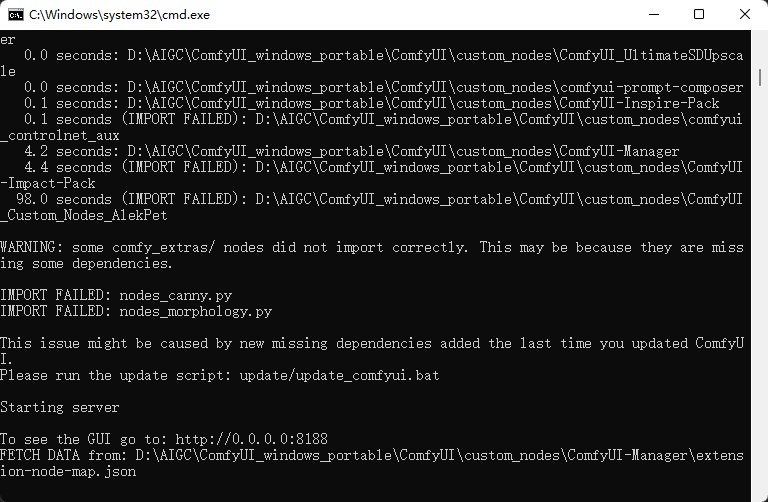 如上图,当你看到
如上图,当你看到
则说明 ComfyUI 已经成功启动,如果浏览器没有正常启动,你可以通过浏览器访问To See the GUI go to: 后的网址直接访问,如在上面的例子中应该是 http://192.168.3.58:8188
使用秋叶启动器如何启动 ComfyUI
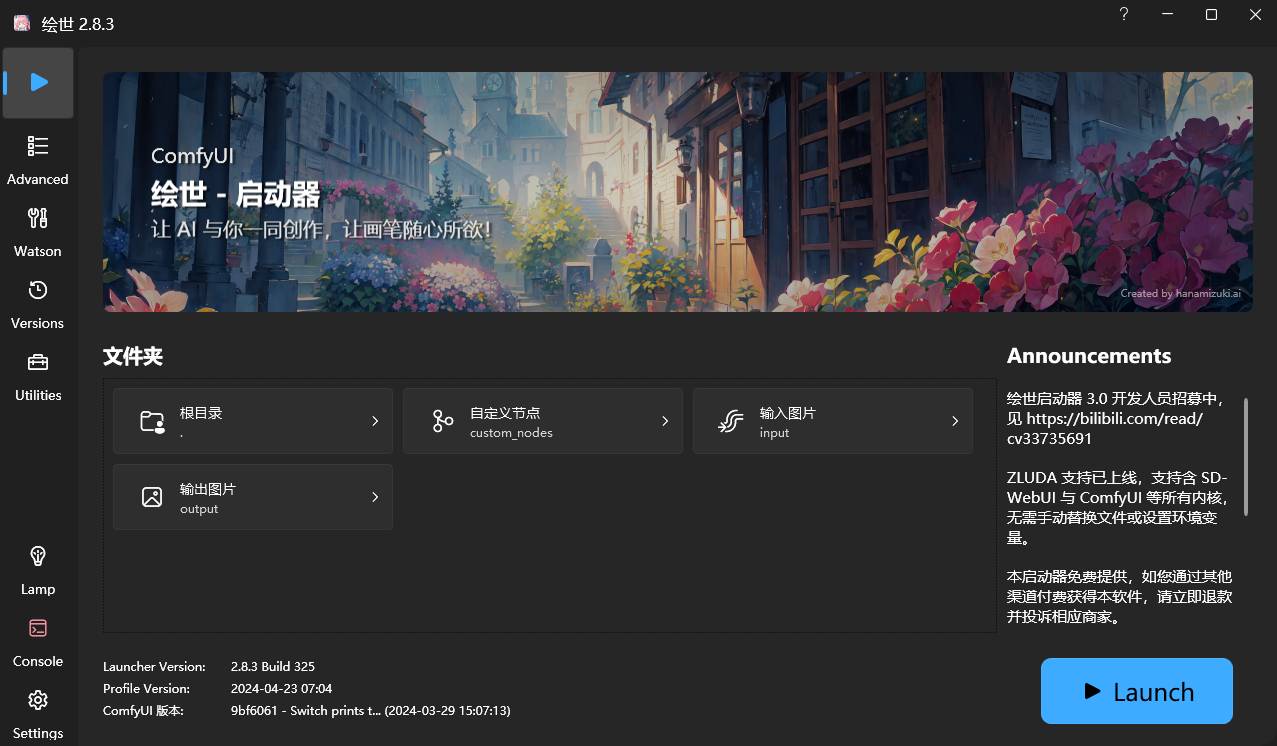
点击启动器首页中的右下角蓝色图标 ▶︎一键启动 即可一键启动 ComfyUI,如果运行无误应该会自动为你打开 控制台 为你运行相关脚本
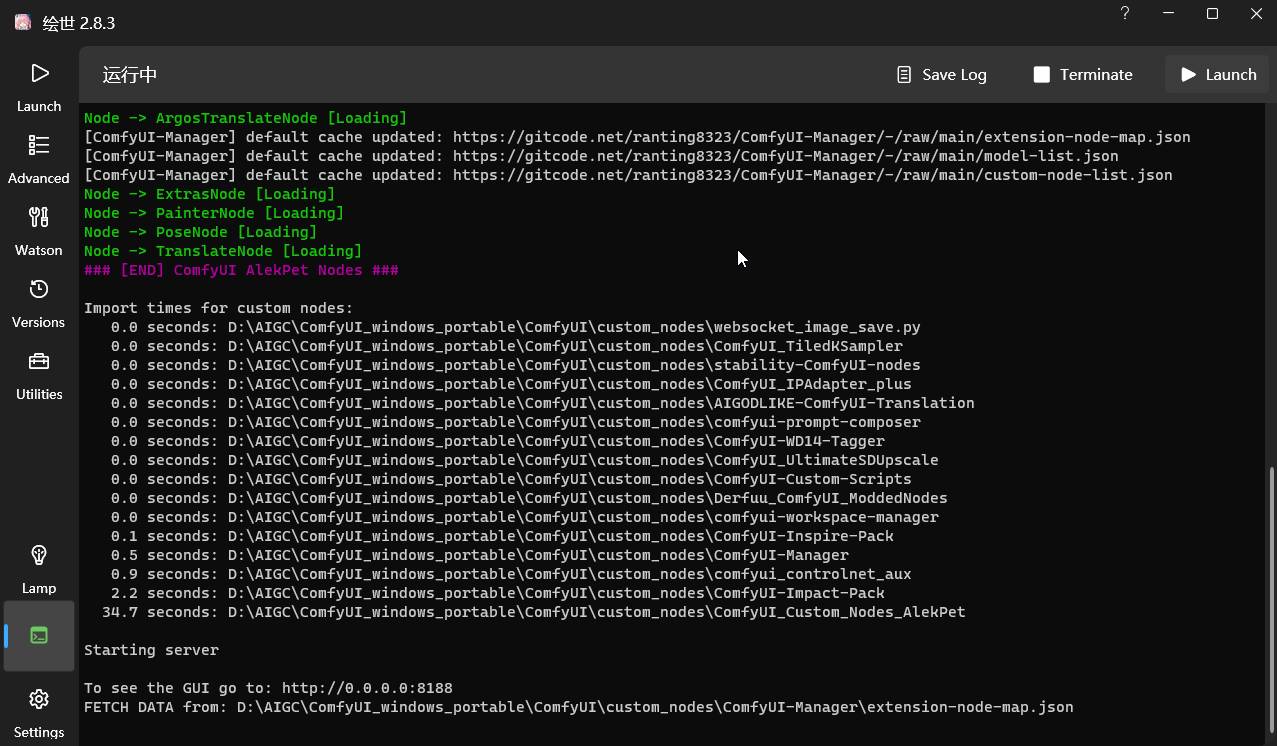
如上图,当你看到
则说明 ComfyUI 已经成功启动,如果浏览器没有正常启动,你可以通过浏览器访问To See the GUI go to: 后的网址直接访问,如在上面的例子中应该是 http://192.168.3.58:8188
如何在局域网内其它的设备访问当前运行的 ComfyUI 服务
如果你的 ComfyUI 已经在局域网内的设备部署,其设备想要访问当前设备的服务,不同客户端的访问方式有所不同 不过具体的教程我在 如何在局域网中访问 ComfyUI 中有详细说明,你可以参考对应部分的说明进行设置
ComfyUI 文生图教程,进行第一次的图片生成
本篇将指导你进行第一张图片的生成,我们将进行文本到图片的生成,请确保你已经完成对应的准备工作
准备工作
在开始这个教程之前:
- 请先确保你已经安装好了 ComfyUI,如果你还没有安装请先按照 ComfyUI 安装指南 进行安装
- 你的 ComfyUI 中至少应该有一个 chekcpoint 模型
如果你没有安装对应的模型,我推荐你从以下模型开始(选择其中一个就可以了):
下面以官方便携版为例,我们需要把下载到的模型存放到对应的文件夹
如果你需要了解详情说明可以参考ComfyUI 如何安装 SD 模型
- 确定你已经启动了 ComfyUI 服务,如果没有启动请参考 启动 ComfyUI 服务 进行启动
加载 ComfyUI 预设的文生图工作流
在运行 ComfyUI 之后如果没有加载默认的工作流,请参考下面图片的步骤加载 ComfyUI 默认的文生图工作流
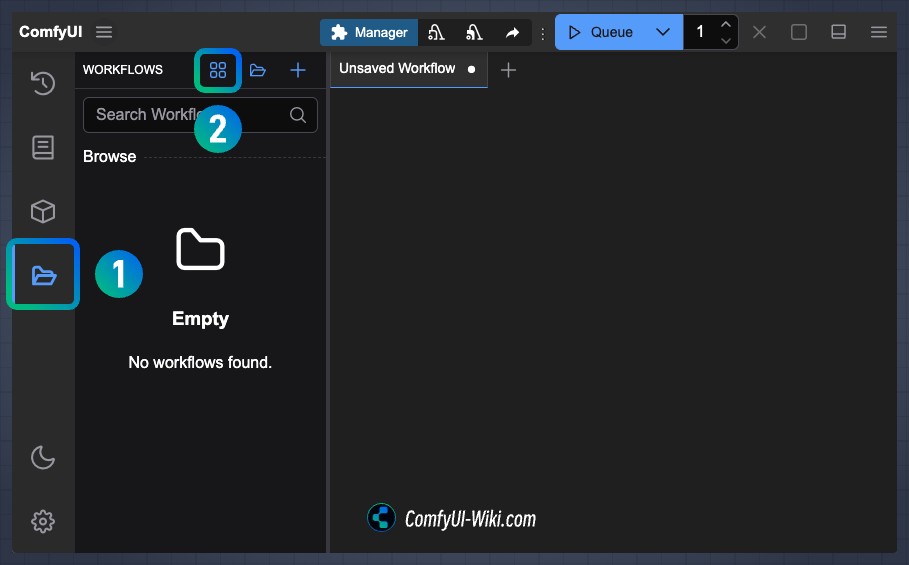
- 点击侧边栏的
Workflow面板 - 点击进入浏览工作流模板
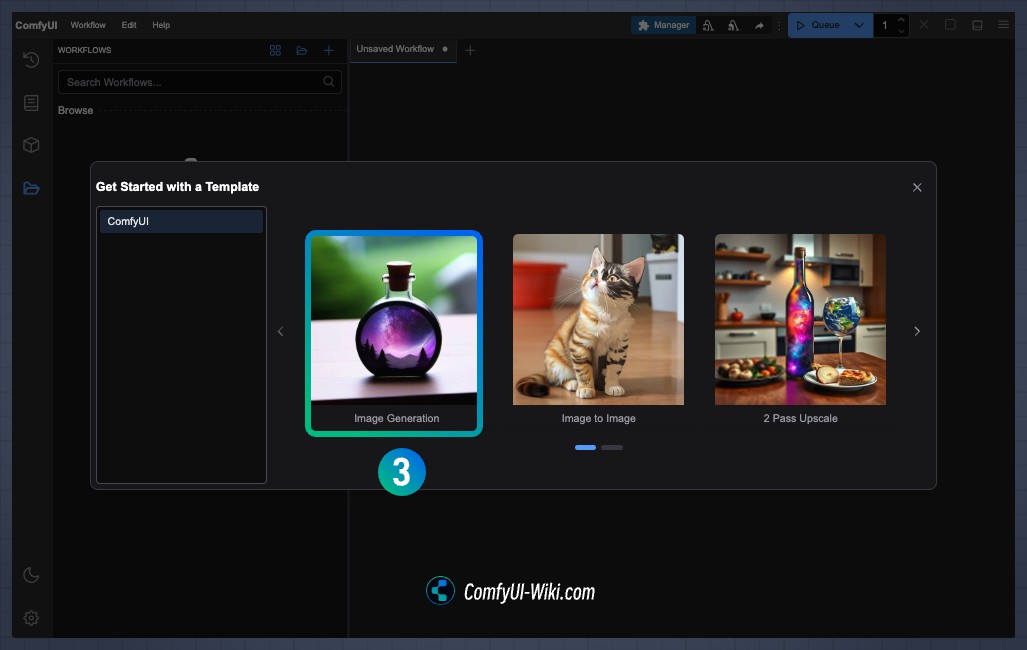
- 默认工作流模板中选择
Image Generation加载默认的工作流
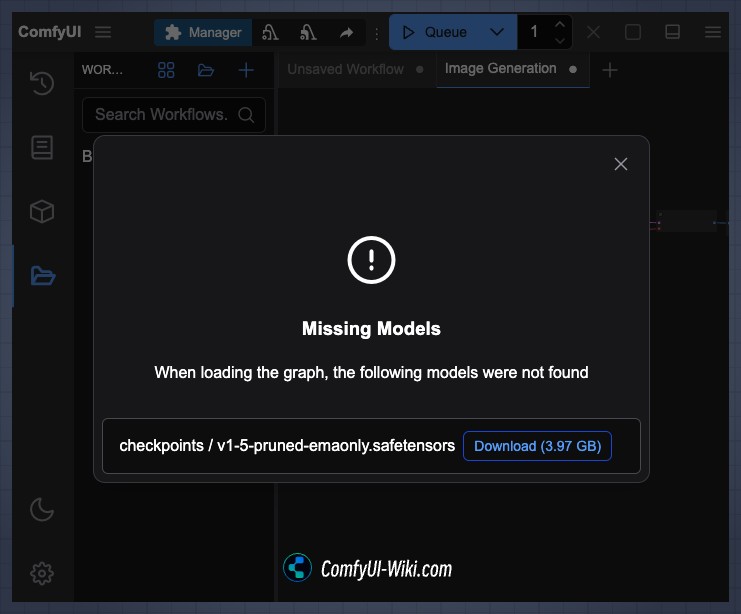
- 如果你出现了这个弹窗提示
- 如果你有按我的建议自己下载了模型并进行安装,那么你可以忽略关闭这个弹窗
- 如果你没有下载任何模型文件,你可以选择 点击
DownloadComfyUI 会自动为你下载对应的模型文件到对应文件夹
加载模型并进行图片生成
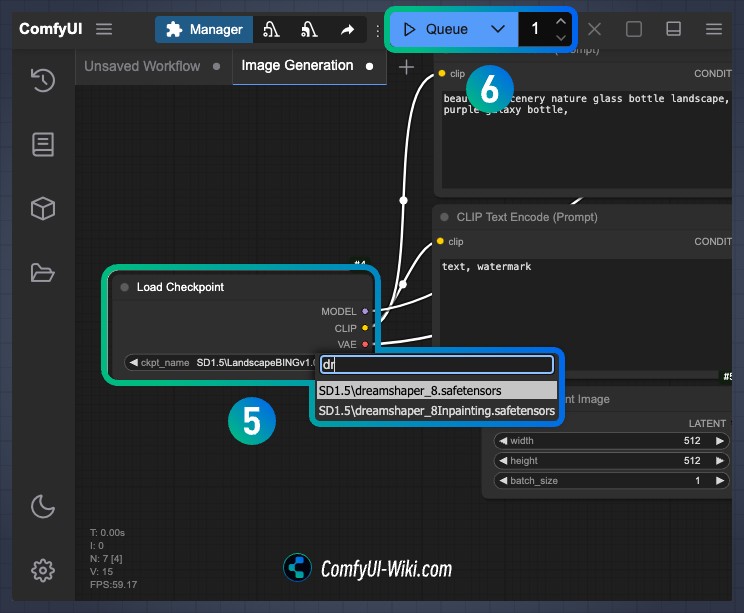
- 在工作流加载完成后,请鼠标缩放到 Load checkpoint 的位置,在
ckpt_name中选择你需要的模型文件,可以使用右键或者使用对应节点的箭头进行操作选择模型文件。 - 点击
Run进行图片生成
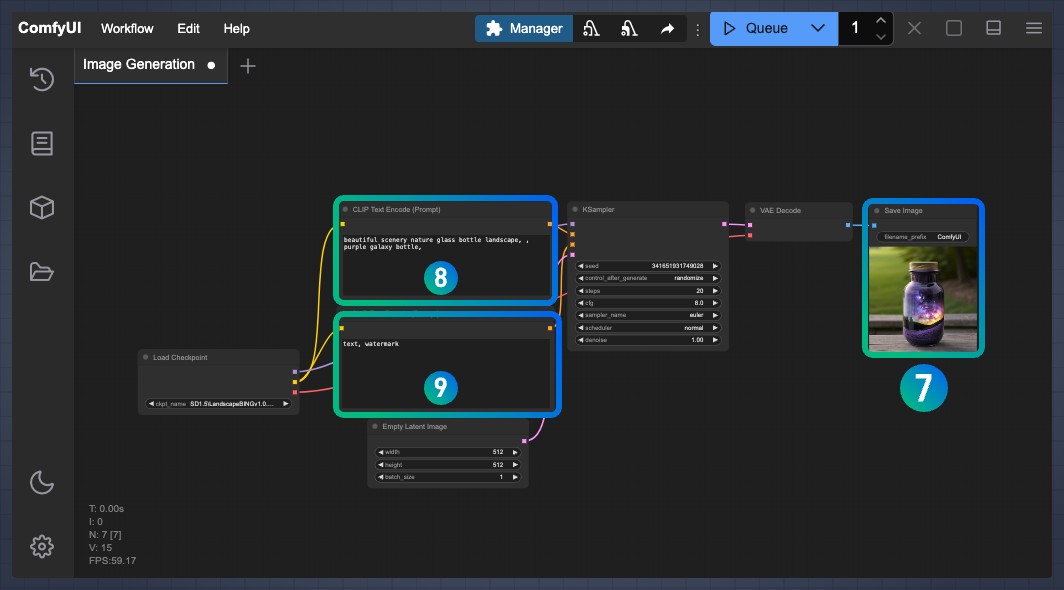
- 如果一切无误,你可以在 Save Image 节点上看到生成的图片,你可以右键将对应图片保存到本地或者查看
ComfyUI/output文件夹下看看有没有其它的图片
你可以继续尝试修改提示词节点 CLIP Text Encode,看看不同提示词带来的效果
8. 因为它连接到的是[Ksampler](/zh/comfyui-nodes/sampling/k-sampler)节点的 positive 输入,所以在这里的文本框输入的内容是你想要在画面中出现的内容
9. 因为它连接到的是[Ksampler](/zh/comfyui-nodes/sampling/k-sampler)节点的 negative 输入,所以在这里的文本框输入的内容是你不想要在画面中出现的内容
修改8和9处的内容,进行不同类型内容的尝试
关于提示词你可以查看: ComfyUI提示词基础语法tips
ComfyUI 与其它 Stable diffusion AI绘图 WebUI 要如何共享绘图模型?自定义模型位置
本文将指导你如何将 ComfyUI 与其它 WebUI 程序共享绘图模型或者如何使用设置自定义的模型存储位置的设置 本文将针对以下两个版本进行说明:
- ComfyUI Desktop 桌面版(Comfy.org 最新推出的桌面端)
- ComfyUI Portable 便携版(最早的 ComfyUI 便携版)
Desktop 桌面版和 Portable 便携版 的配置逻辑基本相同,但是原始提供的 example 文件内容有所差异,下面将分别进行说明
ComfyUI Desktop 桌面版如何配置与 A1111 共享绘图模型
在 ComfyUI Desktop 桌面版中,extra_model_paths.yaml 你可以在启动 ComfyUI Desktop 桌面版后,帮助 -> 打开文件夹 -> Open extra_model_paths.yaml 菜单中找到
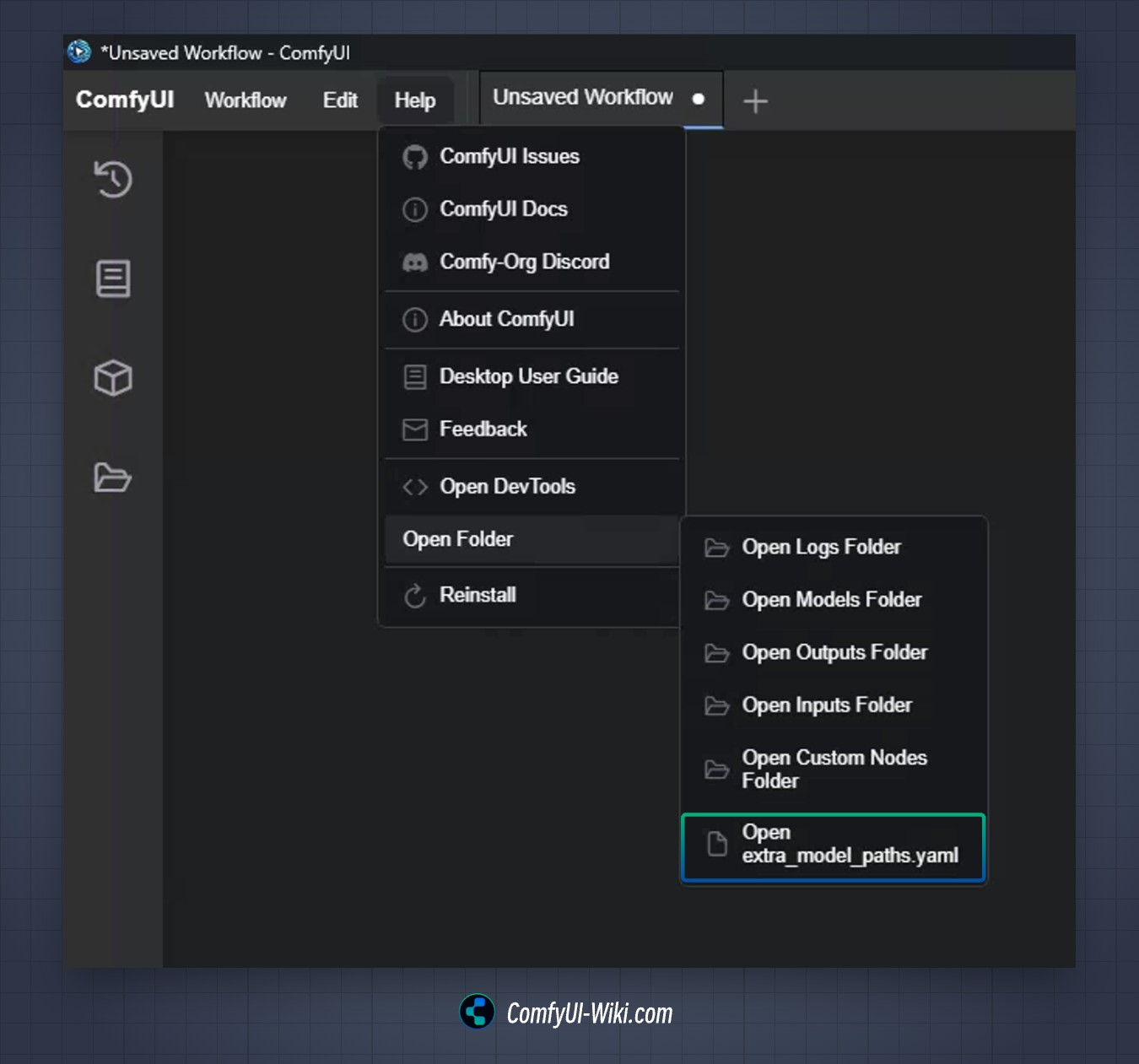
选择对应的菜单项,然后用记事本程序打开
建议复制一份备份然后对原始文件进行修改
对应原始文件内容示例如下:
# ComfyUI extra_model_paths.yaml for win32
comfyui_desktop:
is_default: "true"
checkpoints: models\checkpoints\
classifiers: models\classifiers\
clip: models\clip\
clip_vision: models\clip_vision\
configs: models\configs\
controlnet: models\controlnet\
diffusers: models\diffusers\
diffusion_models: models\diffusion_models\
embeddings: models\embeddings\
gligen: models\gligen\
hypernetworks: models\hypernetworks\
loras: models\loras\
photomaker: models\photomaker\
style_models: models\style_models\
unet: models\unet\
upscale_models: models\upscale_models\
vae: models\vae\
vae_approx: models\vae_approx\
animatediff_models: models\animatediff_models\
animatediff_motion_lora: models\animatediff_motion_lora\
animatediff_video_formats: models\animatediff_video_formats\
ipadapter: models\ipadapter\
liveportrait: models\liveportrait\
insightface: models\insightface\
layerstyle: models\layerstyle\
LLM: models\LLM\
Joy_caption: models\Joy_caption\
sams: models\sams\
blip: models\blip\
CogVideo: models\CogVideo\
xlabs: models\xlabs\
instantid: models\instantid\
custom_nodes: custom_nodes/
download_model_base: models
base_path: D:\ComfyUI如何修改配置
下面是对于 yaml 文件的配置说明:
| 模型类型 | 配置键名 (必须,不能修改) | 默认相对路径(可以修改) |
|---|---|---|
| 是否默认配置 (只能有一个) | is_default | true/false |
| Checkpoint 模型 | checkpoints | models/checkpoints/ |
| LoRA 模型 | loras | models/loras/ |
| VAE 模型 | vae | models/vae/ |
| 控制网络 | controlnet | models/controlnet/ |
| 文本编码器 | clip | models/clip/ |
| 图像编码器 | clip_vision | models/clip_vision/ |
| 放大模型 | upscale_models | models/upscale_models/ |
| 嵌入模型 | embeddings | models/embeddings/ |
| 超网络 | hypernetworks | models/hypernetworks/ |
| 风格模型 | style_models | models/style_models/ |
| 照片制作器 | photomaker | models/photomaker/ |
| IP适配器 | ipadapter | models/ipadapter/ |
| 动画模型 | animatediff_models | models/animatediff_models/ |
| 动画LoRA | animatediff_motion_lora | models/animatediff_motion_lora/ |
| 分类器 | classifiers | models/classifiers/ |
| 生成模型 | diffusers | models/diffusers/ |
| 自定义节点 | custom_nodes | custom_nodes/ |
| 下载模型基础 | download_model_base | models/ |
| 基础路径(必须) | base_path | D:/ComfyUI |
请注意,对应的表格只是说明可能的模型类型保存文件夹位置,并不是所有的模型文件都要按这个表格的位置来进行保存,对于模型保存位置,你需要参考对应具体的教程或者自定义节点的说明。 因为不同自定义节点的作者可能会偏好使用不同的模型存放位置!
如果下面是我提供的自定义的模型配置文件示例
comfyui_desktop:
is_default: "true"
checkpoints: models\checkpoints\
classifiers: models\classifiers\
clip: models\clip\
clip_vision: models\clip_vision\
configs: models\configs\
controlnet: models\controlnet\
diffusers: models\diffusers\
diffusion_models: models\diffusion_models\
embeddings: models\embeddings\
gligen: models\gligen\
hypernetworks: models\hypernetworks\
loras: models\loras\
photomaker: models\photomaker\
style_models: models\style_models\
unet: models\unet\
upscale_models: models\upscale_models\
vae: models\vae\
vae_approx: models\vae_approx\
animatediff_models: models\animatediff_models\
animatediff_motion_lora: models\animatediff_motion_lora\
animatediff_video_formats: models\animatediff_video_formats\
ipadapter: models\ipadapter\
liveportrait: models\liveportrait\
insightface: models\insightface\
layerstyle: models\layerstyle\
LLM: models\LLM\
Joy_caption: models\Joy_caption\
sams: models\sams\
blip: models\blip\
CogVideo: models\CogVideo\
xlabs: models\xlabs\
instantid: models\instantid\
custom_nodes: custom_nodes/
download_model_base: models
base_path: D:\ComfyUI
custom_models:
base_path: E:\
checkpoints: models\checkpoints\
classifiers: models\classifiers\
clip: models\clip\
# ... 其他模型路径 ...
a1111:
base_path: D:\stable-diffusion-webui
checkpoints: models/Stable-diffusion
# ... 其他模型路径 ...base_path这个是在每个配置里面都是有新增自定义的- 每个配置节点的名称你可以自定义比如
custom_models或者a1111等等,但是不能重复,否则会报错 is_default这个是用来指定这个配置文件是否是默认的配置文件,只能有一个,如果设置为true,那么这个配置文件就会成为默认的配置文件,否则就会成为非默认的配置文件- 键名需要与原始的配置文件一致,文件夹为你实际的文件夹
- 请注意
custom_nodes这个文件夹是用来存放自定义的插件的路径的这是在原本Portable 便携版中没有的,在桌面版中是有的,最好保持默认
ComfyUI Portable 便携版如何配置与 A1111 共享绘图模型
在对应ComfyUI Portable的安装目录里都可以找到extra_model_paths.yaml.example 这个文件,路径如下
ComfyUI_windows_portable
├──ComfyUI
│ ├── extra_model_paths.yaml.example // 此文件为配置文件
│ └── ...省略其它文件
└── ...省略其它文件找到以上文件后修改文件名extra_model_paths.yaml.example 为extra_model_paths.yaml,然后用记事本软件进行编辑
对应原始文件内容如下:
#Rename this to extra_model_paths.yaml and ComfyUI will load it
#config for a1111 ui
#all you have to do is change the base_path to where yours is installed
a111:
base_path: path/to/stable-diffusion-webui/
checkpoints: models/Stable-diffusion
configs: models/Stable-diffusion
vae: models/VAE
loras: |
models/Lora
models/LyCORIS
upscale_models: |
models/ESRGAN
models/RealESRGAN
models/SwinIR
embeddings: embeddings
hypernetworks: models/hypernetworks
controlnet: models/ControlNet
#config for comfyui
#your base path should be either an existing comfy install or a central folder where you store all of your models, loras, etc.
#comfyui:
# base_path: path/to/comfyui/
# checkpoints: models/checkpoints/
# clip: models/clip/
# clip_vision: models/clip_vision/
# configs: models/configs/
# controlnet: models/controlnet/
# embeddings: models/embeddings/
# loras: models/loras/
# upscale_models: models/upscale_models/
# vae: models/vae/
#other_ui:
# base_path: path/to/ui
# checkpoints: models/checkpoints
# gligen: models/gligen
# custom_nodes: path/custom_nodes你可以看到在a111:的设置部分有 base_path: 用来指定 WebUI 根目录所在路径,你可以把此处修改为你的 WebUI 或者自定义的模型文件夹位置所在的路径,记得在: 后需要有一个空格,修改完成后保存对应文件,重启ComfyUI即可。
- 你需要确保在
base_path:路径之下的文件路径是正确的 - 注意在不同系统比如Mac 或者 Linux 系统下,路径的格式可能有所不同
- 如果假设WebUI安装路径为
D:\stable-diffusion-webui\则vae在上方配置文件设置下对应路径vae 模型文件路径最终会是应该为D:\stable-diffusion-webui\models\VAE,请检查对应文件夹其它类似checkpoints、loras,也请检查对应的配置。
如果你重启以后发现你的checkpoints或者 VAE等没有顺利加载,请检查你的配置是否正确。
对于其它UI 你也可以参考上方配置文件进行修改,比如other_ui:等,你可以取消代码前的#注释来增加对应UI的设置,然后修改base_path:和对应各类绘图模型的路径即可
要如何对 ComfyUI 进行升级?
本文将讲解如何升级 ComfyUI 的版本,由于不同的安装方式升级的方法也有所差异,本文不一定会覆盖到所有的升级方法
本篇讲解将涉及以下几种升级ComfyUI的方法:
- windows 使用 ComfyUI 官方便携版本的用户如何升级更新 ComfyUI
- 手动安装 ComfyUI 的用户如何通过 Git 升级更新 ComfyUI 版本
- 使用 秋叶启动器 的用户如何升级更新 ComfyUI 版本
- 如果你安装了 ComfyUI Manager 则你可以通过 ComfyUI Manager 来升级更新 ComfyUI
- ComfyUI Desktop ,目前 ComfyUI Desktop 的版本是采用自动更新的,正常情况下检测到有新版本会自动提示更新,或者你可以访问 ComfyUI Desktop 的 Github 仓库 查看最新版本
- 如何单独更新 ComfyUI 的 Web 前端
由于 1、2、4 几个方法都是需要访问的 Github 仓库,如果你所在的地区无法顺利访问 Github 可能会导致无法更新成功,你可能需要设置一下网络代理以更新对应服务,这里还是比较推荐中国国内的 Windows 用户使用秋叶启动器来管理,会省心很多。
Windows 使用 ComfyUI 官便版本的用户如何升级更新 ComfyUI
- 打开 ComfyUI 的安装目录,找到
你的安装目录\ComfyUI_windows_portable\update\update_comfyui.bat文件 - 双击运行
update_comfyui.bat文件,等待更新完成 - 更新完成后,重新启动 ComfyUI 即可
同样对应的依赖和环境升级可以通过同样的方式来进行维护。
手动安装 ComfyUI 的用户如何通过 Git 升级更新 ComfyUI 版本
首先确保你的电脑已经是安装了 Git 并且你的ComfyUI 也是通过 Git 安装的代码
- 打开命令行工具,使用
cd 你的安装目录\ComfyUI进入 ComfyUI 的安装目录 - 运行以下命令,拉取最新ComfyUI的代码
这样你可以拉取最新的对应 ComfyUI 的代码,如果你想要切换不同的 ComfyUI 的更新版本,你可以使用
来查看对应仓库的更新历史,会显示如下
对应 commit 之后的 字符串即为 git 版本的哈希值,然后你可以使用
git reset --soft <commit-hash>来软重置到特定的版本,如
git reset --soft 153d0a8142d14c6c0d71eb0ba98d3e09c7e7abea当然,通常情况下如果运行不存在问题,使用最新版本应该就可以
在版本更新后通常可能 ComfyUI 的相应依赖也可能有变化,特别是 ComfyUI 的前端(comfyui-frontend-package)目前是采用单独的包来管理的,所以建议你在对应的 ComfyUI 的虚拟环境下运行 pip 来更新对应的包
pip install -r requirements.txt使用 秋叶启动器 的用户如何升级更新 ComfyUI 版本
- 打开秋叶启动器,点击
版本管理选项 - 在
内核选项卡,你可以看到最新的 ComfyUI 版本和日期 - 选择你想要切换到的版本,进行切换(Switch)即可
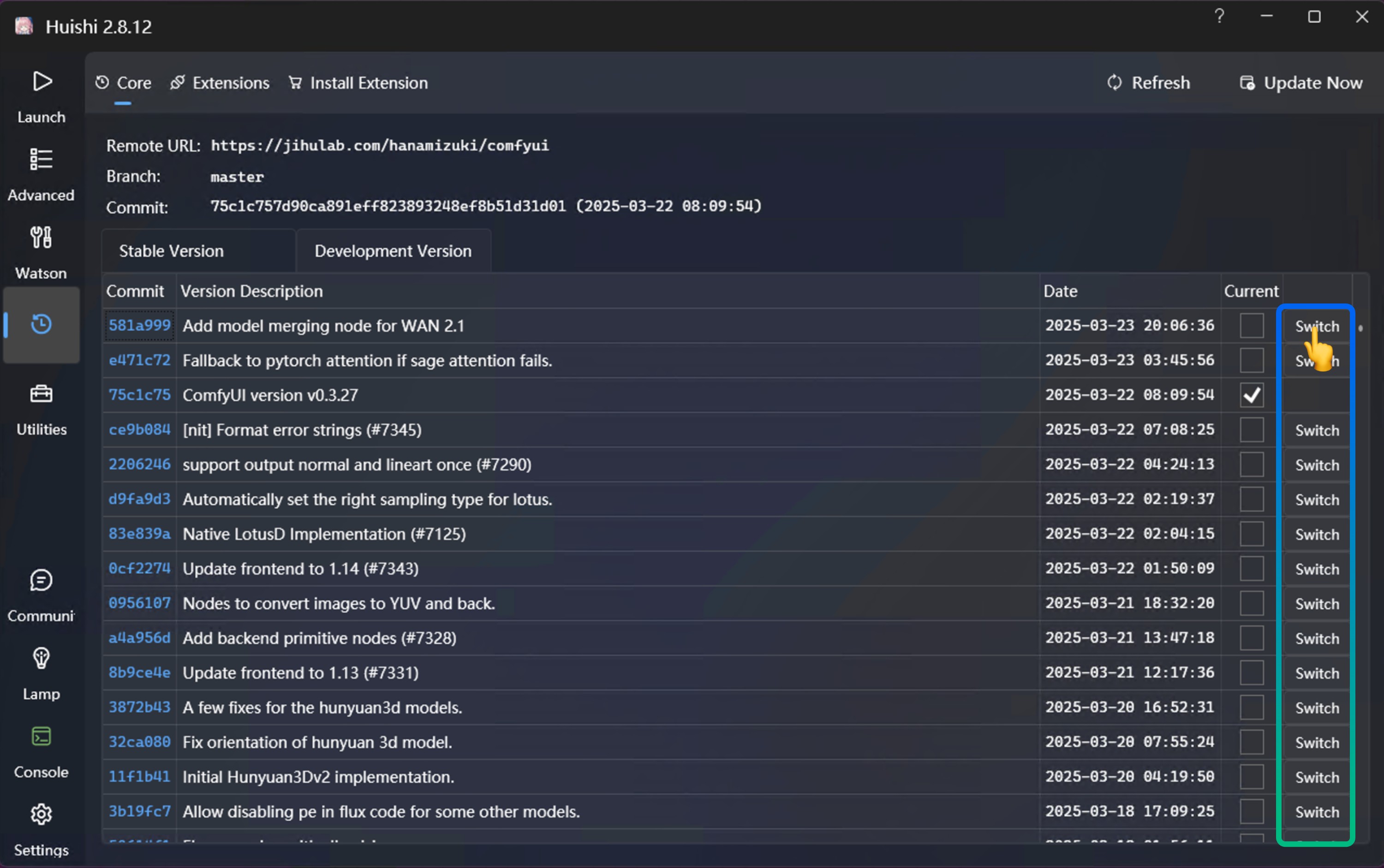
秋叶启动器会在你切换版本后自动更新 ComfyUI 的依赖。
ComfyUI Manager 用户
ComfyUI Manager 插件内置了更新功能,你只需要在 插件管理 选项卡中找到 ComfyUI Manager 插件,点击 update comfyui ,如果一切顺利,运行完成之后重启 ComfyUI 即可。
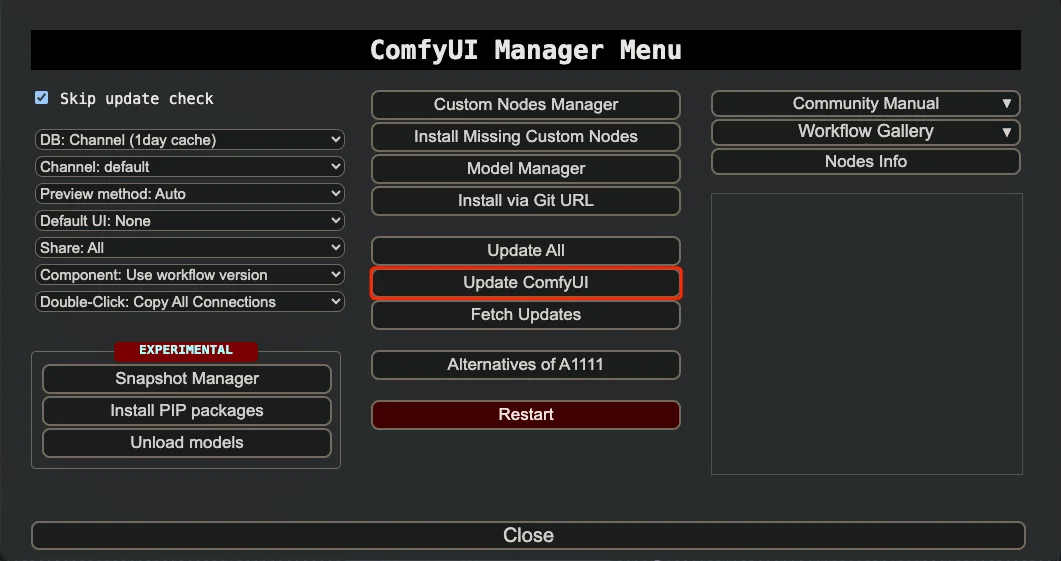
如何升级 ComfyUI 的 Web 前端
目前 ComfyUI 的 Web 前端是使用 comfyui-frontend-package 这个包来管理的,你可以在 这里 查看对应包的更新历史,
对应的版本要求会在ComfyUI/requirements.txt文件中体现,ComfyUI 不一定会使用最新版本的 comfyui-frontend-package,所以如果你想要使用最新版本的 comfyui-frontend-package,你需要手动更新
pip install comfyui-frontend-package --upgrade这样你就可以更新到最新的 ComfyUI 的 Web 前端了,或者使用版本号来更新到特定版本
pip install comfyui-frontend-package==<version>如果你使用的是 ComfyUI Portable 版本,你只需要在 ComfyUI_windows_portable\ 目录下打开命令行,然后运行以下命令
python_embeded\python.exe -m pip install comfyui-frontend-package --upgrade或者,使用版本号来更新到特定版本
python_embeded\python.exe -m pip install comfyui-frontend-package==<version>如果你在中国国内,如果遇到网络问题,可以尝试使用国内镜像来安装,比如添加 -i https://pypi.tuna.tsinghua.edu.cn/simple 参数来使用清华大学镜像
python_embeded\python.exe -m pip install comfyui-frontend-package --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple如何在 ComfyUI 中安装各类型模型
本部分提供了在 ComfyUI 中安装各种模型的综合指南。包括 Stable Diffusion 检查点、LoRA 模型、嵌入、VAE、ControlNet 模型等。
当然通常这部分并不麻烦,你只需要将对应的模型保存到 ComfyUI/models 文件夹下的对应文件夹即可,但如果你遇到了问题,可以尝试查阅下面的文章,不过请放心,我会在对应不同部分的教程说明里补充说明模型安装的位置,所以请不用特别阅读次部分教程
ComfyUI提示词基础语法tips
本文将简要介绍 ComfyUI 中一些简单的Prompt 书写要求和规则,以及 ComfyUI 中支持的特殊语法类似注释等等
第一部分:提示词书写的基础规则
英文书写
提示词必须采用英文书写,因为CLIP模型是基于英文数据集进行训练的。
词组使用
建议使用词组而非完整的句子,并用英文逗号分隔不同的词组,以便于管理和调整权重。
注释支持
Comfy UI支持使用注释,可以通过双斜线(//)进行单行注释,或者使用多行注释(/* ... */)。
权重管理
提示词的权重可以通过其在提示词列表中的位置来管理,越靠前的词组权重越高,越容易在生成的图像中体现。
第二部分:Comfy UI提示词的权重规则和语法
权重表达
在Comfy UI中,可以通过括号加权重的方式来对提示词进行加权,例如 (提示词:1.5) 表示该词组的权重是正常权重的1.5倍。建议正常在0.5~1.5左右。
快速权重调整
用户可以通过选中关键词并使用 Ctrl加方向键上或下,来快速调整权重。
降权方法
webUI中用中括号([])用于降低某个词组的权重,但在Comfy UI中的效果可能不如预期。
随机生成
大括号 {提示词|提示词|提示词} 的方式可以实现随机抽取内容进行生成,但是生成的图像同时也会增加随机性。
第三部分:提示词书写建议及辅助工具推荐
3.1 提示词结构化书写规则
- 主体(Subject)
- 特点(Features)
- 环境背景(Environment/Background)
- 风格(Style)
- 修饰词(Modifiers)
3.2 提示词抄作业网站推荐
下面是一些在线的 AI 绘图社区,如果你不擅长写提示词,可以尝试访问这些网站,获取灵感
或者更简单的一个方式是使用类似 ChatGPT 这样的 AI 工具,直接告诉它你想要什么,让 AI 帮你完成提示词的书写,如: “我正在使用 SD1.5 进行图片生成,我需要你帮我生成一个宇航员在太空行走背景满是星空的提示词,包括正向和负向提示词”
3.3 提示词书写辅助网站推荐
- AI辅助生成提示词:
- 提示词可视化:
- Danbooru 标签超市(使用体验最佳)
- PromptoMANIA
- PromLib
第四部分:提示词增强插件推荐
4.1 ComfyUI-Custom-Scripts
这个插件提供多种功能增强,包括提示词辅助,以提高用户在使用Comfy UI时的体验。
更多信息请访问:GitHub - pythongosssss/ComfyUI-Custom-Scripts
4.2 ComfyUI ArtGallery
这个插件提供了风格提示词的可视化预览,帮助用户更好地理解和选择适合的提示词风格。
更多信息请访问:GitHub - ZHO-ZHO-ZHO/ComfyUI-ArtGallery
作者B站视频:提示词可视化|ComfyUI ArtGallery|艺术画廊|Stable Diffusion
4.3 comfyui-prompt-composer
这个工具提供了提示词的组织节点化管理,帮助用户更有效地管理和组合提示词。
ComfyUI 局部重绘工作流示例
图像局部重绘是指对图像中你需要修改的部分进行修改,而不影响其他部分,如:
- 清除画面中的物体
- 修改人物的部分细节(表情、服饰)
- 修改衣物颜色 等等
这些都可以通过 图像局部重绘 来实现,但本篇是一个较为基础的局部重绘工作流,在ComfyUI 官方局部重绘工作流示例 你可以找到官方使用VAE内补编码器进行局部重绘的示例。 但这本篇教程里,我将使用设置Latent噪波遮罩来完成局部重绘的示例。
本篇教程主要示例是修改图像中人物的眼睛颜色和表情。

开始局部重绘工作流前的准备(可选)
这个工作流将会使用到以下模型,但不是必须的,除非你的电脑上没有对应SD1.5模型:
| 模型类型 | 模型名称 | 下载链接 | 说明 |
|---|---|---|---|
| SD1.5 模型 | DreamShaper v8 | 前往下载 | SD1.5模型的基础模型 |
下载后请将这个模型文件保存在以下目录:
局部重绘工作流素材
请下载下面的图片和并点击按钮下载工作流文件

局部重绘工作流讲解
打开 ComfyUI 后将工作流文件拖入 ComfyUI 中,或者使用菜单打开工作流文件来加载
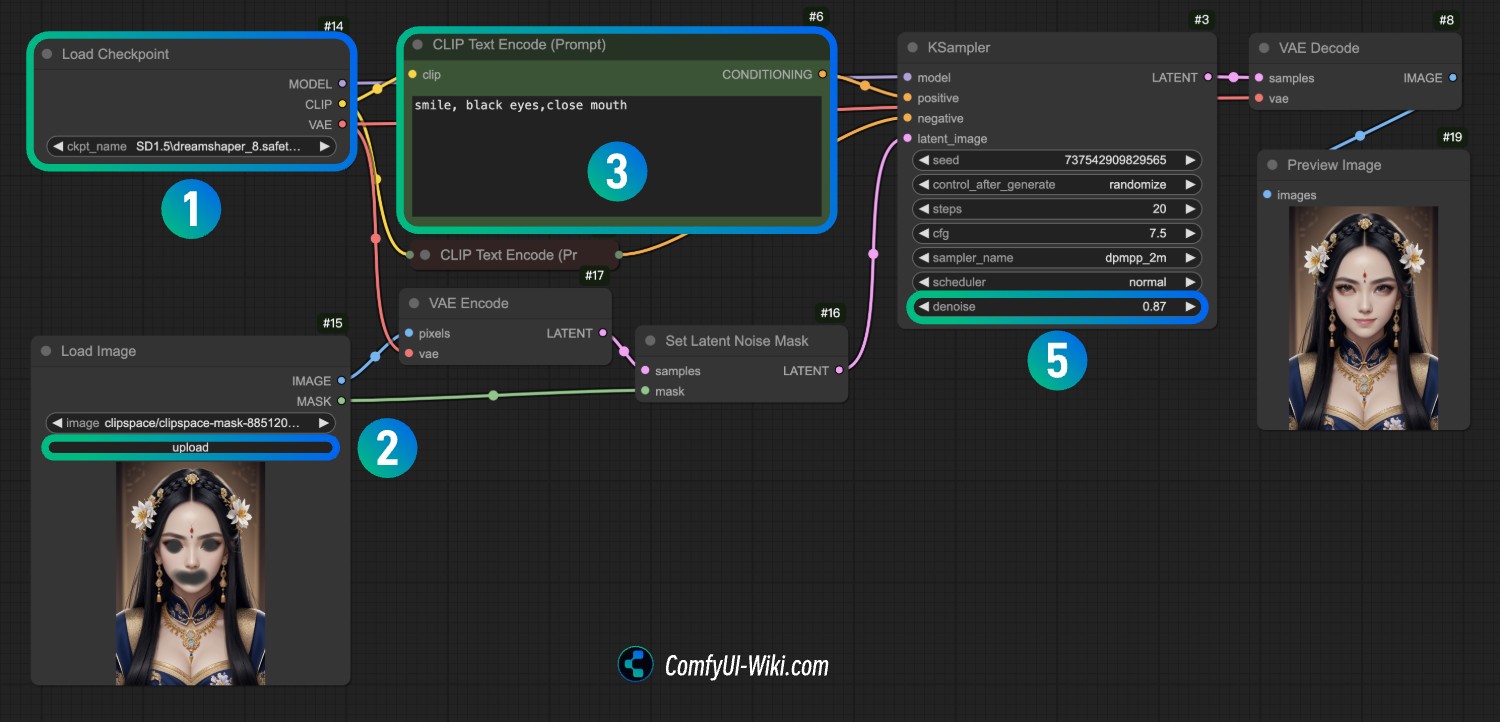
- 请在序号
1处加载DreamShaper v8模型,或者那你电脑上的其它类型的模型 - 请在序号
2处Load Image加载在上一个步骤提供的图片
在 绘制需要重绘的部分的蒙版,具体完整的绘制模板的方法请参考遮罩编辑器的使用方法。
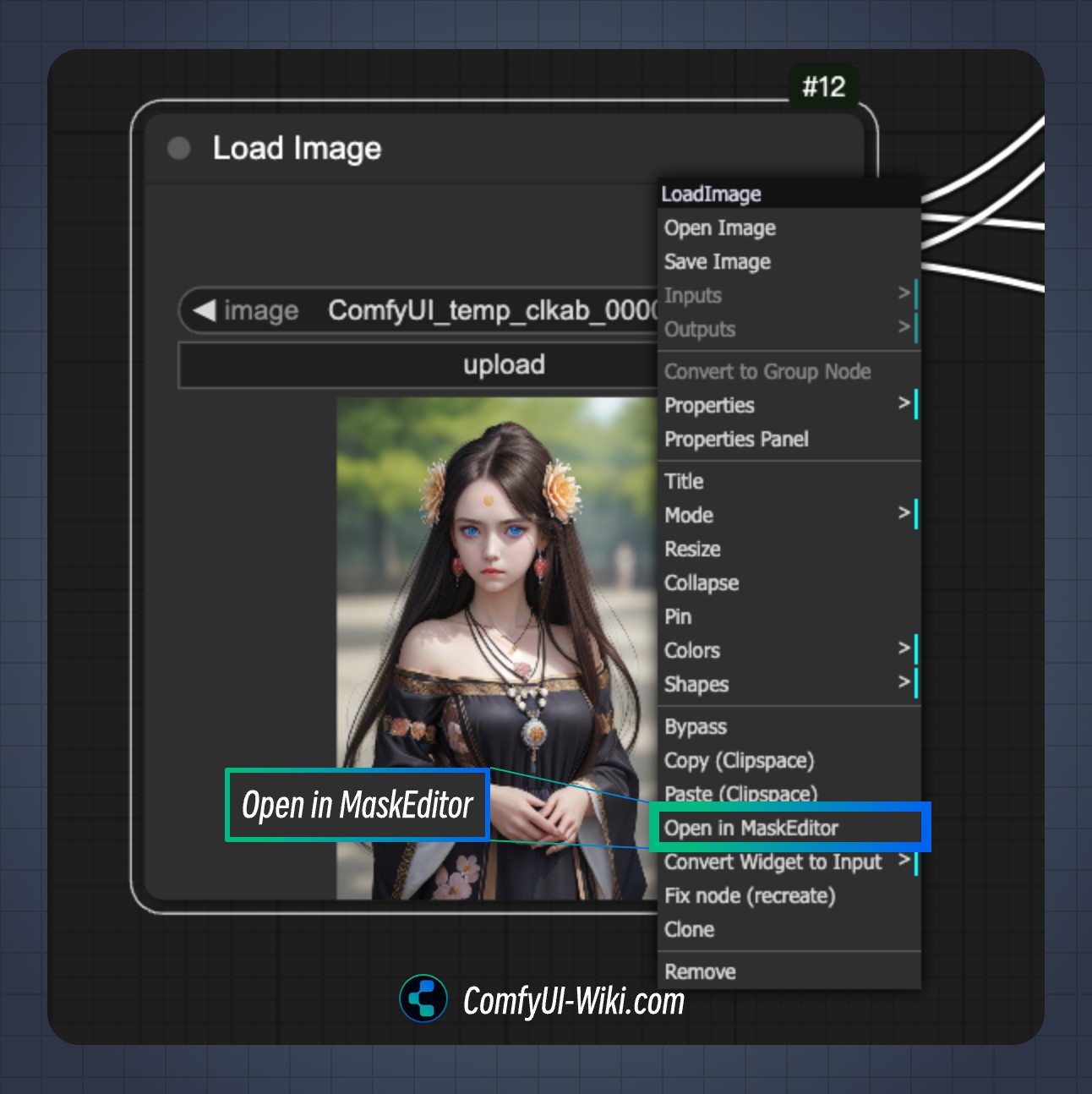
-
修改序号
3处 CLIP Text Encode的文本,在我的工作流中是smile, black eyes,close mouth你可以修改为你想要的画面内容 -
使用 Queue 或者快捷键
Ctrl(Command)+Enter运行工作流进行图片生成,可能需要经历几次重新生成才会有满意的效果
你可以接着试着优化尝试使用下面的正向提示词和负向提示词,查看对比不同的生成效果 正向提示词( Positive):
负向提示词( Negative):
- 试着调整不同的
denoise参数,查看不同的生成效果,先从一个比较小的值比如 0.1 开始
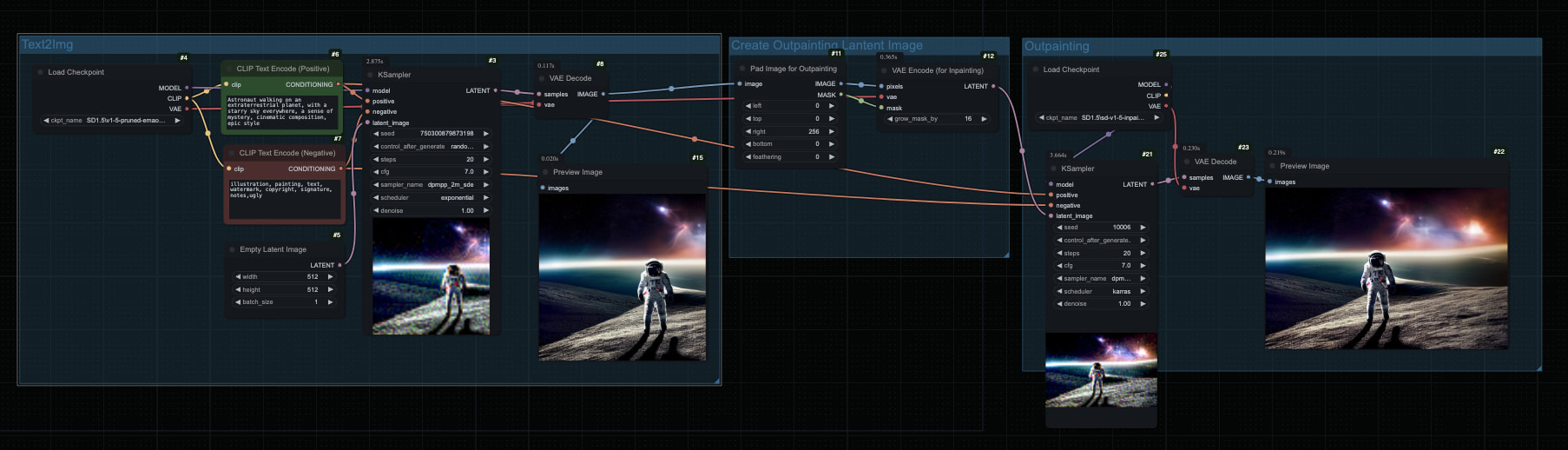
ComfyUI 基础扩图工作流以及教程
扩图(Outpainting)是指在原始图片的边缘区域继续生成内容,从而扩展图片的尺寸。这种技术可以让我们:
- 扩展图片的视野范围
- 补充画面缺失的部分
- 调整图片的宽高比例
扩图的原理是基于 Stable Diffusion 的 inpainting 技术,通过在图片的边缘区域添加空白区域,然后使用 inpainting 模型对空白区域进行填充,从而实现图片的扩展。
ComfyUI 扩图教程相关文件下载
ComfyUI工作流文件
下载后将工作流文件拖入 ComfyUI 即可使用
Stable Diffusion 模型文件
本工作流需要使用两个模型,你使用其它模型也可以:
| 模型名称 | 用途 | 仓库地址 | 下载地址 |
|---|---|---|---|
v1-5-pruned-emaonly.safetensors | 生成初始图像 | 仓库地址 | 下载地址 |
sd-v1-5-inpainting.ckpt | 扩图 | 仓库地址 | 下载地址 |
下载后请将这两个模型文件放置在以下目录:
Path-to-your-ComfyUI/models/checkpoints
如果你想要了解更多:如何安装 Checkpoints 模型 如果你要查找使用其它模型:Stable Diffusion 模型资源
ComfyUI 基础扩图工作流使用方式
由于模型安装位置可能不同,请找到工作流中的 Load Checkpoint,然后在模型下拉菜单中选择你下载的模型文件。
- 第一个节点选择
v1-5-pruned-emaonly.safetensors - 第二个节点选择
sd-v1-5-inpainting.ckpt
因为第二个节点是专门用于扩图的模型,所以使用用于inpainting 的模型效果会更好,你可以自己测试不同的设置。
ComfyUI 基础扩图工作流简单讲解
这个工作流分为三个主要部分:
1. Text2Img 部分
首先生成一张初始图片:
- 使用
EmptyLatentImage设置 512x512 的画布 - 通过
CLIPTextEncode设置正面提示词和负面提示词 - 使用
KSampler生成初始图像
2. 创建扩图用的 Latent Image
- 使用
ImagePadForOutpaint节点在原图周围添加空白区域 - 节点的参数设置决定了要在哪个方向扩展图片
- 同时会生成对应的 mask 用于后续的扩图
3. 扩图生成
- 使用专门的 inpainting 模型进行扩图
- 保持和原图相同的提示词,确保风格统一
- 通过
KSampler对扩展区域进行生成
使用说明
-
调整扩展区域:
- 在
ImagePadForOutpaint节点中设置四个方向的扩展像素值 - 数值代表要在该方向扩展的像素数量
- 在
-
提示词设置:
- 正面提示词描述你想要的场景和风格
- 负面提示词帮助避免不想要的元素出现
-
模型选择:
- 第一阶段使用普通的 SD 模型
- 扩图阶段推荐使用 inpainting 专用模型
ComfyUI 基础扩图工作流注意事项
-
扩图时尽量保持提示词的连贯性,这样可以让扩展区域和原图更好地融合
-
如果扩展效果不理想,可以:
- 调整采样步数和 CFG Scale
- 尝试不同的采样器
- 微调提示词
-
扩图模型推荐使用:
- sd-v1-5-inpainting.ckpt
- 其他专门的 inpainting 模型
ComfyUI 基础扩图工作流结构
工作流主要包含以下节点:
- CheckpointLoaderSimple: 加载模型
- CLIPTextEncode: 处理提示词
- EmptyLatentImage: 创建画布
- KSampler: 图像生成
- ImagePadForOutpaint: 创建扩图区域
- VAEEncode/VAEDecode: 编码解码图像
在 ComfyUI 对图片进行放大的不同方法及详细教程
本篇里 ComfyUI Wiki将讲解 ComfyUI 中几种基础的放大图片的办法,我们时常会因为设备性能问题,不能一次性生成大尺寸的图片,通常会先生成小尺寸的图像然后再进行放大。
不同的放大图片方法有不同的特点,以下是本篇教程将会涉及的方法:
- 像素重新采样
- SD 二次采样放大
- 使用放大模型放大图片
在 ComfyUI 中使用像素采样放大图片
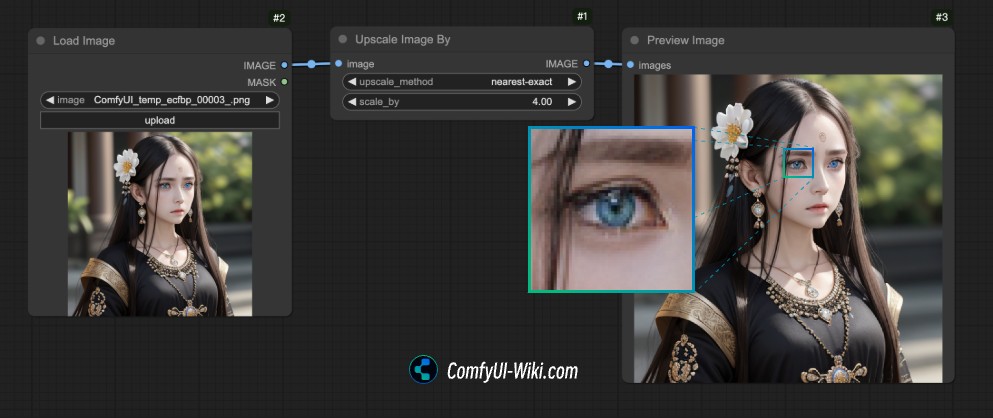 如图所示,通过Upscale Image By 节点是可以直接将输入图片通过不同的像素采样的方式来进行放大的,特点如下:
如图所示,通过Upscale Image By 节点是可以直接将输入图片通过不同的像素采样的方式来进行放大的,特点如下:
- 和原图内容一致,画面元素不会变化
- 放大后容易存在马赛克,缺少细节
在 ComfyUI 中通过图像二次采样放大
- 这种放大方式主要是将图片输入到这个潜空间中,然后再重新进行一个潜空间采样的一个过程
- 这种方法生成的图片在细节上会与原图会有些许的不同,会有图像元素的变化
- 使用这种方式的核心在于不要将k-Sampler的降噪(denoise)设置为1,如果你把降噪设为1,那么图片将会完全变为噪声输入潜空间,导致输出图片完全与原始图片没有关联
在下面的这个例子中,我将给出不同的这个使用方式
开始前的准备(可选)
这个工作流将会使用到以下模型,但不是必须的,除非你的电脑上没有对应模型:
| 模型类型 | 模型名称 | 下载链接 | 说明 |
|---|---|---|---|
| SD1.5 模型 | DreamShaper v8 | 前往下载 | SD1.5模型的基础模型 |
下载后请将这个模型文件保存在以下目录:
1. 图片直接二次采样放大
请下载下面的图片和工作流文件,然后在 ComfyUI 中打开

对应工作流使用及讲解:
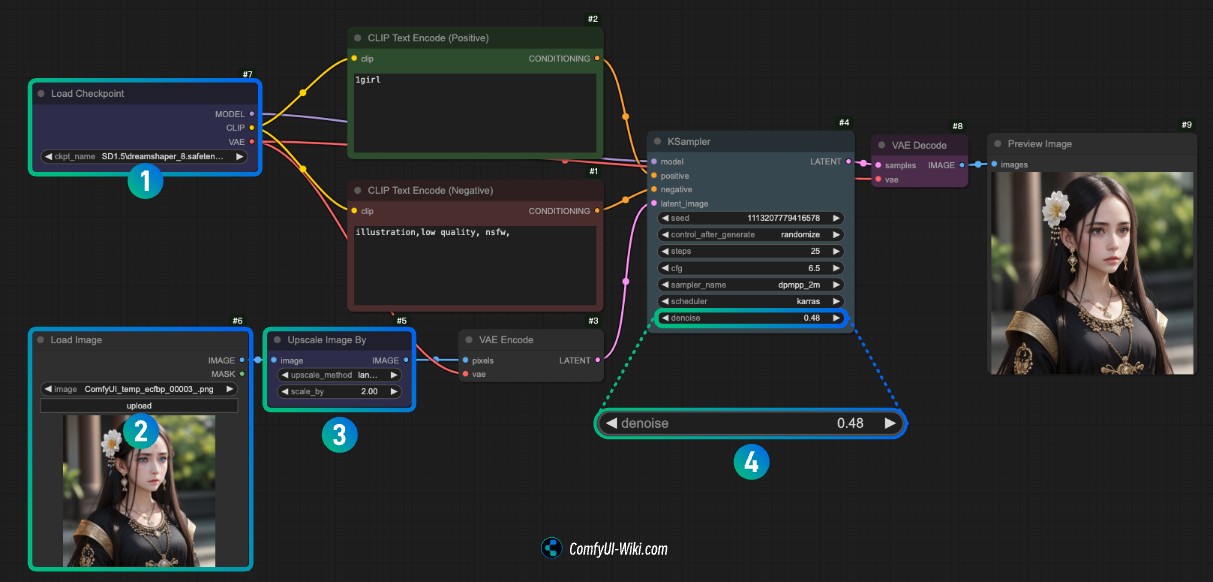
- 请在序号
1处加载你电脑上的模型,或者使用dreamshaper_8 - 请在序号
2的 Load Image 处点击upload上传刚才的图片
完成这两步,你可以使用 Ctrl(Command)+enter 或者点击 Run 进行图像放大了,你可以看到在提示词输入我设置得非常简单采用了1 girl 但依旧得到了处理后的图像
- 在Upscale Image By 这里设置了图像放大2倍
- 在k-Sampler 处需要注意需要将
denoise设置为一个较小的值,你可以尝试不同大小的值来观察效果
2. 从文生图流程结果直接放大
下面的这个工作流是直接从文生图工作流的结果直接输出然后进行放大
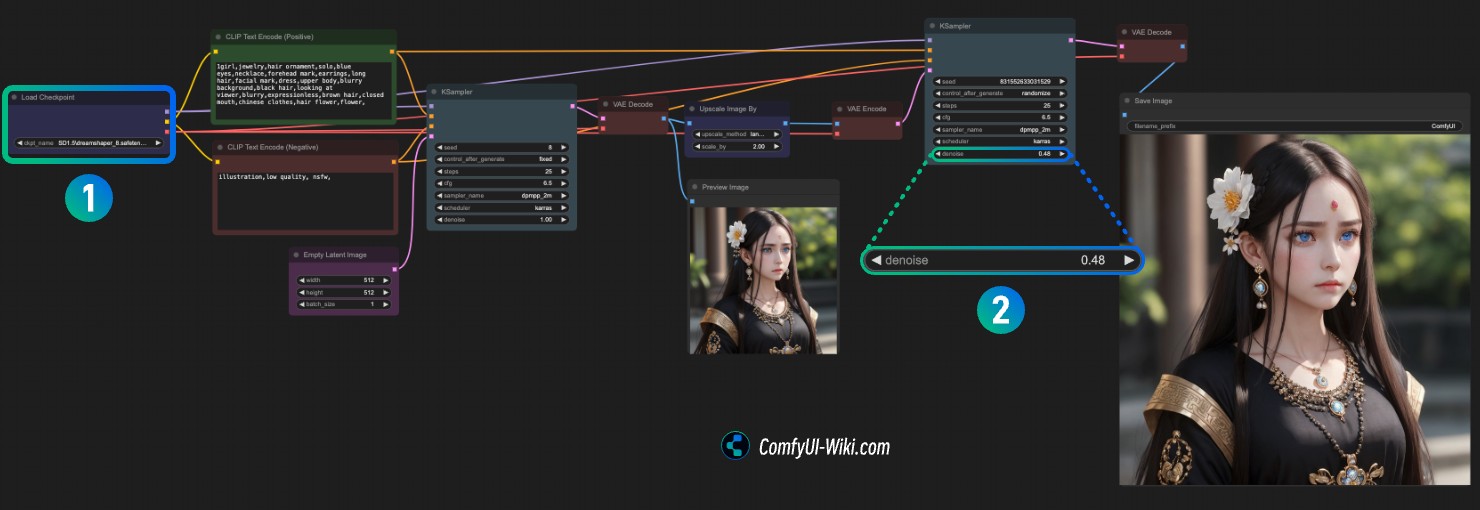
- 请在序号
1处加载你电脑上的模型,或者使用dreamshaper_8然后就可以使用Ctrl(Command)+enter来进行图片生成 - 在第二个 k-Sampler 处依旧是将
denoise设置为一个较小的值
在 ComfyUI 中使用放大模型放大图片
ComfyUI 中提供了Upscale Image(using Model) 节点
- 速度会比图像重新采样放大快
- 细节上可能不如重新采样生成图片的方法
开始前的准备
你可以在 https://openmodeldb.info/ 找到各种用于照片、人物、动画等的放大模型,通常对应对应模型都有注明具体放大的倍数,请访问对应网站并下载符合你使用场景的模型
对应放大模型请保存到下面的文件夹位置:
完成后刷新或者重启 ComfyUI 保证模型可以被检测到
ComfyUI 图片放大够工作流
具体使用放大模型的工作流如下,由于较为简单就不另外提供工作流文件
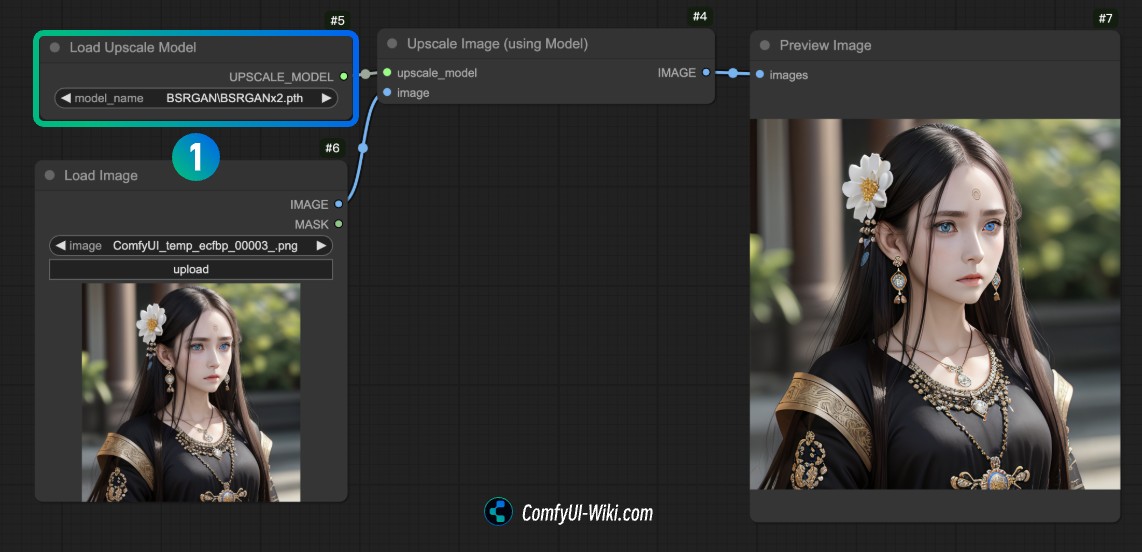
在序号1处 Load Upscale Model节点请加载你下载到的对应模型,然后使用 Ctrl(Command)+enter 或者点击 Run 进行图像生成
使用插件进行图像放大
有一些插件提供了分区采样放大的功能,但由于篇幅所限就不在此进行扩展,主要为以下两个插件:
- ComfyUI_TiledKSampler : https://github.com/BlenderNeko/ComfyUI_TiledKSampler
- ComfyUI_UltimateSDUpscale:https://github.com/ssitu/ComfyUI_UltimateSDUpscale
可以参考下面的视频教程(中文):https://www.bilibili.com/video/BV19y41187zC
在 ComfyUI 中使用 Embedding 模型
在一些模型站上,我们可以看到embedding模型,它能够输出特定的风格。例如,它可以生成平面风格的图像,或者使画面中的人物具备某些特征,甚至让整个画面呈现特定的艺术风格。此外,embedding模型的体积通常很小,只有几KB。
你可以把它简单理解为一个提示词(prompt)的压缩包,原本你需要很复杂的文本描述才可以达到的效果,通过 Embedding 模型都可以轻易做到,再加上他的体积很小,所以使用起来非常方便
所以 Embedding 模型的使用也是在 文本编码器 clip text encode 这个节点中使用。 本文将指导你去哪里下载、安装和具体的使用示例
到哪里下载embedding模型?
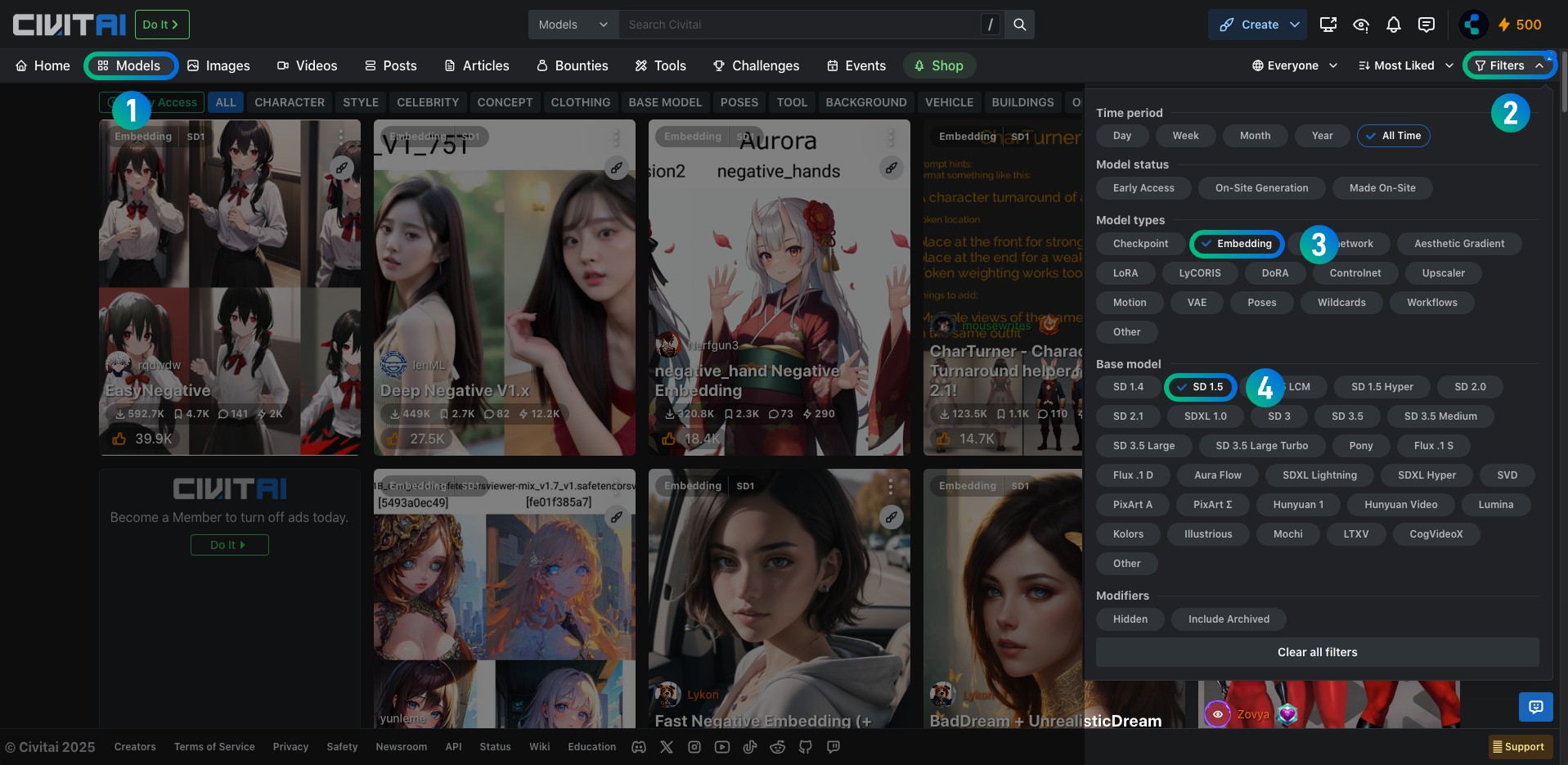
这些都是常用的可以下载embedding模型的网站,通常在对应的模型页面中,使用筛选,选择 embedding 或者 Textual Inversion 就可以筛选出对应的模型
如下图,对应的截图筛选了出了 SD1.5 模型所使用的 embedding 模型
如何安装 embedding模型?
实际示例讲解
下面我将以 EasyNegative 模型为例,讲解如何在 ComfyUI 中使用 embedding 模型
1. 相关模型下载与安装
| 模型类型 | 模型名称 | 下载链接 | 说明 |
|---|---|---|---|
| SD1.5 模型 | DreamShaper v8 | 前往下载 | SD1.5模型的基础模型 |
| embedding 模型 | EasyNegative | 下载地址 | 请注意对应页面的使用说明,通常作者会对模型使用方法进行详细说明 |
以上模型可以在相应的链接中下载,确保遵循使用说明以获得最佳效果。
在你的ComfyUI目录下,确保有以下文件夹结构:
- 下载到的 EasyNegative 模型放入
models/embeddings/SD1.5文件夹 - 重启或刷新 ComfyUI 界面,让 ComfyUI 识别新增的模型
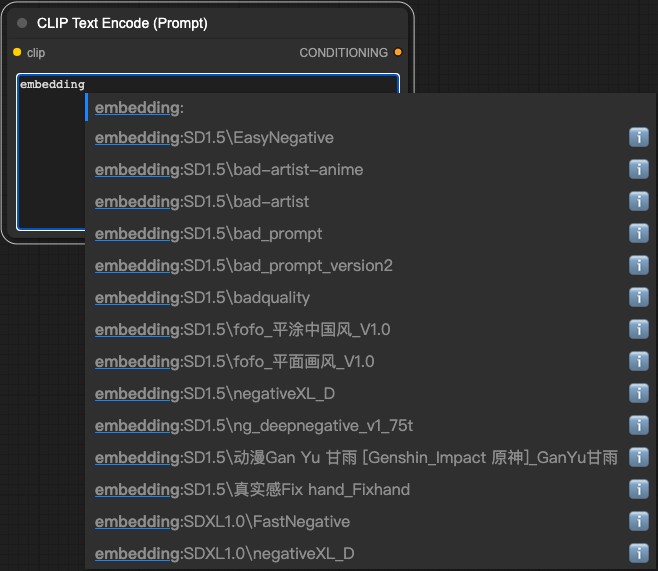
插件安装(可选): ComfyUI-Custom-Scripts
这个插件可以让你在文本编码器中输入 embedding 模型名称,然后自动帮你生成对应的 embedding 模型,对应安装教程参考ComfyUI 里要如何安装 Custom Nodes
2. 载入 Embedding 工作流文件
下载上面的文件,拖入 ComfyUI 界面或者使用菜单打开即可
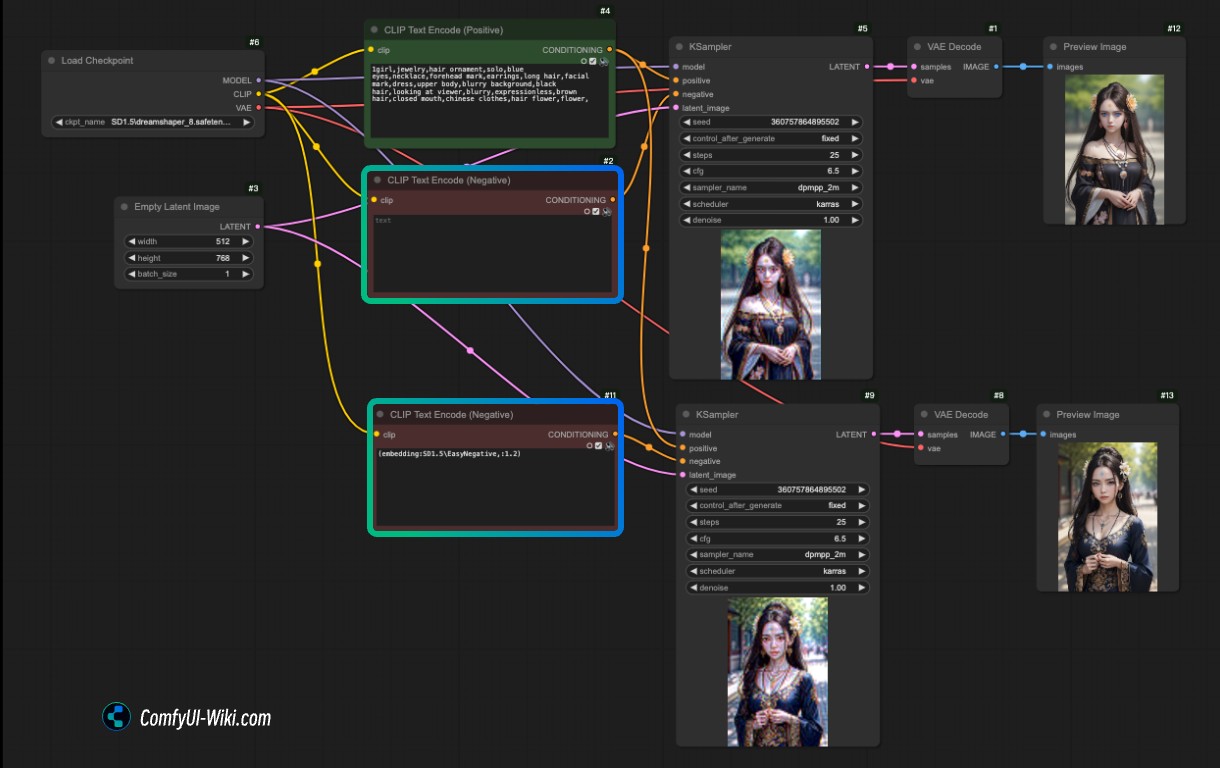
相关说明: 对应工作流里有两个生成图片的流程,唯一差异在于上面的流程负向提示词没有使用任何内容输入,而下面的流程负向提示词使用了 EasyNegative 模型输入了(embedding:SD1.5\EasyNegative,:1.2)
embedding 模型可以像正常的提示词一样,使用 ComfyUI 中的增加提示词的方法来增加权重
相关文章
要如何安装embedding模型 Embedding 模型资源
ComfyUI中的 LoRA 入门 - 从基础使用到多模型应用

LoRA 是什么?在AI绘图中 LoRA 是一种文件体积小、使用灵活的模型,你可以简单把它理解成“滤镜”,它可以让你的图片具有特定的风格、内容、细节等。
- 使画面具有特定的画风(如水墨画)
- 使人物具有某类人物的特征(如某些游戏角色)
- 使画面具有特定的细节 以上这些都可以通过LoRA来实现。
本篇教程提供了 ComfyUI 中使用多LoRA模型的基础教程,使用 SD1.5 模型,核心的节点是 LoRA Loader 节点,它负责加载 LoRA 模型。
准备工作
第一步:下载本篇教程所使用到的模型
如果你的电脑里面有其他的相关模型,那你可以跳过这一步,如果没有,那你可以下载本篇教程所使用到的模型
| 模型类型 | 模型名称 | 下载链接 |
|---|---|---|
| SD1.5 模型 | DreamShaper v8 | 前往下载 |
| LoRA模型 | 墨心/MoXin | 前往下载 |
| LoRA模型 | 清漪/QingYi | 前往下载 |
在你的ComfyUI目录下,确保有以下文件夹结构:
- 将DreamShaper模型放入
models/checkpoints/SD1.5文件夹 - 将MoXin和QingYi的LoRA文件放入
models/loras/SD1.5文件夹
第二步:重启ComfyUI
安装完成后重启或刷新ComfyUI,让 ComfyUI 识别新增的模型
第三步:下载工作流文件并导入 ComfyUI
工作流文件说明
在对应的这个文件里面,我提供了三个工作流,分别是:
- 基础模型
- 基础模型 + 墨心LoRA(权重1.0)
- 基础模型 + 墨心LoRA(权重0.2) + 清漪LoRA(权重0.1)
他们全部采用了统一的这个种子,保证变量是一致的用于对比应用 LoRA 前后的这个效果,你可以试着修改不同的这个权重来对比效果
其它相关内容
ComfyUI 加载 LoRA 节点功能说明 ComfyUI 中要如何安装 LoRA 模型